





前言:最近在研究代理模型,涉及到Kriging模型的实现,通过查阅相关网站找到了一个Kriging算法的实现方式
介绍
- Kriging在理解稀疏数据的方面是非常有价值的工具
- 事实证明,其在工程和数据昂贵、难以收集的领域,具有较强的应用价值
要理解kriging算法背后的数学原理,请参考下列资源:
https://link.springer.com/article/10.1023/A:1012771025575link.springer.com https://www.amazon.com/Engineering-Design-via-Surrogate-Modelling/dp/0470060689/ref=sr_1_3?ie=UTF8&qid=1421609474&sr=8-3&keywords=Surrogate+Modelwww.amazon.comPykriging工具箱的目的是使得Kriging法在Python中更易于使用。
安装方式
pip 使用pyKriging
pyKriging的目的旨在简化代理模型的创建过程。下列例子演示了如何创建抽样计划、在这些位置评估测试函数、创建和训练一个Kriging模型、并且添加点来减少模型的均方根误差。
import pyKriging
from pyKriging.krige import kriging
from pyKriging.samplingplan import samplingplan
# The Kriging model starts by defining a sampling plan, we use an optimal Latin Hypercube here
sp = samplingplan(2)
X = sp.optimallhc(20)
# Next, we define the problem we would like to solve
testfun = pyKriging.testfunctions().branin
y = testfun(X)
# Now that we have our initial data, we can create an instance of a Kriging model
k = kriging(X, y, testfunction=testfun, name='simple')
k.train()
# Now, five infill points are added. Note that the model is re-trained after each point is added
numiter = 5
for i in range(numiter):
print 'Infill iteration {0} of {1}....'.format(i + 1, numiter)
newpoints = k.infill(1)
for point in newpoints:
k.addPoint(point, testfun(point)[0])
k.train()
# And plot the results
k.plot()该脚本将产生以下输出,由于pyKriging广泛使用随机优化来构建模型,因此您的模型输出可能会略有不同
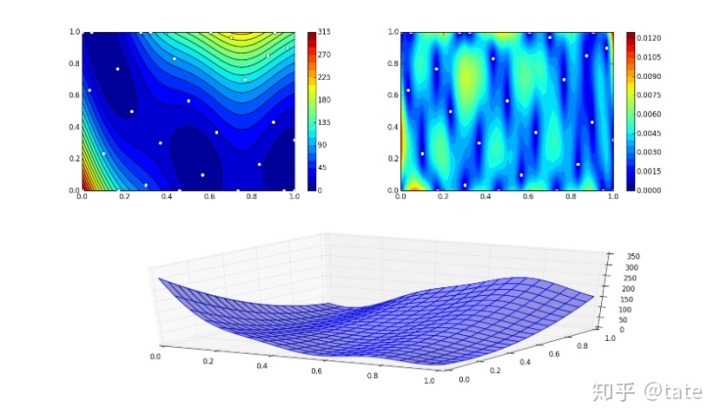
功能
- 构建超大容量的Kriging模型
pyKriging提供n维Kriging。 包括用于2D和3D模型(已安装MayaVI)的绘图工具。 - 自动化模型填充
训练完初始模型后,pyKriging可以建议将下一个样品放置在何处以改进模型。
pyKriging支持基于搜索最大均方误差(MSE)或基于预期改进的填充选择。
均方误差旨在提高模型的整体准确性。 预期的改进探索了模型的可能最小值,这在许多优化活动中很有用
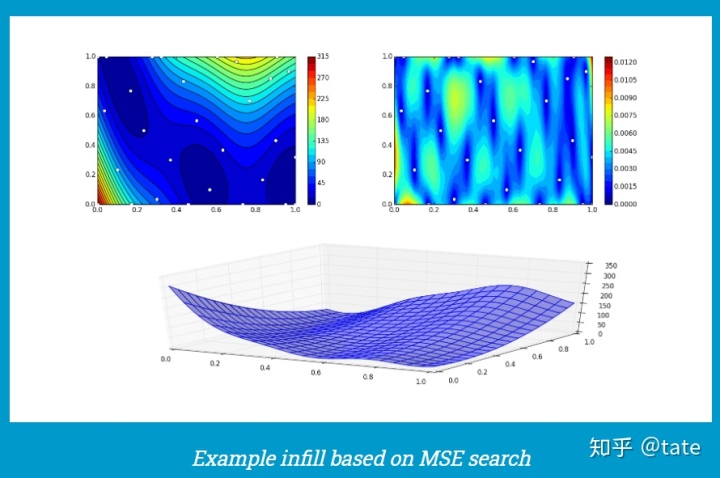
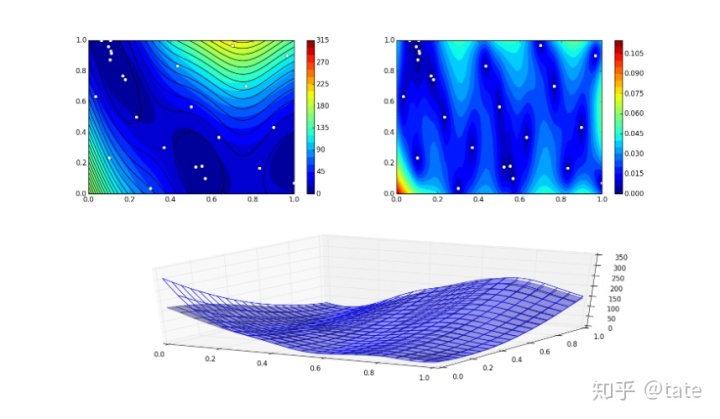
训练记录
快照功能允许监控克里格训练过程。这允许用户绘制超参数收敛、预测精度(如果提供了分析函数)和预测收敛。有关使用培训历史记录功能的更多信息,请查看Github示例文件夹。














 4672
4672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









