





无论是在办公室还是实验室,数据匹配都是我们的日常任务。
假设一个情境来说明数据匹配的逻辑:
下图是一张【总体表】,记录了动画片《葫芦兄弟》中10位主要角色的姓名、身份和能力,这是我们需要的数据。

为了获得这张表,我们派出了两只调查小队:A和B。经过艰苦的调查,两队都没有获得【总体表】中的完整信息,而是分别得到了部分角色的身份和能力,如下所示:
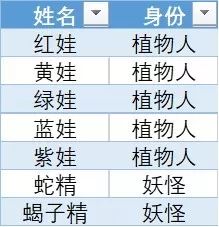 ▲ 身份表1
▲ 身份表1
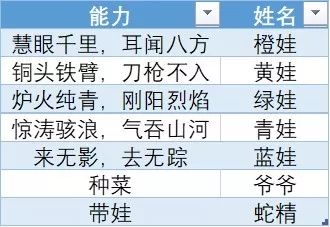 ▲ 能力表1
▲ 能力表1
如何才能将这两张表中的数据匹配起来呢?
我们发现,角色的姓名是【唯一】的,通过核对两张表中的姓名列,就能将身份和能力对应起来,我们将其称为【关键列】。
接下来,就到了数据匹配的时间。
1 方法一:VLOOKUP函数法
VLOOKUP函数的语法如下:
=VLOOKUP(查询值,数据源,显示序列,匹配参数)
其中,查询值是【关键列】或者关键列中的某一个值;数据源是另一张待匹配的表格;显示序列表示匹配完成后显示在VLOOKUP公式列的数据来自数据源的第几列;匹配参数是控制精确匹配和模糊匹配的哑元。
本例中,我们这样写公式:查询值来自本表(身份表1)的姓名列(用[@姓名]表示);数据源来自能力表1的全部数据(用能力表1[#全部]表示,[#全部]可以省略);显示序列为2,即显示能力表的第2列(能力列);匹配参数为0,即精确匹配。

得到如下结果:

可以看出,有几行没有匹配上,显示为#N/A,什么原因呢?很简单,这是因为身份表1中的红娃、紫娃和蝎子精并没有出现在能力表1中,也就是说B队没有遇到这三个人。
同时,千万不要忽略掉,能力表1中的橙娃、青娃和爷爷并没有出现在合并结果中——这种保留所有查询值、但不用展示数据源所有行的匹配方式称为【左联接】;当然,你会发现如果你需要【右联接】,只需要把查询表和数据源的位置交换一下就可以了。因此,也有人说,VLOOKUP是一种“假的”左联接。
VLOOKUP说来简单,但同学们在使用过程中常会产生2个疑问:第一,模糊查询到底有什么用?第二,能不能让没匹配上的行不显示#N/A?
针对第1个问题,模糊查询是用来查询【一段范围】而不是【一个值】的,比如我们希望将60分以下都匹配为不及格,60-69分匹配为及格,70-79分匹配为中等,80-89匹配为良好,90分以上匹配为优秀。当然,用多层嵌套的IF函数完全可以实现,但使用VLOOKUP的模糊匹配更加简单。我们建立成绩表(左)和等级表(右),写入公式如下,即可得到满意的结果。其原理是,当查询值小于数据源关键列的某一行时,返回上一行的结果。

针对第2个问题,一般有两种方法。较为常用的是使用后文将要提到的【内联接】,干脆就把没匹配上的数据行剔除掉;如果一定要保留,我们也可以使用IFERROR函数将#N/A显示为空白或其他表示缺失值的符号(比如999)。
VLOOKUP法有没有缺点呢?有。
第一,关键列必须在数据源的第1列。考虑如下能力表2,关键列(姓名)是第2列,这时想使用VLOOKUP必须先交换姓名列和能力列的位置,同学们可以自己尝试一下。
▲ 能力表2
第二,VLOOKUP没有【内联接】。如果我们只想保留匹配上的数据行,就要将出现#N/A的行手动删去或进行筛选。
2 方法二:Power Query法
Power Query是针对数据查询设计的程序,已经内嵌在Excel 2016的【数据】选项卡中。使用PQ来匹配数据就非常傻瓜了,不需要写任何公式。
为体现出PQ法的优势,我们使用葫芦兄弟的身份表1和能力表2进行内联接匹配,仅保留匹配上的行。操作如下:
第1步:打开Excel,点击【数据】选项卡—【新建查询】—【从文件】—【从工作簿】—选中存放身份表和能力表的工作簿。

第2步:在【导航器】中选中身份表和能力表,界面右侧可以预览部分数据。

完成第2步后,【工作簿查询】侧边栏就会弹出,选中表格就能看到相关属性。

第3步:在身份表上点击鼠标【右键】—【合并】。

第4步:这一步很关键。在【合并】界面,下拉【选择】左表(身份表)和右表(能力表)—在两张表上【选择】关键列(选中后会有如图的背景色)—【勾选】仅包括匹配的行(内联接)—【确定】。

第5步:点击【NewColumn列】右侧的【扩展】按钮—【选中】扩展—【勾选】能力列—【取消勾选】使用原始列名作为前缀—【确定】。

这样,数据就全部匹配好了。看似步骤很多,但由于不需要用键盘,操作起来还是非常快的。结果如下:

对于了解M函数的分析师而言,还可以直接撰写高级查询命令:

关注一下第2行的参数【JoinKind.*】,PQ提供了Inner(内联接)、LeftOuter(左外联接)、RightOuter(右外联接)、FullOuter(全外联接)、LeftAnti(左反联接)和RightAnti(右反联接)等6种主要联接方式。含义如下:

我们可以手动修改代码得到想要的效果。以全外联接为例,将代码修改为
let
源 = Table.NestedJoin(身份表2,{"姓名"},能力表2,{"姓名"},"NewColumn",JoinKind.FullOuter),
#"展开的“NewColumn”" = Table.ExpandTableColumn(源, "NewColumn", {"能力", "姓名"}, {"能力", "姓名.1"})
in
#"展开的“NewColumn”"
可以得到外联接结果:

Power Query有没有缺点呢?也是有的。这种方法过于依赖M函数,对于看不懂M函数或记不得联接名称的同学而言,很多联接方式都不能点一点就实现。
3 方法三:Power BI法
了解了Power Query后再来看Power BI就会觉得豁然开朗。本质上,Power BI就是Excel + Power Query + Power Pivot,它糅合了三者的优点;当然,也不可避免的继承了三者的不同。
Excel使用VBA语言进行编程,Power Query使用M函数进行查询,Power Pivot使用DAX函数进行透视;三者互不兼容地被Power BI继承了下来。同时Power BI本身接受Python和R语言,使用插件时还能接受Java等其他语言。灵活性是有了,但分析师地头发确实是没有了。
第1步:与Excel中类似,我们先通过【获取数据】载入身份表和能力表,再通过【编辑查询】进入Power Query界面。

第2步:点击右上角的【合并查询】进入匹配界面。可以看出,这里我们是可以通过鼠标点击【联接种类】下拉菜单去选择6种主要联接方式的,这就非常方便了。

Power BI匹配数据只能做到这个程度了吗?还差得远呢,Power BI能直接实现复合关键列匹配。如果我们使用VLOOKUP进行匹配,查询值必须是唯一的;考虑以下表格,班级和学号都不能作为关键列,常见的做法是用&将两个单元格合并作为关键列。

在Power BI中就不需要这么麻烦了,在合并界面按住【Ctrl】点多列就行。

需要提醒同学们注意,Power BI中还有一个功能叫【关系】,其内在逻辑跟合并很像,但只建立关联而不真的合并为一张新的表,更多地用在一对多的数据下钻上,千万不要混淆。
4 其他合并方法
除了使用Excel合并数据外,还有一些我们课内介绍过的工具可以实现合并操作。
Python
import pandas as pd
data1 = pd.read_csv(r'd:\data1.txt',sep='\t',header=0)
data2 = pd.read_csv(r'd:\data2.txt',sep='\t',header=0)
# 匹配
data1.merge(data2,on='姓名',how='outer')
R
data1"d:\\data1.txt",header=TRUE,fileEncoding="utf-8")
data2"d:\\data2.txt",header=TRUE,fileEncoding="utf-8")
# 匹配
merge(data1,data2,by="姓名",all=TRUE)
Python和R的优点在于,当匹配前两张表中的关键列具有相同的标签时,匹配后会自动将关键列合并。
Stata
. use "D:\data1.dta"
. merge 1:1 姓名 using "D:\data2.dta"
/* 结果:
Result # of obs.
-----------------------------------------
not matched 6
from master 3 (_merge==1)
from using 3 (_merge==2)
matched 4 (_merge==3)
-----------------------------------------
*/
Stata默认使用外联接,但会新生成一列_merge来区分哪些是左反联接(_merge==1)、右反联接(_merge==2)和内联接(_merge==3);在命令中,我们可以直接使用keep选项来控制联接方式,比如keep(match master)就是左外联接,keep(match using)就是右外联接。
注意,Python、R和Stata都只能认Excel工作表,而不认Excel表。
Tableau
使用Tableau匹配数据是最简单的,因为这个软件将合并数据做在了数据载入页面;换言之,当你载入两个数据表的时候,Tableau立刻就会问你——要不要合并一下啊?还贴心地用图示地方式给出4种基本联接方式。

5 结束语
经过今天的学习,往后我们在合并数据时可以考虑更加合适的手段,不必因为不会使用VLOOKUP函数而着急。Excel还有很多的功能等待大家去挖掘,老办法不一定总是好办法。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









