






本文是对自己在科研和工作中经常使用的一些Python数据处理相关的函数、知识点进行总结整理,其中包含很多精华帖的摘录和自己实操笔记的记录,平时自己都是记在自己的OneNote笔记本里,印象笔记这个软件也不错,安利一下。
一、Python中不同类型数据的索引切片
1.1 字符串&列表&range的索引切片[0:-1]
一、代码示例
str = 'abcdefg'
print(str[1:])
print(str[:-1])
print(str[-1:])
print(str[::-1])
print(str[::-2])
print(str[:])
结果
bcdefg
abcdef
g
gfedcba
geca
Abcdefg- 分片操作的也是左闭右开的操作[a,b);
- 从结果就可看出来
[1:]--获取从位置1开始后面的字符(默认首位是0)
[:-1]--删除了位置为-1的剩下的字符(也就是获取从位置0带位置-1之间的字符)
[-1:]--获取位置-1的字符
[::-1]--从最后一个元素到第一个元素复制一遍。(也就是倒序)
[:]--相当于完整复制一份str1.2 python for i in range()的使用

二、Python数据维度重构和数据类型转换
2.1 数据维度重构函数-reshape函数&np.newaxis函数
shape和reshape函数都是只能对元组、数组进行操作的,其他的list形式的数据用不了
2.1.1 一维数组转化为多维数组
1、要记住,python默认是按行取元素
-1是模糊控制的意思 比如人reshape(-1,2)固定2列 多少行不知道

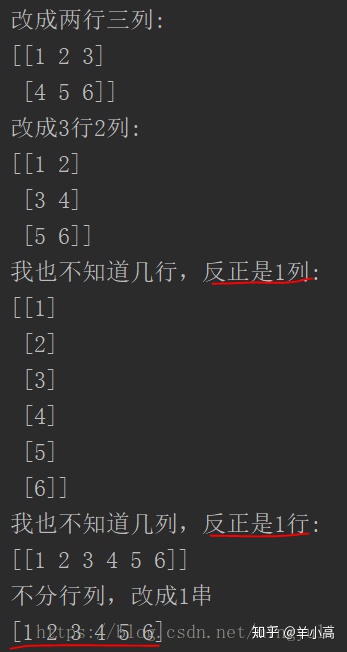
>>> a = np.array([[1,2,3], [4,5,6]])
>>> np.reshape(a, (3,-1)) # the unspecified value is inferred to be 2
array([[1, 2],
[3, 4],
[5, 6]])因为 a 总共有 6 个元素,reshape 成一个二维数组,指定第一维的长度是3(即 3 行),numpy 可以自动推断出第二维的长度是 2 (6 除以 3 等于 2)。
我们可以再试一下如果有多个维度没有指定长度的话会怎样。
>>> np.reshape(a, (-1,-1))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python2.7/dist-packages/numpy/core/fromnumeric.py", line 224, in reshape
return reshape(newshape, order=order)
ValueError: can only specify one unknown dimension如果出现了无法整除的情况呢?
np.reshape(a, (4,-1))
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python2.7/dist-packages/numpy/core/fromnumeric.py", line 224, in reshape return reshape(newshape, order=order)
ValueError: total size of new array must be2.1.2 多维数组转化为一维数组
1. import operator
2. from functools import reduce
3. a = [[1,2,3], [4,6], [7,8,9,8]]
4. print(reduce(operator.add, a))
[1, 2, 3, 4, 6, 7, 8, 9, 8]
a = [[1,2,3], [5, 8], [7,8,9]]
l=[]
for m in range(0,3):
for i in a[m]:
l.append(i)
print(l)
[1, 2, 3, 5, 8, 7, 8, 9]
13. from itertools import chain
14. b=[[1,2,3], [5,8], [7,8,9]]
15. c=list(chain(*b))
16. print(c)
17. [1, 2, 3, 5, 8, 7, 8, 9]
18. a=[[1,2,3], [5,8], [7,8,9]]
19. a= eval('['+str(a).replace(' ','').replace('[','').replace(']','')+']')
20. print(a)
21. [1, 2, 3, 5, 8, 7, 8, 9]
22. def flatten(a):
23. if not isinstance(a, (list, )):
24. return [a]
25. else:
26. b = []
27. for item in a:
28. b += flatten(item)
29. return b
30. if __name__ == '__main__':
31. a = [[[1,2],3],[4,[5,6]],[7,8,9]]
32. print(flatten(a))
33. [1, 2, 3, 4, 5, 6, 7, 8, 9]
34. ab = [[1,2,3], [5,8], [7,8,9]]
35. print([i for item in ab for i in item])
36. [1, 2, 3, 5, 8, 7, 8, 9]
2.1.3 数据维度加1-np.newaxis
np.newaxis主要用来给数组添加新的维度,直接看下面的使用方法就会明白:
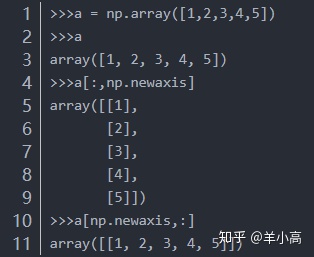
>>>a = np.array([1,2,3,4,5])
>>>a
array([1, 2, 3, 4, 5])
>>>a[:,np.newaxis] #维度从(5,)变成(5,1)
array([[1],
[2],
[3],
[4],
[5]]) #
>>>a[np.newaxis,:]
array([[1, 2, 3, 4, 5]]) #维度从(5,)变成(1,5)2.2 数据类型转化:dataframe 、ndarry 、list
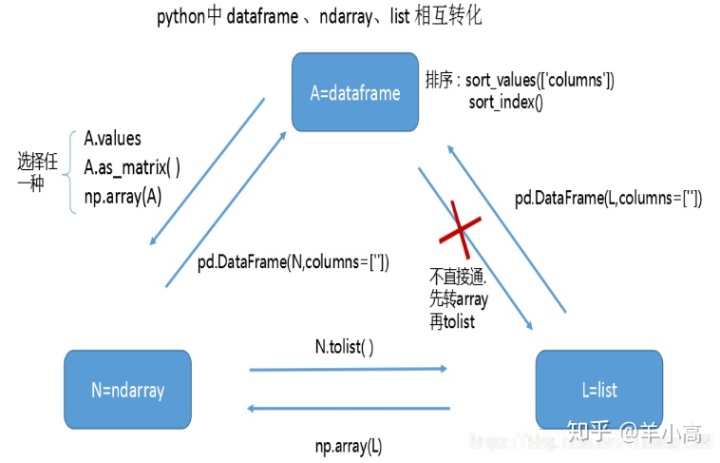
- dataframe不能直接转换成list格式,要先np.array(x)转元组,再.tolist转换成列表格式;
- N.tolist这个后面要有括号,.tolist()

- tuple可以将列表转换为元组,tup = tuple(list);
2.3 列表所有str元素快速转换为float
2.4 从list创建dict 以及 使用sorted对dict进行排序
- 使用两个list创建dict
a = ['math','english','art']
b = ['99','78','66']
c = dict(zip(a,b))- 创建指定list为键名的dict
c = {}.fromkeys([keylist],默认值)- 使用sorted对字典进行排序,本质上还是sorted函数的使用
sorted(iterable, key=None, reverse=False) Return a new list containing all items from the iterable in ascending order.
A custom key function can be supplied to customize the sort order, and the reverse flag can be set to request the result in descending order.
e = sorted(c.items(),key=lambda d : d[0])
e = sorted(c.items(),key=lambda d : d[1])三、常见的数据处理会用到的函数
3.1 map函数--多用于处理列表
3.1.1 map函数全部解释
- map函数的原型是map(function, iterable, …),它的返回结果是一个列表。参数function传的是一个函数名,可以是python内置的,也可以是自定义的。 参数iterable传的是一个可以迭代的对象,例如列表,元组,字符串这样的。
- 这个函数的意思就是将function应用于iterable的每一个元素,结果以列表的形式返回。注意到没有,iterable后面还有省略号,意思就是可以传很多个iterable,如果有额外的iterable参数,并行的从这些参数中取元素,并调用function。如果一个iterable参数比另外的iterable参数要短,将以None扩展该参数元素。还是看例子来理解吧!
a=(1,2,3,4,5)
b=[1,2,3,4,5]
c="zhangkang"
la=map(str,a)
lb=map(str,b)
lc=map(str,c)
print(la)
print(lb)
print(lc)
输出:
['1', '2', '3', '4', '5']
['1', '2', '3', '4', '5']
['z', 'h', 'a', 'n', 'g', 'k', 'a', 'n', 'g']str()是python的内置函数,这个例子是把列表/元组/字符串的每个元素变成了str类型,然后以列表的形式返回。
3.1.2 当然我们也可以传入自定义的函数,看下面的例子.
def mul(x):
return x*x
n=[1,2,3,4,5]
res=map(mul,n)
输出:[1, 4, 9, 16, 25]把列表n中的每个元素运行一次mul函数后得到的结果作为最终结果列表的元素。再看下有多个iterable参数的情况。
def add(x,y,z):
return x+y+z
list1=[1,2,3]
list2=[1,2,3]
list3=[1,2,3]
res=map(add,list1,list2,list3)
print(res)
输出:[3, 6, 9]并行的从三个列表中各自取出元素然后运行add函数,有人可能会问,如果三个列表长度不一样怎么办,前面已经说了,对于短的那个iterable参数会用None填补。对于上面的例子,如果list3=[1,2]的话,那么这个程序会报错,因为虽然在运行add函数的时候列表list3的最后一个元素会用None填补,但是None和int类型的数是不能相加的。也就是说,除非参数function支持None的运算,否则根本没意义。现在我们看下另一个例子你就明白了
def add(x,y,z):
return x,y,z
list1 = [1,2,3]
list2 = [1,2,3,4]
list3 = [1,2,3,4,5]
res = map(add, list1, list2, list3)
print(res)
输出:
[(1, 1, 1), (2, 2, 2), (3, 3, 3), (None, 4, 4), (None, None, 5)]3.1.3 注意事项
- map函数返回的是一个map类型的序列,而不是列表
在Python3中,map函数返回的不是一个列表,而是一个map类型的序列.
>>> type(map(int, [3, 4]))
<class 'map'>使用时可以根据实际情况的需要,将map函数的返回值转化为列表或者元组等。
- 当function参数没有返回值时,map函数将返回一个由None组成的序列
def test_function(number):
pass
print(list(map(test_function,[1,2,3])))
运行结果是:
[None, None, None]
返回值:
Python 2.x 返回列表。
Python 3.x 返回迭代器。3.1.4 小例子

3.2 列表生成式和lambda表达式
#####print(list(map(lambda x: x * x, [y for y in range(3)])))的输出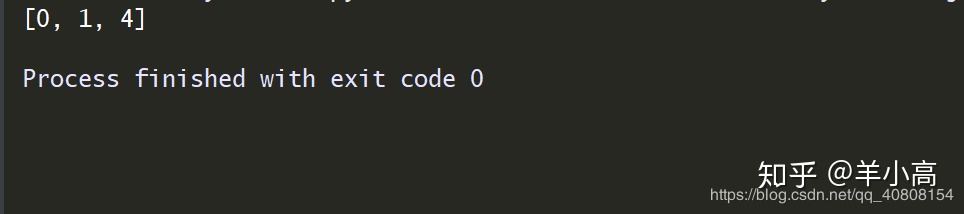
- 首先列表推导式生成[0,1,2]
- [y for y in range(3)]
然后map函数接受两个参数,第一个是函数,第二个是可迭代的序列(这里是[0,1,2]),作用是返回生成器对象(python3中返回生成器,python2返回的是列表),里面的每个对象是可迭代序列中每个元素执行了函数功能的返回值,只不过这个函数是匿名函数lambda,功能是实现每个元素的平方。
1. b=map(lambda x: x * x, [y for y in range(3)])
print(b)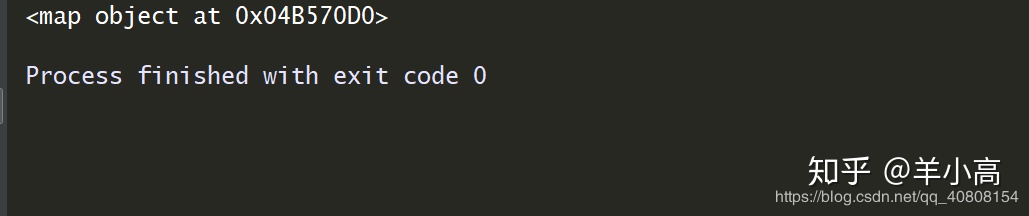
对map()函数返回值进行list()操作,即返回[0,1,4]
1. b=map(lambda x: x * x, [y for y in range(3)])
2. c=list(b)
print(c)
- lambda表达式
lambda表达式返回可调用的函数对象,并且在运行时返回它们,通常是在需要一个函数,但是又不想去命名一个函数的场合下使用。所以lambda表达式就相当于一个函数。如
lambda x : x+1 这里表示输入x,输出为x+1
例如
>>>
>>> g = lambda x : x**2
>>>
>>> type(g)
<class 'function'>
>>>
>>> g(3)
9
>>>
x表示输入,x**2输出,lambda表达式是一个函数对象。
map和lambda表达式联合使用
>>>
>>> a = [2,5,6]
>>>
>>> list(map(lambda x:x*10,a))
[20, 50, 60]
>>>
>>> a
[2, 5, 6]
>>> >>>3.3 zip()函数、list(zip(list1, list2))、dict(zip(list1,list2))
案例描述
• 通过计算机程序模拟抛掷骰子,并显示各点数的出现次数及频率
• 1.0功能:模拟抛掷1个骰子,并输出其结果
• 2.0功能:模拟抛掷2个骰子,并输出其结果
案例分析
• 如何将对应的点数和次数关联起来?
答案: zip()函数
zip()函数
- zip()函数将两个列表对应的元素打包成一个元组,返回一个对象,将这个对象转化成list或者字典形式均可:list(zip(list1, list2))
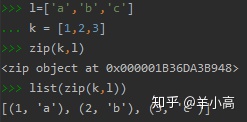
注意:列表中元组的元素是不可修改的
- 若要修改,可将对象转换为可修改的字典:dict(zip(list1, list2))
案例代码
"""
模拟掷骰子2.1
马玉华 2019.8.2
1.0功能:模拟掷 1 个骰子,并输出结果
2.1功能:模拟掷 2 个骰子,并输出结果
知识:1.用zip(list1,list2,list3)将两个列表变成一个对象(1,2,3),(1,2,3),(1,2,3)......,里面是元组
2. dict(zip(list1,list2))可将元组为两个元素的变成一个字典
"""
import random
def roll_dice():
roll = random.randint(1,6) #产生随机1-6整数
return roll #返回随机数
def main():
roll_times = 1000000 #投骰子次数
roll_number_list = [2,3,4,5,6,7,8,9,10,11,12] #骰子点数结果列表
result_record_list = [0,0,0,0,0,0,0,0,0,0,0] #列表中列出结果分别为2-12点的次数,开始都是零次
zip(roll_number_list,result_record_list) #将两个列表合成一个对象,对象中的元素为元组,(1,2),(11,22)......
result_dict = dict(zip(roll_number_list,result_record_list)) #对象再变成字典,元组中的两个数分别为字典中的key和value
for i in range(roll_times):
roll1 = roll_dice() #骰子1的结果
roll2 = roll_dice() #骰子2的结果
for roll_number in roll_number_list: #骰子结果result分别在2-12间循环
if roll1 + roll2 == roll_number: #如果等于对应的结果,就在字典中的次数里加1记录下来
result_dict[roll_number] += 1 #字典的value加1
for roll_number,result_record in result_dict.items(): #遍历字典的keys和value,用items()
print('点数为{}的次数为{}'.format(roll_number,result_record))
if __name__ == '__main__':
main()
输出结果:
C:UsersmayuhuawDesktoppy项目7.模拟掷骰子venvScriptspython.exe C:/Users/mayuhuaw/Desktop/py项目/7.模拟掷骰子/模拟掷骰子2.1.py 点数为2的次数为27673 点数为3的次数为55222 点数为4的次数为83695 点数为5的次数为110998 点数为6的次数为138855 点数为7的次数为166469 点数为8的次数为139427 点数为9的次数为110749 点数为10的次数为83433 点数为11的次数为55523 点数为12的次数为27956
Process finished with exit code 03.4 set()函数
- set()函数 函数创建一个无序不重复元素集,可进行关系测试,删除重复数据,还可以计算交集、差集、并集等。 并且其返回的对象是一个iterable – 可迭代对象的对象。
- 举例说明set()函数的使用:并集(|)、交集(&)、差集(-)
特别备注:差集是指给第一个set(s)去除set(s)与set(s1)的交集。
代码:
# coding:utf-8;
"""&求交集,|求并集, - 求差集"""
s = 'abb'
s1 = 'bcd'
print(set(s))
print(set(s1))
print(set(s) & set(s1))
print(set(s) | set(s1))
print(set(s) - set(s1))
输出结果:
3.5 apply函数
- 函数原型
DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds)
- 该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针。
- 这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据
- 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数会自动遍历每一行DataFrame的数据,最后将所有结果组合成一个Series数据结构并返回。
- apply函数常与groupby函数一起使用,如下图所示
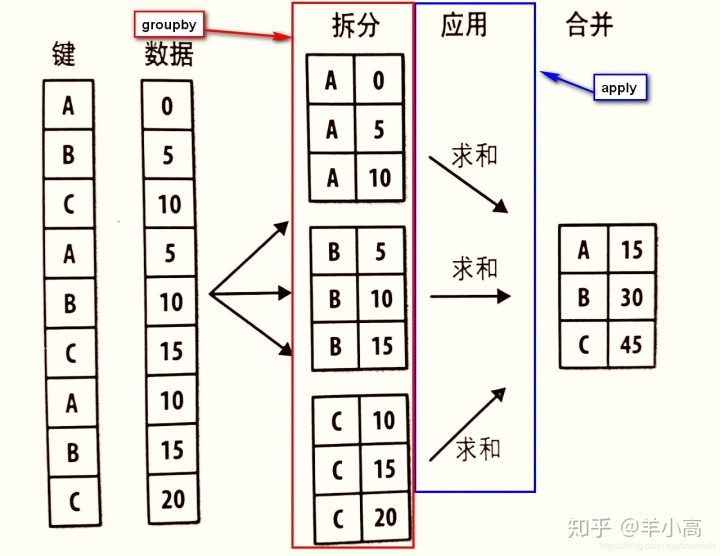
举栗子
1.对指定列进行操作
data=np.arange(0,16).reshape(4,4)
data=pd.DataFrame(data,columns=['0','1','2','3'])
def f(x):
return x-1
print(data)
print(data.ix[:,['1','2']].apply(f))
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
1 2
0 0 1
1 4 5
2 8 9
3 12 13
2.对行操作
data=np.arange(0,16).reshape(4,4)
data=pd.DataFrame(data,columns=['0','1','2','3'])
def f(x):
return x-1
print(data)
print(data.ix[[0,1],:].apply(f))
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
0 1 2 3
0 -1 0 1 2
1 3 4 5 6
3.整体对列操作
data=np.arange(0,16).reshape(4,4)
data=pd.DataFrame(data,columns=['0','1','2','3'])
def f(x):
return x.max()
print(data)
print(data.apply(f))
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
0 12
1 13
2 14
3 15
dtype: int64
4.整体对行操作
data=np.arange(0,16).reshape(4,4)
data=pd.DataFrame(data,columns=['0','1','2','3'])
def f(x):
return x.max()
print(data)
print(data.apply(f,axis=1))
0 1 2 3
0 0 1 2 3
1 4 5 6 7
2 8 9 10 11
3 12 13 14 15
0 3
1 7
2 11
3 15
dtype: int64
3.6 str.format()函数
在python中使用help命令窗口该方法获得如下结果
>>> help(str.format)
Help on method_descriptor:
format(...)
S.format(*args, **kwargs) -> str
Return a formatted version of S, using substitutions from args and kwargs.
The substitutions are identified by braces ('{' and '}').- 根据上述的方法解释,是指该方法是用来返回字符串的格式化后结果,在该方法中在参数args与kwargs使用了替代物,替代物需要用大括号'{}'标识。
- 按照上述说法,该方法有两个参数,可是查找了半天,也没有见到有两个参数的使用。后来在帮助文档中发现如下方法说明
str.format(*args, **kwargs)
Perform a string formatting operation. The string on which this method is called can
contain literal text or replacement fields delimited by braces {}. Each replacement field
contains either the numeric index of a positional argument, or the name of a keyword argument.
Returns a copy of the string where each replacement field is replaced with the
string value of the corresponding argument.
>>> "The sum of 1 + 2 is {0}".format(1+2)
'The sum of 1 + 2 is 3'- 根据这个说法,才发现原来这里的两个参数并不是指的共用的方式,而是一种替换选择的模式,换言之,可以使用args变量,也可以使用kwargs变量,如果两个都使用,则按照未定义关键字的在前,定义关键字的在后形式展示
如下所示
>>> x='this is my x test'
>>> m='ok,{}, m, {x}'
>>> m.format(1+2,x=x)
'ok,3, m, this is my x test'即使在定义时空括号在后,在format时也需要提前处理
>>> x='this is my x test'
>>> m='ok, {x},{},ok'
>>> m.format(1+2,x=x)
'ok, this is my x test,3,ok'在format时候可以传递多个参数,但是不能少于字符串规定的未定义关键字的数量,也不能少于定义关键字的数量,否则就报错
>>> x='this is my x test'
>>> y='this is my y test'
>>> m='ok,{x},{},ok'
>>> m.format(1+2,2+3,x=x,y=y)
'ok, this is my x test,3,ok'- 几个小例子
通过关键字
print('{名字}今天{动作}'.format(名字='陈某某',动作='拍视频'))#通过关键字
grade = {'name' : '陈某某', 'fenshu': '59'}
print('{name}电工考了{fenshu}'.format(**grade))#通过关键字,可用字典当关键字传入值时,在字典前加**即可
通过位置
print('{1}今天{0}'.format('拍视频','陈某某'))#通过位置
print('{0}今天{1}'.format('陈某某','拍视频'))
填充和对齐
^<>分别表示居中、左对齐、右对齐,后面带宽度
print('{:^14}'.format('陈某某'))
print('{:>14}'.format('陈某某'))
print('{:<14}'.format('陈某某'))
print('{:*<14}'.format('陈某某'))
print('{:&>14}'.format('陈某某'))#填充和对齐^<>分别表示居中、左对齐、右对齐,后面带宽度
精度和类型
f精度常和f一起使用
print('{:.1f}'.format(4.234324525254))
print('{:.4f}'.format(4.1))
进制转化
b o d x 分别表示二、八、十、十六进制
print('{:b}'.format(250))
print('{:o}'.format(250))
print('{:d}'.format(250))
print('{:x}'.format(250))
千分位分隔符
这种情况只针对与数字
print('{:,}'.format(100000000))
print('{:,}'.format(235445.234235))














 525
525

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









