






请看前文:
飘哥:自然语言处理系列之文本自动摘要技术(一)信息摘要概述zhuanlan.zhihu.com



抽取式文档摘要方法
如果以句子为单位做抽取式文档摘要,判断句子重要性是影响抽取式摘要质量的关键因素,关键问题是如何衡量句子的重要性,影响句子重要性的因素有以下几种: - 句子的长度,句子长短要适中 - 句子位置,不是所有的文档中句子的位置重要性很关键,但是在新闻中句子位置的重要性会突出,如在新闻中第一句话最重要,后面文字的重要性次之。 - 句子中词语的重要性,人们通过统计简单直观的文本特征,如词频、词位置、特定的线索词、标题等,从文档中识别重要句子组成摘要。词频是最简单有效的方法。在文中出现次数越多的词,越有可能更重要。根据词频确定词权重,以组成句子的词权重之和作为句子权重来判断句子重要性,是基于词频的自动摘要方法的主要思想。TF-IDF(term frequency–inverse document frequency是一种用于信息检索与数据挖掘的常用加权技术。TF意思是词频Term Frequency,IDF意思是逆向文件频率Inverse Document Frequency)是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。 - 句子中的线索词,一些特殊词所在的句子被选入摘要的概率大于其他句子,句子中的特殊词语,如总之,总而言之等,这些词都是对内容的高度概括。统计表明,有26%的句子含有线索词。 - 句子是否与标题相似,通常标题是是对原文内容的高度概括,摘要选的句子和标题相似性大,选取摘要的句子就会好一些。当前可能这种方式不是很好,因为一些新闻标题党特别严重,就是标题跟正文内容并不吻合,标题跑偏。
一.基于单一因素的摘要方法
只考虑句子位置是一种简单有效的摘要方法,这里有两个baseline lead baseline(前导基准),即从开头截取原文一定数量的词组成文摘, 前导基准同时针对单文档和多文档自动文摘系统,是单文档摘要的强基准方法。 Coverage Baseline(覆盖基准) 即从原文集合中抽取每个文档的第一句,直至达到字数限制为止,没有达到字数限制就再轮流从不同文档中抽取、第二、…, 第K句话形成摘要,覆盖基准主要针对多文档文摘系统,但不是很有效。
二.基于启发式规则
基于经验性公式综合考虑少数几个因素。如centroid-based method(基于中心的方法)就是基于启发式规则的方法,(Radev, Dragomir R., et al. “Centroid-based summarization of multiple documents.” Information Processing & Management 40.6(2004):919-938. ) 中心性(centrality)可以看作是句子的一个统计特征,Radev在2004年的论文中明确提出将中心度作为句子重要性度量的一个特征,扩展了传统的基于统计(Statistical-based)的方法,常用的统计特征包括但不限于以下:句子位置(position)、关键词频率(TF)、TF-IDF、首句/标题相似度(resemblance)、句子相对长度(length)、专有词(numerical data,name entity etc.)、信息熵(information gain)、互信息(mutual information)等。 在该论文中,作者提出了一种基于中心的多文档摘要方法,作者将中心(centroid)定义为:统计上能够代表关于某一主题的一系列文章的单词集合。因此首先要对文档进行聚类,确定簇中心,如果一个句子含有越多的中心词,那么这个句子越能代表这个文章簇。因此作者考虑以下三个特征作为句子筛选的依据,三个特征就是词语的权重,句子位置,句子与首句相似度,分别算出三个值,ci,pi,fi:
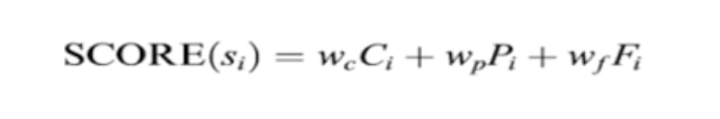
然后把这三个值相加求和,然后得到每一个句子的重要性,最后根据句子的重要性选择句子形成摘要。这个方法比较流行,用的比较多。
三.基于图(graph-based)排序的方法
基于统计特征的方法只能从预先规定好的特征上孤立的给每个句子打分,忽略了文本自身的结构,因而有研究者提出了基于图(graph-based)的方法,将文本表示成一个图模型,充分利用文本自身的结构,在全局上(global information)确定文本单元(句子、单词短语、unigram、bigram、trigram)的重要度。
这是2004年提出来的(Mihalcea, Rada, and P. Tarau. “TextRank: Bringing Order into Texts.” Emnlp (2004):404-411. Mihalcea是罗马尼亚人,在得克萨斯州立大学后来到了密西根大学做教授,Rada也是密西根大学教授)在图模型中,文本单元被表示成顶点,边用来连接具有相似性的两个顶点。在网络建立好后,重要句子通过随机游走(random walk)算法被筛选出来。 图排序算法有lexrank和textrank等,它只依赖于句子相似度。TextRank算法是基于图模型的文本摘要最具代表性的方法,由Mihalcea等人于2004年提出。TextRank采用与Google PageRank类似的算法用于确定句子重要度,其背后的思想是“voting”或 “recommendation”。当一个顶点链接到另一个顶点时,它也完成了对另一个顶点的一次投票,当为一个顶点投的票数越多,这个顶点的重要性也就越高。此外,投票顶点自身的重要性也决定了该次投票的分量,PageRank算法也考虑了这一信息。因此,一个顶点的重要性由这个顶点收到的投票数以及投这些票的顶点的重要度共同决定。
图排序算法的步骤:
- 构建图G=(V,E),句子作为顶点,句子之间有关系则构建边
- 应用PageRank算法或相似算法获得每个顶点的权重
- 基于句子权重选择句子形成摘要
a.图中边加权

上面是一篇文章,有24个句子,
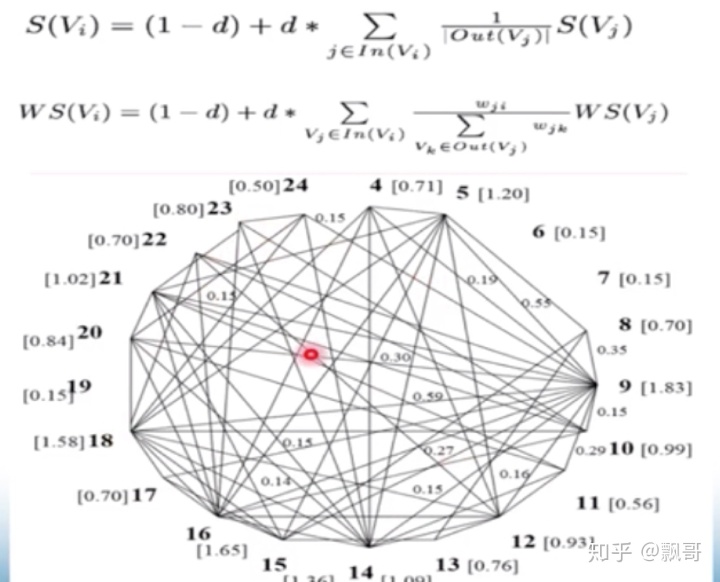
文中的24个句子构成了24个顶点,点和点之间有边连接,连接带有权重,权重是用相似度计算,不带权的图,设个阈值,大于0.1的时候有边,小于0.1的时候没有边。
b.引入语义角色信息
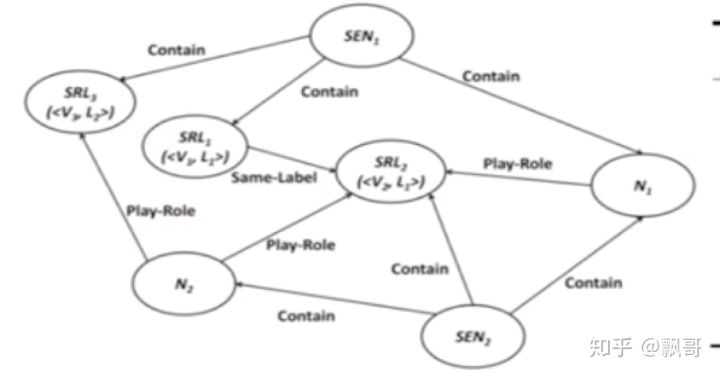
2014年在图中引入了角色的信息,之前的图只有句子和句子的关系,现在把图变成了异构图,图中既包含句子又包含词,还包含语义角色。这些信息都在一个图中,然后做一个异构图排序,利用语义角色的节点,以及语义角色和句子,词之间的关系来帮助和改善语句的排序。
基于图的方法是对基于统计方法的一次大的提升,将自动文摘的研究带入到一个新的方向,目前很仍然有很多将图模型与其他方法相结合的研究。















 6806
6806











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









