






什么是selenium ?
selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户 在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome, Opera等。selenium 是一套完整的web应用程序测试系统,包含了测试的录制(selenium IDE),编写 及运行(Selenium Remote Control)和测试的并行处理(Selenium Grid)。
Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript 的浏览器上。
selenium可以模拟真实浏览器,自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲 染问题。
这里要说一下比较重要的PhantomJS,PhantomJS是一个而基于WebKit的服务端JavaScript API,支持 Web而不需要浏览器支持,其快速、原生支持各种Web标准:Dom处理,CSS选择器,JSON等等。 PhantomJS可以用用于⻚面自动化、网络监测、网⻚截屏,以及无界面测试
selenium集请求功能、解析功能为一体的框架
优势:可以用真实的浏览器操作,把访问页面所有的数据加载完毕
安装
1.启动anaconda终端,下载框架
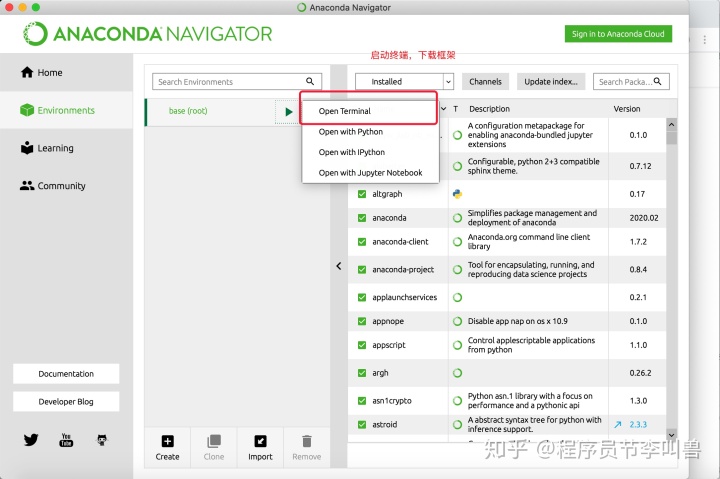
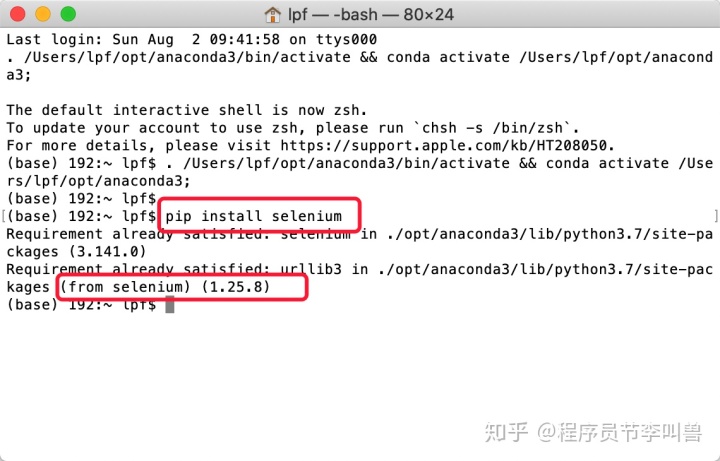
2.输入命令,完成下载安装
配置浏览器驱动
1. 浏览器驱动,必须与浏览器版本相符,首先需要检查浏览器的版本号
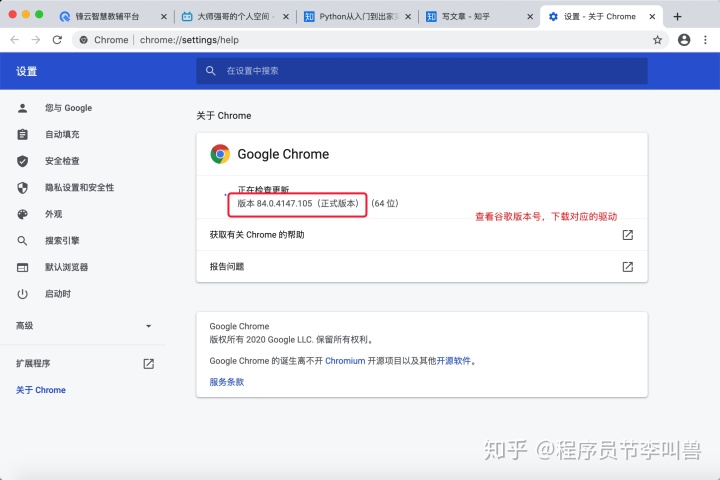
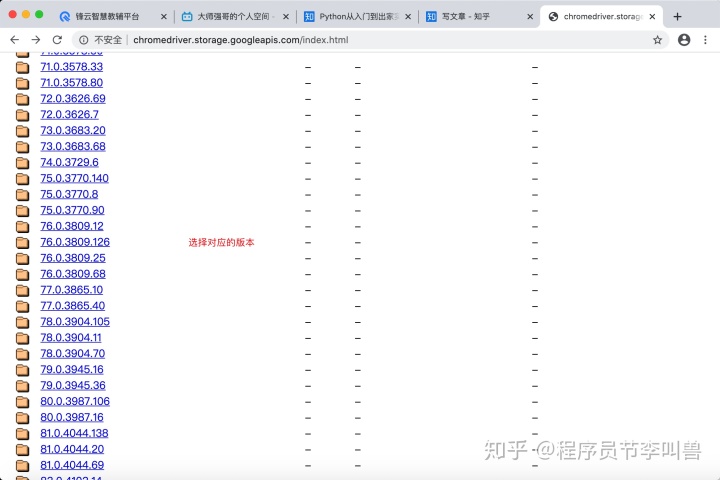
2.下载驱动
下载地址:http://chromedriver.storage.googleapis.com/index.html
网址中下载与本机chrome浏览器对应的驱动程序,驱动程序名为chromedriver; 参考下载版本:

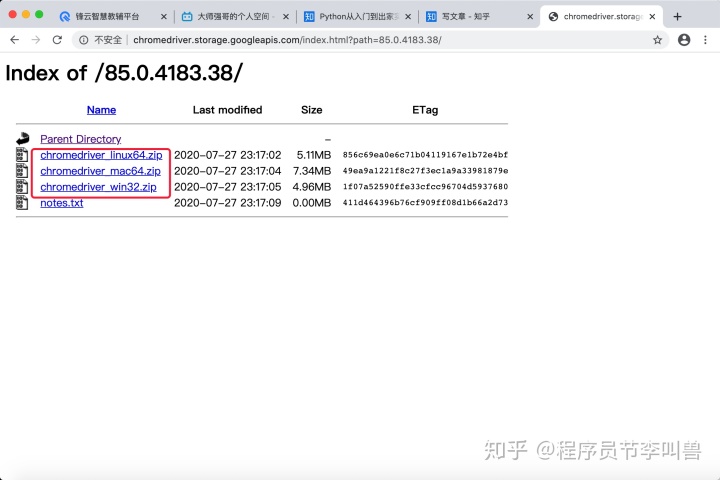

3. 解压到安装路径
下载后把文件解压,然后放到本机chrome浏览器文件路径里,
例如: C:Program Files (x86)GoogleChromeApplication (自己的安装路径)
应用 - 右键 - 打开文件位置

4.将解压后文件chromedriver.exe复制到python的安装目录下(我的:E:anaconda)
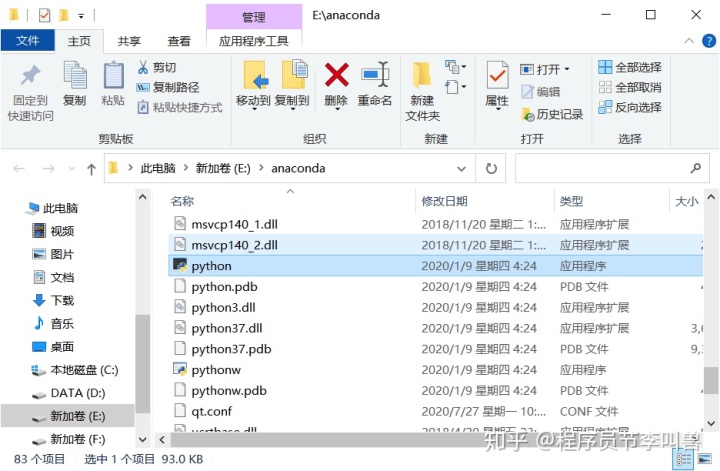
5.调试安装是否成功
操作完后,就可以使用以下代码直接调起浏览器了:
driver = new ChromeDriver();
from selenium import webdriver#导入库
browser = webdriver.Chrome()#声明浏览器
url = 'https:www.baidu.com'
browser.get(url)#打开浏览器预设网址
print(browser.page_source)#打印网⻚源代码
browser.close()#关闭浏览器selenium的基本用法
声明浏览器对象
上⾯我们知道了selenium⽀持很多的浏览器:
但是如果想要声明并调⽤浏览器则需要:
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()这⾥只写了两个例⼦,当然了其他的⽀持的浏览器都可以通过这种⽅式调⽤
访问⻚⾯
from selenium import webdriver#导⼊库
browser = webdriver.Chrome()#声明浏览器
url = 'https:www.baidu.com'
browser.get(url)#打开浏览器预设⽹址
print(browser.page_source)#打印⽹⻚源代码
browser.close()#关闭浏览器上述代码运⾏后,会⾃动打开Chrome浏览器,并登陆百度打印百度⾸⻚的源代码,然后关闭浏览器
查找元素
单个元素查找
from selenium import webdriver#导⼊库
browser = webdriver.Chrome()
#声明浏览器
url = 'https:www.taobao.com'
browser.get(url)#打开浏览器预设⽹址
input_first = browser.find_element_by_id('q')
input_two = browser.find_element_by_css_selector('#q')
print(input_first)
print(input_two)这⾥我们通过2种不同的⽅式去获取响应的元素,第⼀种是通过id的⽅式,第⼆个中是CSS选择器,结果
都是相同的。 输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="9aaa01da6545ba2013cc432bcb9abfda", element="0.5325244323105505-1")>
<selenium.webdriver.remote.webelement.WebElement
(session="9aaa01da6545ba2013cc432bcb9abfda", element="0.5325244323105505-1")>这⾥列举⼀下常⽤的查找元素⽅法:
find_element_by_name
find_element_by_id
find_element_by_xpath
find_element_by_link_text find_element_by_partial_link_text
find_element_by_tag_name
find_element_by_class_name
find_element_by_css_selector 下⾯这种⽅式是⽐较通⽤的⼀种⽅式:这⾥需要记住By模块所以需要导⼊ from selenium.webdriver.common.by import By
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = 'https://www.taobao.com'
browser.get(url)
input_1 = browser.find_element(By.ID, 'q')
print(input_1)当然这种⽅法和上述的⽅式是通⽤的,browser.find_element(By.ID,"q")这⾥By.ID中的ID可以替换为其
他⼏个 我个⼈⽐较倾向于css
多个元素查找
其实多个元素和单个元素的区别,举个例⼦:find_elements,单个元素是find_element,其他使⽤上没
什么区别,通过其中的⼀个例⼦演示:
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.taobao.com'
browser.get(url)
input = browser.find_elements_by_css_selector('.service-bd li')
print(input)
browser.close()输出为⼀个列表形式:
[<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-1")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-2")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-3")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-4")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-5")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-6")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-7")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-8")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-9")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-10")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-11")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-12")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-13")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-14")>,
<selenium.webdriver.remote.webelement.WebElement (session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-15")>,
<selenium.webdriver.remote.webelement.WebElement
(session="42d192ca36f75170ab489e4839df0980", element="0.73211490098068-16")>]当然上⾯的⽅式也是可以通过导⼊from selenium.webdriver.common.by import By 这种⽅式实现
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li') 同样的在单个元素中查找的⽅法在多个元素查找中同样存在: find_elements_by_name
find_elements_by_id
find_elements_by_xpath
find_elements_by_link_text
find_elements_by_partial_link_text
find_elements_by_tag_name
find_elements_by_class_name
find_elements_by_css_selector
元素交互操作
对于获取的元素调⽤交互⽅法
from selenium import webdriver import time
browser = webdriver.Chrome()
browser.get(url='https://www.baidu.com')
time.sleep(2)
input = browser.find_element_by_css_selector('#kw')
input.send_keys('韩国⼥团')
time.sleep(2) input.clear() input.send_keys('后背摇')
button = browser.find_element_by_css_selector('#su')
button.click()
time.sleep(10)
browser.close()运⾏的结果可以看出程序会⾃动打开Chrome浏览器并打开百度⻚⾯输⼊韩国⼥团,然后删除,重新输⼊
后背摇,并点击搜索
Selenium所有的api⽂档:
简书www.jianshu.com交互动作
将动作附加到动作链中串⾏执⾏
from selenium import webdriver
from selenium.webdriver
import ActionChains
browser = webdriver.Chrome()
url = "http://www.runoob.com/try/try.php?filename=jqueryui-api-droppable"
browser.get(url)
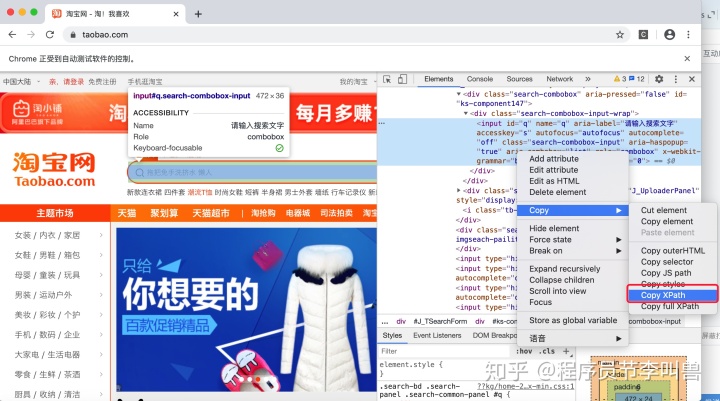
browser.switch_to.frame('iframeResult')
source = browser.find_element_by_css_selector('#draggable')
target = browser.find_element_by_css_selector('#droppable')
actions = ActionChains(browser)
actions.drag_and_drop(source, target)
actions.perform()更多操作参考:
简书www.jianshu.com执⾏JavaScript
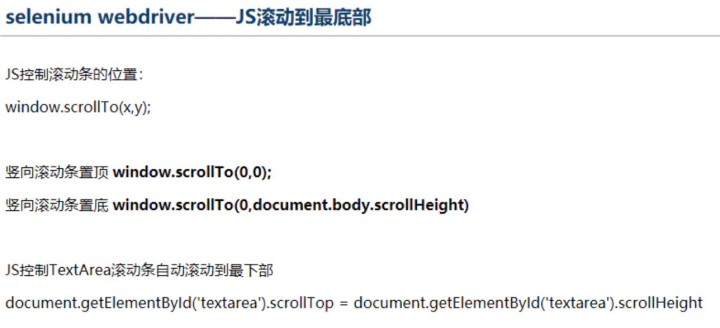
这是⼀个⾮常有⽤的⽅法,这⾥就可以直接调⽤js⽅法来实现⼀些操作,
下⾯的例⼦是通过登录知乎然后通过js翻到⻚⾯底部,并弹框提示
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.zhihu.com/explore")
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
browser.execute_script('alert("To Bottom")')获取元素属性
get_attribute('class')
from selenium import webdriver import time
browser = webdriver.Chrome()
browser.get("http://www.zhihu.com/explore")
logo = browser.find_element_by_css_selector('.zu-top-link-logo')
print(logo)
print(logo.get_attribute('class'))
print(logo.get_attribute('id'))
time.sleep(2)
browser.quit()输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="b72dbd6906debbca7d0b49ab6e064d92", element="0.511689875475734-1")> zu-top-link-logo
zh-top-link-logo获取⽂本值
text
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("http://www.zhihu.com/explore")
logo = browser.find_element_by_css_selector('.zu-top-link-logo')
print(logo)
print(logo.text)输出如下:
<selenium.webdriver.remote.webelement.WebElement (session="ce8814d69f8e1291c88ce6f76b6050a2", element="0.9868611170776878-1")>
知乎获取ID,位置,标签名
id
location
tag_name
size
from selenium import webdriver
browser = webdriver.Chrome()
url = 'https://www.zhihu.com/explore'
browser.get(url)
input = browser.find_element_by_css_selector('.zu-top-add-question')
print(input.id)
print(input.location)
print(input.tag_name)
print(input.size)输出如下:
0.022998219885927318-1
{'x': 759, 'y': 7}
button
{'height': 32, 'width': 66}xpath语法
下面列出了最有用的路径表达式:

选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
















 1883
1883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









