





table型的表格可以直接利用pandas的read_html一句话抓取,而不需依赖requests等爬虫库
尝试爬取A股上市公司数据,参照了上面的文章,并做了一些改进。
针对原文pandas爬取的代码有几个问题:
1、默认保留了所有页的标题列,这样爬取完之后出现大量的标题重复行
2、深交所上市的股票代码为000开头,在read_html读取过程中便默认去掉了0的前缀
3、178页的数据用for循环爬取依旧缓慢,考虑引入进程池
ps:read_html并不能赋予headers等信息,为了使得程序更具有鲁棒性,建议像原文那样,先通过requests访问,再用beautifulsoup解析后,利用read_html去读取。这里为了便利并且该网站没有反爬虫限制简化了操作。
第二个问题是在read_html的过程中就舍弃了前缀0,目前没有找到对应的修改参数,最终只能尝试在excel中用公式解决
选择股票代码一列,右键-设置单元格格式-数字-自定义,输入000000即可。
注意:抓取存取为csv格式可以用excel读取,但使用excel编辑后建议另存为xlsx格式,否则会造成错乱。
改进过后的输出如下,只需几秒钟即可抓取全部178页数据。
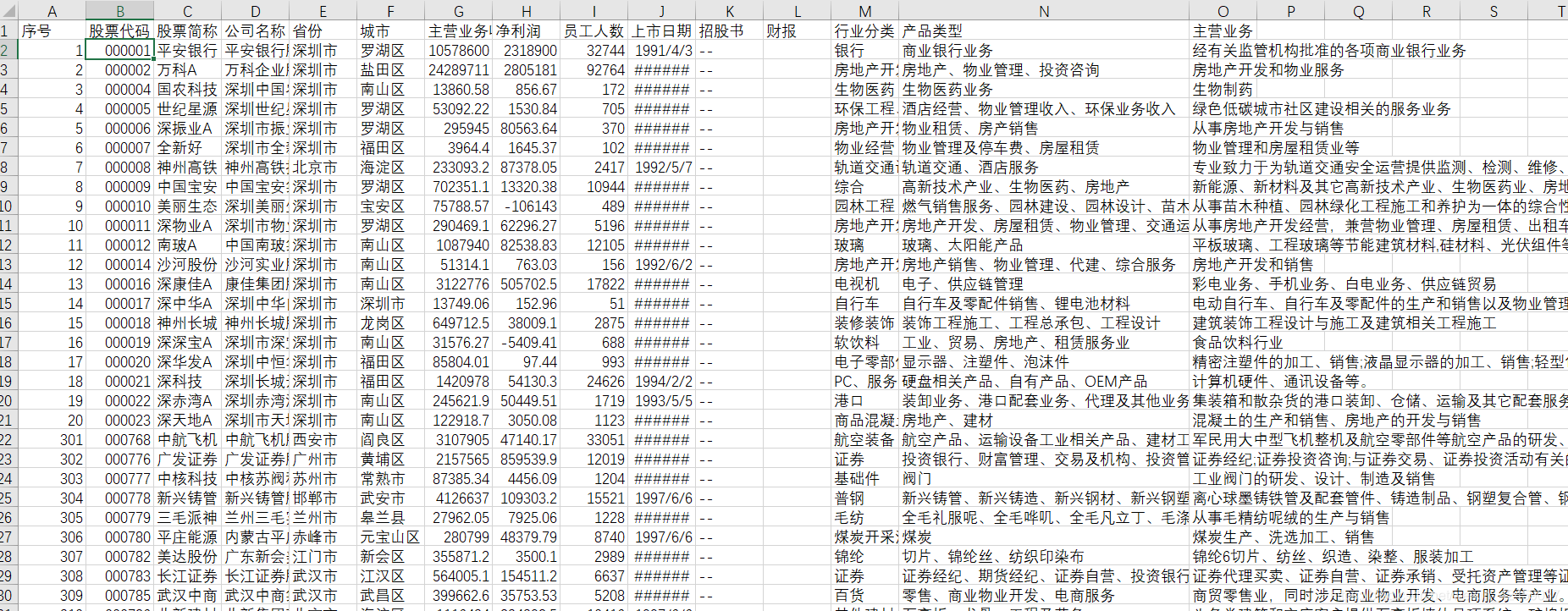
PS:由于进程池的引入,可以看到并没有按照一页页的顺序去抓取信息,如有需要,也可以在excel中按照序号排序即可。
附代码:
import pandas as pd
import csv
from multiprocessing import Pool
import time
def getdata(url):
tb = pd.read_html(url)[3] #经观察发现所需表格是网页中第4个表格,故为[3]
tb.to_csv(r'E:stock.csv', mode='a', encoding='utf_8_sig', header=0, index=0)
time.sleep(0.5)
#print('第'+str(i)+'页抓取完成')
#引入进程池
def myprocesspool(num=10):
pool = Pool(num)
results = pool.map(getdata,urls)
pool.close()
pool.join()
return results
if __name__=='__main__':
urls=[]
for i in range(1,179): # 爬取全部178页数据
tmp = 'http://s.askci.com/stock/a/?reportTime=2017-12-31&pageNum=%s' % (str(i))
urls.append(tmp)
#预先输入好表格的列名
with open(r'E:stock.csv', 'w', encoding='utf-8-sig', newline='') as f:
csv.writer(f).writerow(['序号', '股票代码', '股票简称', '公司名称', '省份', '城市' ,
'主营业务收入','净利润','员工人数','上市日期','招股书','财报','行业分类','产品类型','主营业务'])
myprocesspool(10)














 2479
2479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









