







前言
“这个商品不错,大家来看啊“,每个平台都有会有些大卖的商品,简称为爆品。这些商品会有个特点,就是访问量特别大。我们专业上面可以称之为热点数据,在处理这些热点商品时,系统需要做一些特殊的处理。
缓存化
针对热点商品这些类型的数据,要考虑到访问量比较大,大家首先想到的是缓存,上redis缓存,这点肯定没有错。系统框架如下: 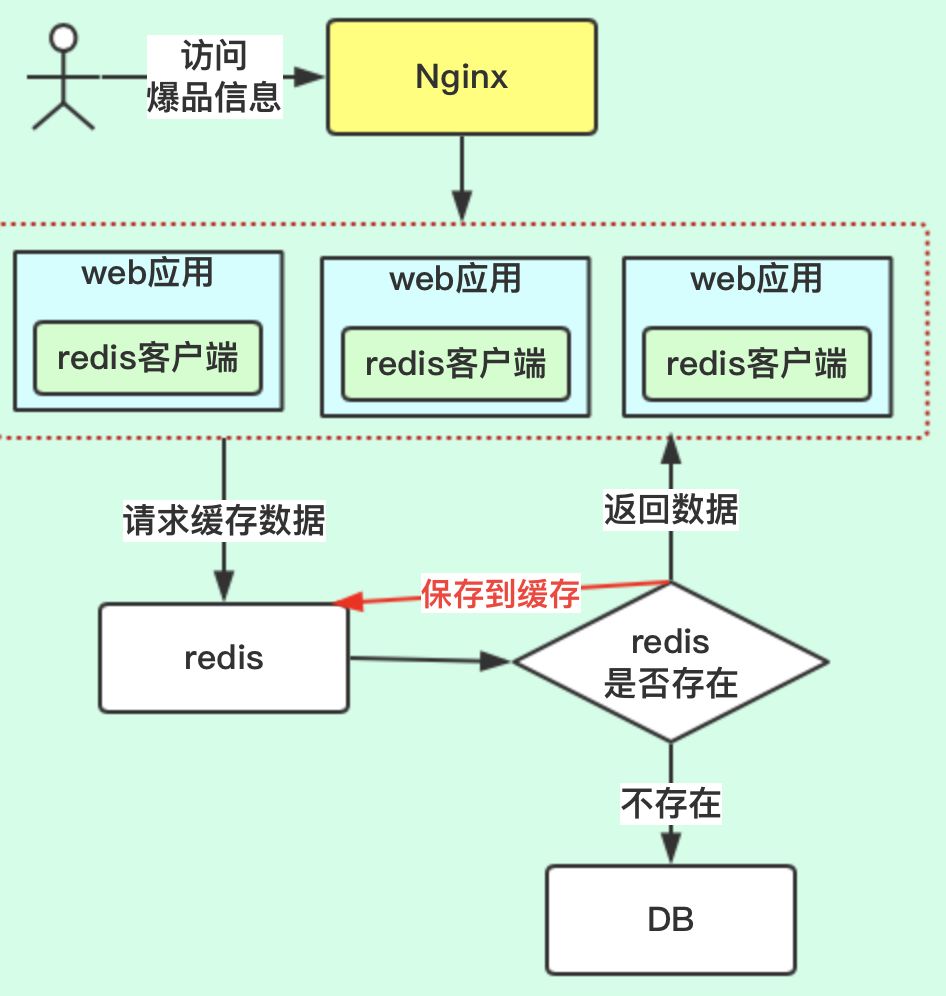 上图中,先从缓存中获取,没有再到DB获取,并保存到缓存中。但有个问题会产生,热点数据的访问会比较大,如果缓存一旦失效,所有请求同一时刻,会打到DB上面,DB肯定会崩溃。那怎么办呢?
上图中,先从缓存中获取,没有再到DB获取,并保存到缓存中。但有个问题会产生,热点数据的访问会比较大,如果缓存一旦失效,所有请求同一时刻,会打到DB上面,DB肯定会崩溃。那怎么办呢?
分布式锁
缓存一旦失效,如何重新构建缓存?首先需要避免失效那一刻大量请求同时去重新构建缓存。因为重新构建缓存,需要到数据库DB中获取数据,那一个时刻的所有请求到DB上面。方案有两种,第一个方案是把请求进入队列中(这个老顾以后会介绍,关于库存一致性的问题中,有涉及到这个知识点)。还有一个方案就比较简单,利用分布式锁,只允许一个请求线程去访问DB,其他请求阻塞,这样就避免了很多请求打到DB上。
具体怎么实现可以看老顾之前的文章【如何利用锁,防止缓存击穿?重构思想的重要性】
永不过期
这个方案就是利用redis本身的特性,导致的问题是因为缓存失效了,那我们可以让缓存永不过期就行了。这个方案中需要考虑两个情况:
1、热点商品上线前需要预热,也就是在商品正式发布到前端时,需要提前把商品信息进行缓存,避免跟缓存失效的情况一样。 2、更新商品信息机制,如何在商品信息更新后,及时更新缓存中的商品信息。这个也比较简单在更新商品事件中,增加个更新消息,由缓存服务进行消费,更新缓存信息。
遗留问题
上面两个方案是网上经常提到的方案,其实这两个方案会存在一个问题,也就是redis达到了负载极限怎么办?也就是热点商品的访问量,我们的单台redis扛不住了。
小伙伴们会有疑问,redis可以上集群啊,不就解决了吗?
我们先了解一下,redis cluster集群部署方案
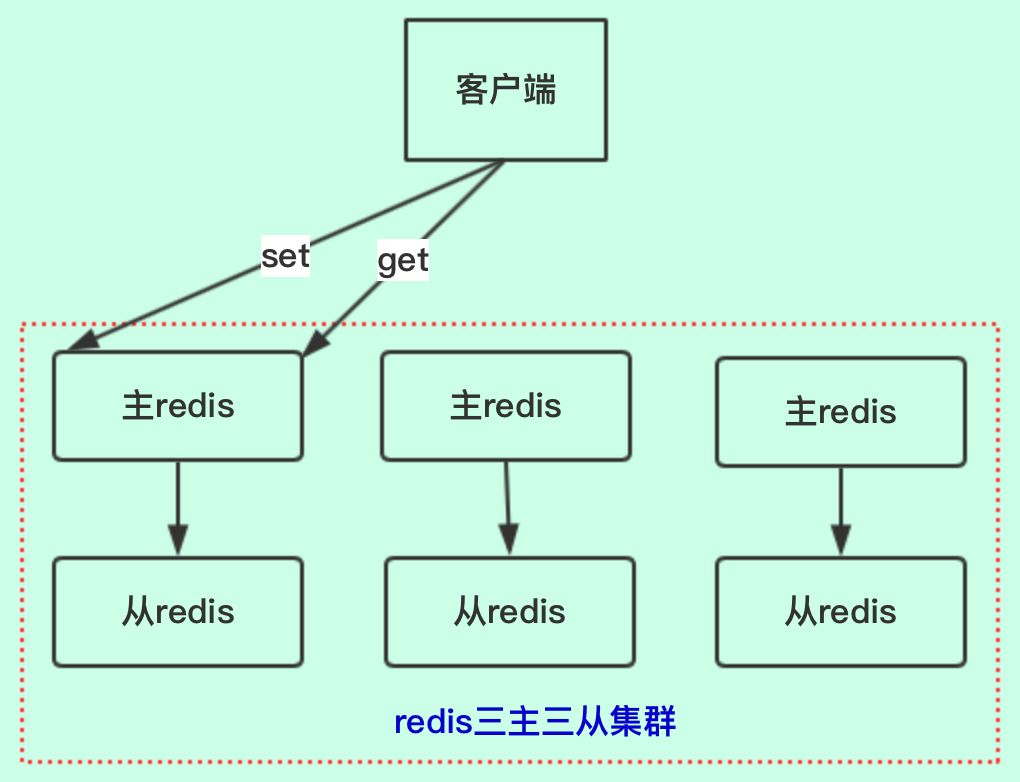
上图是redis经典的三主三从集群方案,客户端进行set和get时,都是走的主redis,从redis只是个备份,主要作用是用来做高可用的,如:主redis挂了,从redis顶上。
备注:老顾这里介绍的是redis集群部署方案,如果是之前的redis主从方案,另外讨论
从redis是不负责set和get请求的,即使请求打到从redis节点,从redis也会转发给主redis。而其他的主redis,是用来做数据扩容的。
即就是商品A的信息,只会存在一个主redis中,其他主redis是没有此商品A的信息的,这就是redis集群哈希槽的特点。
也就是小伙伴刚才想到的做redis集群这个方案是不行的,因为热点数据只会在一个主redis中。会存在单台redis负载不足(达到网卡、网络上限。达到这个瓶颈流量代表非常大了)。那怎么办呢?
读写分离
上面我们提到从redis只不负责读和写请求的,但redis官方提供了一个方法,在操作读请求时,可以先加上readonly命令,这样从redis就可以提供读请求服务了,不需要转发到主redis。
根据这个特性,我们可以对客户端工具进行改造,读请求方法时,加上readonly这个命令,从而实现读写分离,提高了从redis的利用率。
即达到了多台从redis去扛大量请求了,减少了主redis压力。这个方案需要对客户端进行改造,而且redis官方推荐没有必要使用读写分离。
本地缓存
这个方案就是多级缓存的方案,把缓存前置,架构图如下: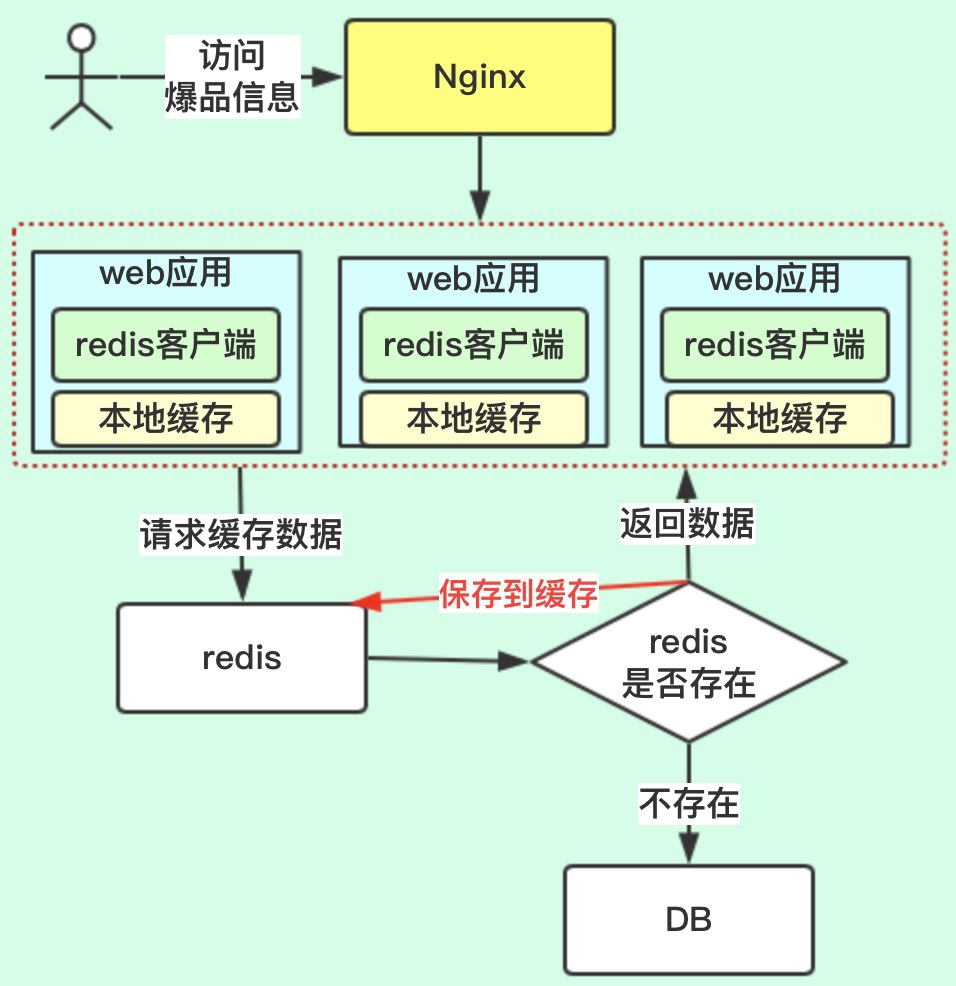 改造web应用服务,在获取到redis缓存后,在web服务本地把热点的数据进行缓存,因为热点的商品不会很多,所以保存在本地缓存中,是没有问题的。这样请求数据时,如果web本地有缓存数据,就直接返回了。
改造web应用服务,在获取到redis缓存后,在web服务本地把热点的数据进行缓存,因为热点的商品不会很多,所以保存在本地缓存中,是没有问题的。这样请求数据时,如果web本地有缓存数据,就直接返回了。
这样前端3个web应用就分担了redis缓存的压力,如访问过大就可以增加web应用服务,本来web应用服务就需要集群化
热点发现
本地缓存的方案中,有一个问题需要解决,那就是怎么知道哪些数据是热点数据?因为本地缓存资源有限,不可能把所有的商品数据进行缓存,它只会缓存热点的数据。那怎么知道数据是热点数据呢?
人为预测
就是人工标记,预测这个商品会成为热点,打个标记。web应用根据这个标记把此商品保存到本地缓存中
这个方案,是根据运营人员的经验进行预测,太不靠谱了。
系统推算
这个方案是根据实实在在的数据访问量进行推算形成,网上也介绍了用访问日志的什么算法,推算哪些是热点数据。 老顾这里分享一个比较简单的方式,就是利用redis4.x自身特性,LFU机制发现热点数据。实现很简单,只要把redis内存淘汰机制设置为allkeys-lfu或者volatile-lfu方式,再执行
./redis-cli --hotkeys
会返回访问频率高的key,并从高到底的排序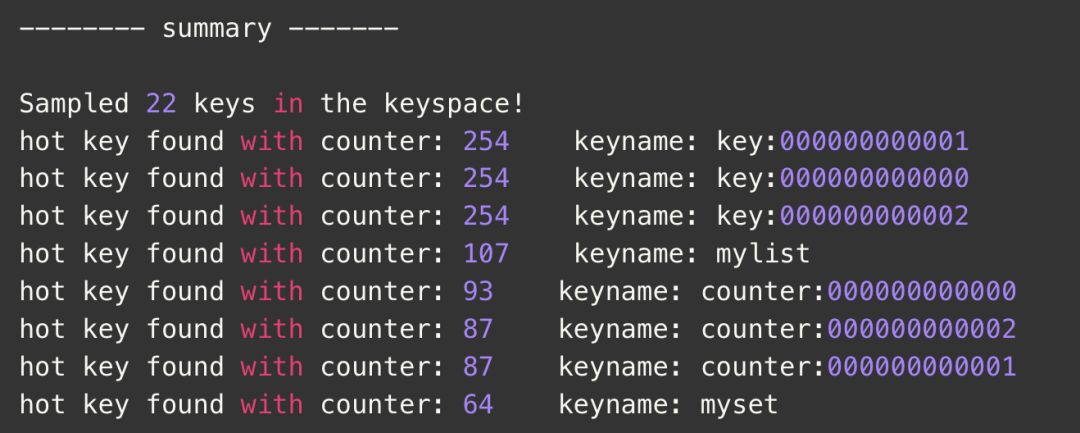 那就是我们的热点数据的key了。
那就是我们的热点数据的key了。
备注:在设置key时,需要把商品id带上,这样就是知道是哪些商品了
总结
到此为止,老顾就把热点数据的问题、解决方案以及热点发现介绍完了,希望能够帮助小伙伴。当然整个解决方案的搭建,还需要小伙伴结合自身业务去实现。
如果小伙伴们部署到阿里云上面,阿里云上面也有类似方案
谢谢大家阅读!!!
推荐阅读:














 634
634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









