





DSOD: Learning Deeply Supervised Object Detectors from Scratch(ICCV17)论文链接arxiv.org
一、概述
这篇论文首次提出了一种能从零开始训练的目标检测模型(DSOD)。作者使用了DenseNet 的设计理念设计了 Backbone, 这种密集连接的网络能够为检测器提供深度的监督,避免梯度消失。参照 SSD 的网络结构设计了 DSOD。
(一)先前的不足
对于先前的目标检测模型的 backbone 会在 ImageNet 数据集上预训练然后再在检测数据集上进行微调。通过这种方式可以快速的训练得到最终的模型。但是会存在如下问题:
1)Limited structure design space:为了使用经过预训练的模型。只能使用那些针对 ImageNet 分类任务设计的模型结构。这些模型通常都大,含有巨大的参数量。而且因为要使用预训练的权重。对于网络的结构,也不能灵活的更改。
2)Learning bias:因为分类和检测是不同的任务。所以对于预训练的 Backbone 在检测数据集上微调时会学习两个任务之间的偏差。
3)Domain mismatch:尽管微调可以减少不同任务分布的差异性,但是对于一些目标域如深度图、医学图像等和 ImageNet 的差异性太大, 微调效果不理想。
(二)本文的贡献
1)提出 DSOD 可以从零开始训练目标检测
2)介绍了一系列的能从零训练模型的设计原则,并做了大量的实验。
3)在 VOC2007、VOC2012、COCO 数据集上测试,并和其他模型对比。
二、模型设计原则
如果要设计一个能从零开始训练的目标检测模型。那么有没有什么设计规律或原则呢?作者通过大量实验。总结出了如下 4 条设计原则:
(一)Proposal-free:
R-CNN 和 Fast-RCNN 额外需要 proposal 提取方法,Faster-RCNN 和 R-FCN 需要RPN 提取 Proposal。YOLO 和 SSD 无需 Proposal,经过实验观察发现,基于候选区域提取的方法无法从零开始训练,不收敛。只有 Proposal-free 方法可以从零开始训练并收敛。作者认为是 ROI pooling 的存在使梯度不能平稳地从 region-level 传递到 feature map。然而对预训练模型 fine-tuning 可以收到比较好的结果是因为 ROI pooling 之前的层拥有一个比较好的初始值,而不需要随机赋初值,这个在 train from scratch 时是不存在的。
(二)Deep Supervision:
深层监督学习,核心思想是提供一个集成的 objective function,也就是损失函数不仅要给输出层提供监督信号,还要对网络中前面的非输出层提供监督信号,这样可以减轻梯度消失问题。我们很显然的想到了 ResNet 和 DenseNet 都是符合这个要求的,二者都存在 skip-connection。论文主要是参考 DenseNet 中致密层级连接,致密的块是当前块与其之前所有块有连接,而且更多的 skip connections 实现 supervised signals 传递。这样,DenseNet中的浅层可以收到目标函数的监督。
Transition w/o Pooling Layer 这个层用来增加 dense blocks 数量。 原来的 DenseNet 的 dense blocks 数量是固定的。
(三)Stem Block:
作者发现,如果网络使用 stem 也会提高最后的检测效果。这可能归咎于 stem 可以减少信息相对原图的损失。作者使用了三个 3 x 3 的卷积层替代了 Denset 中 7 x 7 的卷积层。

(四)Dense Prediction Structure:
对于网络的输出,作者借鉴 Densenet 的思想,融合多个阶段网络的输出。对于 SSD 而言,每一阶段的输出是顺序连接。对于 DSOD 每一阶段的输出都融合了前面所有阶段的输出。
因为 feature map 的大小不同(需要融合多尺度的 feature map),所以需要进行下采样。下采样使用: 2 x 2,stride 为 2 的池化。因为拼接会使通道数快速增长。所以后面再接一个 1 x 1 的卷积操作,用于减少通道数为原来一半。
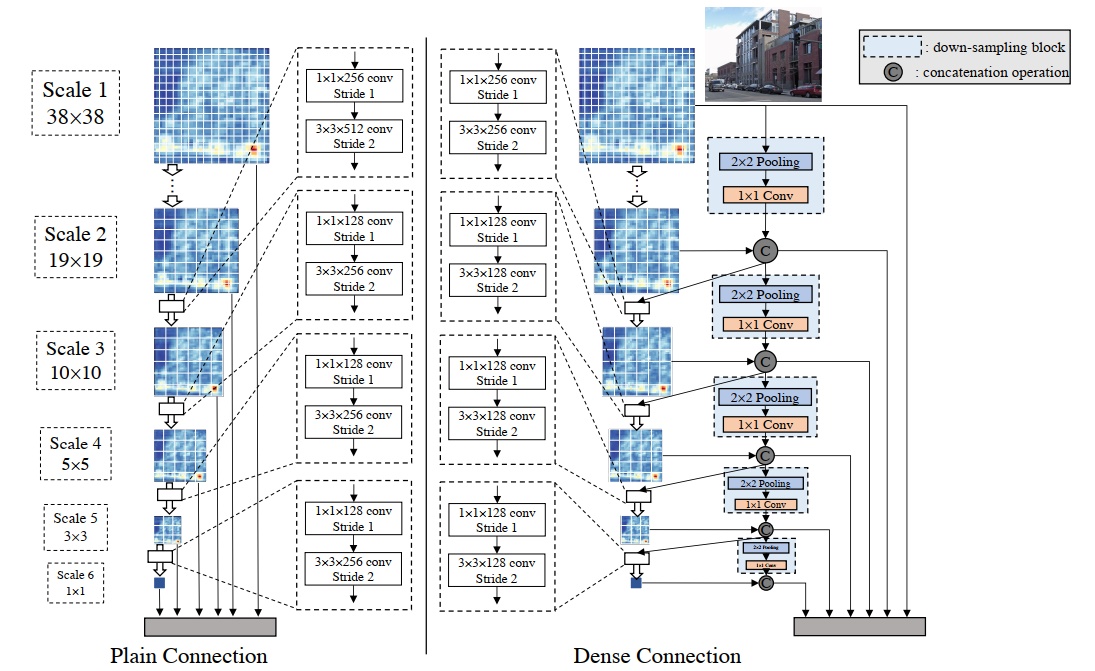
下图为 SSD(左) 和 DSOD(右) 的连接方式。其中上图的结构可以看做一条 DenseNet 中的连接线。那么对于 6 个输出。每一个输出都由之前所有阶段输出的 feature map 融合而来。
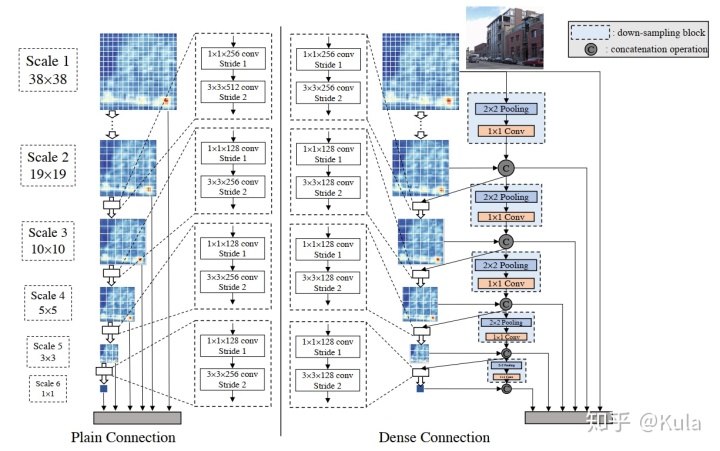
每个尺度输出的通道数与预测特征图个数相同。在DSOD中,对每个尺度,每一个scale中的feature map(channel)中只有一半是通过前面层学习得到的,还有一半是直接通过降采样得到的。下采样块中池化层降低分辨率,卷积层将通道数减半。每个尺度仅学习半数的特征图,复用之前层的另一半。大大减少了模型的参数量,特征包含更多信息。
三、网络结构
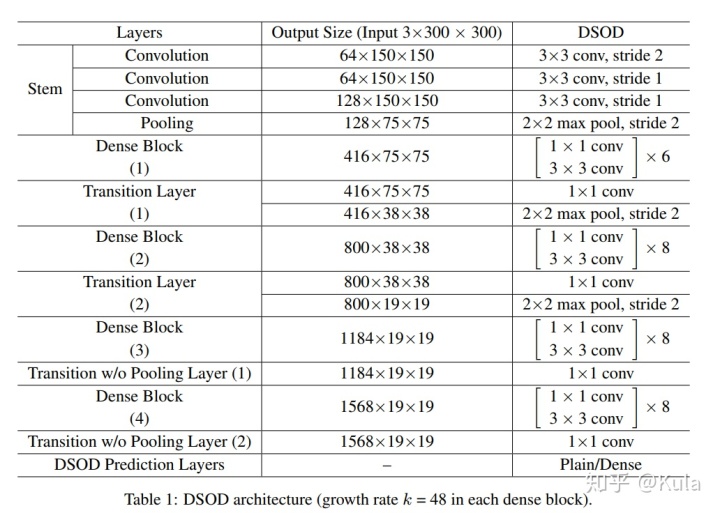
DSOD 不管是在 backbone 还是在网络的连接方式上都借鉴了 DenseNet 的设计思想。
DSOD 网络分两个部分: 用于特征提取的 backbone,用于目标预测的 front-end。backbone 子网络类似于 DenseNet,包含 Stem block,4 个 dense block,2 个过渡层,2个无池化层的过渡层。front-end 子网络使用致密的结构融合多尺度预测响应。
四、实验结果
表二为 VOC2007 test set 上的消融实验:DS/A-B-k-θ 代表了 backbone 的结构。A 代表了第一个卷积层的通道数。B 代表了 1 x 1 bottleneck layer(1×1 卷积层)的通道数。k 为 dense blocks 的 growth rate。θ 为 transition layers 的 compression factor。
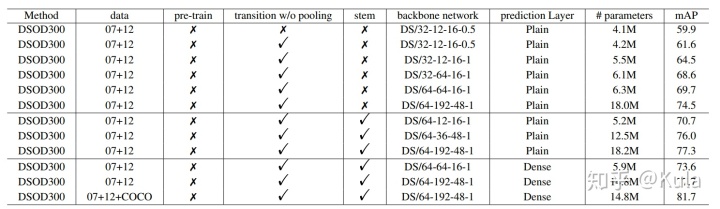
VOC 07+12

MS COCO test-dev 2015
















 1074
1074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









