





简单系列是使用GO语言解决一些业务场景下的实际问题,比如数据处理、文件解析等等,没啥技术含量,不过比较实用。
业务场景

前段时间做了很多系统对接的工作,对方提供了input和output的数据下载,但是下载下来的是xml文件,我想要进行解析特定字段并保存到excel中进行处理,要怎么做呢?
解决思路
这里需要用的xml解析和上一篇文章中提到的excel生成,如果不清楚go怎么快速操作excel的,可以先看下之前的文章:
Excel处理
Go语言单排,公众号:GO语言单排Go解决简单问题系列(一)-Excel处理
代码实现
1. 准备工作:
(1)新建一个文件夹xml;
(2)进入xml文件夹;
(3)使用go mod
go mod init xml(这里是你的项目名,用什么都可以)(4)新建一个main.go的文件;
(5)下载类库tealeg/xlsx(用来处理excel的文件),而xml的处理交给了基本库中的`encoding/xml`。
整体的目录结构非常简单,如下图所示,这也是我们使用go而不是java进行处理的原因。java过于重量级,这种简单的事情还是交给go吧
图1. 目录结构
2. 代码:
放代码之前,先和大家说下xml的两种处理逻辑。
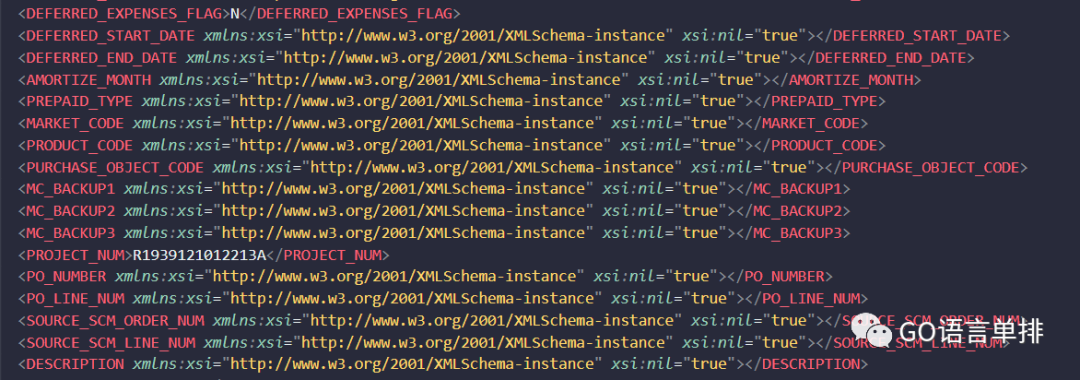
图2. 一个简单的xml(部分)
(1)定义结构体进行存储。由于xml是类json的结构,有着严格的起始和终止符,因此我们可以定义一个结构体,将xml的数据存进去。不过在实际操作中,我定义结构体之后xml的数据始终没有正确存入,因此我选择了第二种相对复杂的处理方式。
(2)遍历。对xml的数据进行遍历,根据类型不同可以进行判断,其类型主要包括:元素开始标记、元素结束标记和字符数据。前两个是标签,最后一个才是我们最终要解析的字段。
package mainimport ( "bytes" "encoding/xml" "fmt" "io/ioutil" "log" "os" "strconv" "strings" "github.com/tealeg/xlsx")// 定义了一个结构体来进行相应存储type Expense struct { BOOK_AMOUNT []string TAX_FREE_AMOUNT []string TAX_AMOUNT []string}func main() { // 从文件读取,如可以如下: content, _ := ioutil.ReadFile("220.xml") decoder := xml.NewDecoder(bytes.NewBuffer(content)) expenses := construct(decoder) exportExcel("demo.xlsx", expenses)}// 解析xmlfunc construct(decoder *xml.Decoder) Expense { var ( expense Expense t xml.Token err error ) // 定义了几个数组,用来存储遍历后各个字段的值,一会儿存入excel中 var bookAmount []string var taxFreeAmount []string var taxAmount []string var name string for t, err = decoder.Token(); err == nil; t, err = decoder.Token() { switch token := t.(type) { // 处理元素开始(标签) - 这个标签我暂时用不到 case xml.StartElement: name = token.Name.Local fmt.Printf("Token name: %s\n", name) for _, attr := range token.Attr { attrName := attr.Name.Local attrValue := attr.Value fmt.Printf("An attribute is: %s %s\n", attrName, attrValue) } // 处理元素结束(标签) - 这个标签我暂时也用不到 case xml.EndElement: fmt.Printf("Token of '%s' end\n", token.Name.Local) // 处理字符数据(这里就是元素的文本) - 这里是重点 // 获取字段的key和value,进行对应的存储 case xml.CharData: content := string([]byte(token)) if name == "BOOK_AMOUNT" { bookAmount = append(bookAmount, content) } if name == "TAX_FREE_AMOUNT" { taxFreeAmount = append(taxFreeAmount, content) } if name == "TAX_AMOUNT" { taxAmount = append(taxAmount, content) } fmt.Printf("This is the content: %v\n", content) } } // 将数组存入结构体中 expense.BOOK_AMOUNT = bookAmount expense.TAX_FREE_AMOUNT = taxFreeAmount expense.TAX_AMOUNT = taxAmount return expense}// 根据文件名获取文件路径 - 通用方法func getFilePath(fileName string) string { dir, err := os.Getwd() if err != nil { log.Fatal(err) } return dir + "\\" + fileName}// 生成excel - 通用方法func exportExcel(fileName string, expense Expense) { outFile := getFilePath(fileName) file := xlsx.NewFile() sheet, err := file.AddSheet("result_sheet") if err != nil { fmt.Print(err) } bookAmount := expense.BOOK_AMOUNT taxFreeAmount := expense.TAX_FREE_AMOUNT taxAmount := expense.TAX_AMOUNT // 添加表头 row := sheet.AddRow() for i := 0; i < 3; i++ { nameCell := row.AddCell() switch i { case 0: nameCell.SetValue("总额") case 1: nameCell.SetValue("不含税") case 2: nameCell.SetValue("税额") } } for i, v := range bookAmount { if strings.Contains(v, "\n") { continue } row := sheet.AddRow() v1 := taxFreeAmount[i] v2 := taxAmount[i] for j := 0; j < 3; j++ { nameCell := row.AddCell() switch j { case 0: vtemp, _ := strconv.ParseFloat(v, 64) nameCell.SetFloat(vtemp) case 1: v1temp, _ := strconv.ParseFloat(v1, 64) nameCell.SetFloat(v1temp) case 2: v2temp, _ := strconv.ParseFloat(v2, 64) nameCell.SetFloat(v2temp) } } } err = file.Save(outFile) if err != nil { fmt.Println(err) }下图是解析完成后生成的excel,因为数据涉及金额,所以我做了处理。
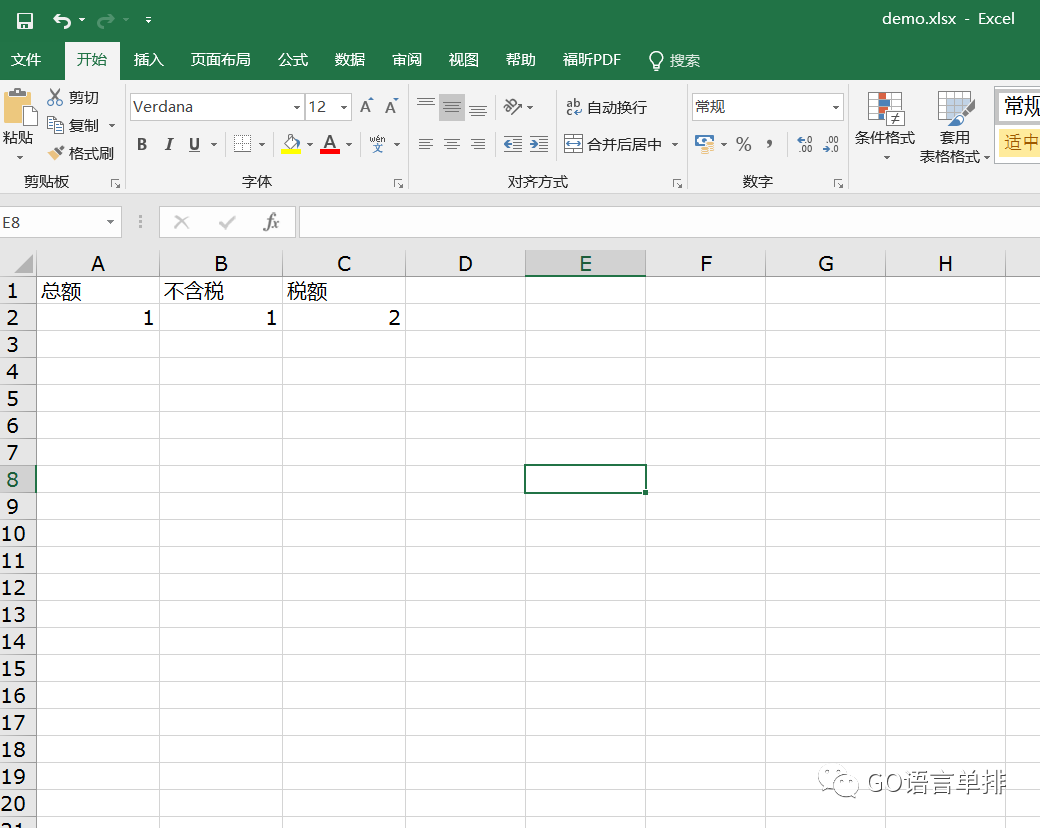
图3. 生成的excel















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









