






人工智能 Python 编程特训营 第四个主题项目代码
一、项目要求
本次项目是抓取今日头条热点以及文章中标签内容。
二、页面分析
今日头条页面采用了AJAX技术,通过浏览器开发者工具,可以找到实际请求地址。

请求参数:
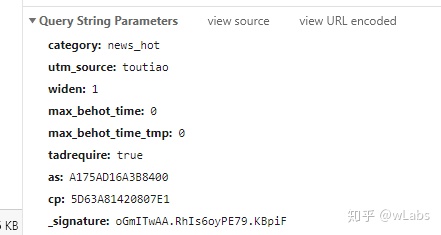
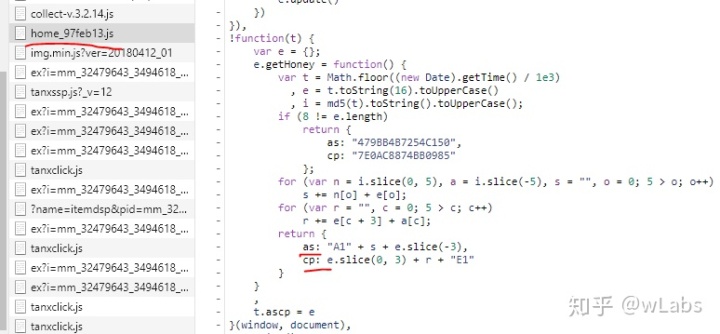
主要有max_behot_time(max_behot_time_tmp):请求时的时间戳,python中可通过time.time()取得;as,cp是对max_behot_time加密,算法可阅读网站的js文件,
参数_signature使用了TAC.sign(), 百度了也没有找到好的方法。经过尝试,请求中没有这个参数也能抓取到页面内容。
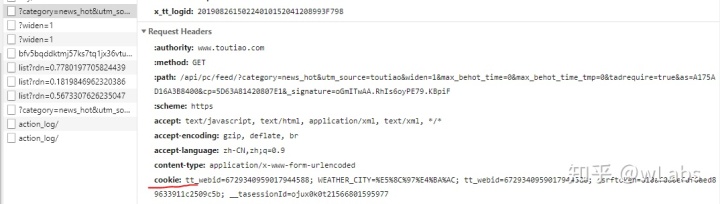
请求中应该有cookie, 能够保证多页抓取时数据的统一(不带cookie抓取,多页时有些文章会出现重复),cookie可以通过selenium方法获得,这儿简单起见,直接在浏览器中复制一个,因为抓取时间较短,暂不考虑cookie的时效性,cookie内容为
请求返回的是json数据:
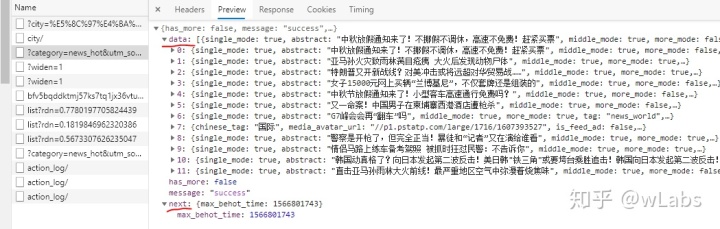
其中data中是当前网页的标题内容,next是下一页的max_behot_time。
三、实现代码
3.1 开发工具
win10 + anaconda3 + PyCharm + jupyter notebook
3.2 项目
3.3 utils.py文件
utils.py中函数功能是抓取多种浏览器user-agent列表和代理服务器列表,并随机得到user-agent和代理ip.
# utils.py
import requests
import json
import random
import re
import hashlib
# 抓取不同的user-agent, 并写入文件
def write_useragent_info_to_file():
user_agent_json = requests.get("https://fake-useragent.herokuapp.com/browsers/0.1.11")
with open("data/useragent.txt", "w", encoding="utf-8") as f:
json.dump(user_agent_json.text, f, ensure_ascii=False)
write_useragent_info_to_file() # 执行一次就行了
# 从文件useragent.txt中拿到user-agent列表
def get_useragent_list():
with open("data/useragent.txt", "r", encoding="utf-8") as f:
useragent_json = json.load(f)
useragent_dict = json.loads(useragent_json)
useragent_dict = useragent_dict["browsers"]
useragent_list = [x for key in useragent_dict.keys() for x in useragent_dict[key]]
return useragent_list
# 从一个useragent列表中随机得到一个带user-agent的header函数
def get_random_headers(useragent_list):
user_agent = random.choice(useragent_list)
headers = {"user-agent": user_agent}
return headers
# 抓取代理服务器, https://www.kuaidaili.com/free
# 学习用,只抓一页,因代理服务器有时效,就不保存为文件
def get_proxies_list():
proxies_html = requests.get("https://www.kuaidaili.com/free")
ip = re.findall('data-title="IP">(d+.d+.d+.d+)',proxies_html.text)
port = re.findall('data-title="PORT">(d+)',proxies_html.text)
proxies_list =[]
for i in range(len(ip)):
tmp = "http://" + ip[i] + ":" + port[i]
proxies_list.append(tmp)
return proxies_list
# 从代理服务器列表中得到一个随机代理服务器
def get_random_proxies(proxies_list):
proxies_ip = random.choice(proxies_list)
proxies = {"http": proxies_ip}
return proxies
# 该函数主要是为了获取as和cp参数
def get_as_cp(html_id):
zz = {}
e = hex(html_id).upper()[2:] #hex()转换一个整数对象为16进制的字符串表示
a = hashlib.md5() #hashlib.md5().hexdigest()创建hash对象并返回16进制结果
a.update(str(html_id).encode('utf-8'))
i = a.hexdigest().upper()
if len(e)!=8:
zz = {'as':'479BB4B7254C150', 'cp':'7E0AC8874BB0985'}
return zz
n = i[:5]
a = i[-5:]
r = ''
s = ''
for i in range(5):
s= s+n[i]+e[i]
for j in range(5):
r = r+e[j+3]+a[j]
zz ={'as':'A1'+s+e[-3:], 'cp':e[0:3]+r+'E1'}
return zz3.4 toutiao_spider.py文件
爬取网页主文件。
import requests
import json
import pandas as pd
import re
import utils
import urllib
import time
# 对应max_behot_time值(时间戳)的网址,第一页值为0,下页的值见返回的response中的next
def get_request_url(html_id, myas, cp):
query_data = {
'category': 'news_hot',
'utm_source': 'toutiao',
'widen': 1,
'max_behot_time': html_id,
'max_behot_time_tmp': html_id,
'tadrequire': 'true',
'as': myas,
'cp': cp
#'as': 'A1A5CD16F22464B',
#'cp': '5D62C446D40B5E1',
#'_signature': '4is.7AAAv1QK8R2RWAlOReIrP.'
}
return "https://www.toutiao.com/api/pc/feed/?" + urllib.parse.urlencode(query_data)
useragent_list = utils.get_useragent_list() # 从文件data/useragent.txt中获得user-agent列表
proxies_list = utils.get_proxies_list() # 从https://www.kuaidaili.com/free上抓取代理ip列表
# 从浏览器中复制cookie
cookies ={
"tt_webid":"6729340959017944588",
"WEATHER_CITY":"%E5%8C%97%E4%BA%AC",
"tt_webid":"6729340959017944588",
"csrftoken":"810af0a0efdf6aed89633911c2509c5b",
"__tasessionId":"le9d3pcxp1566867524906"
}
# 得到response函数
def get_response_html_json(html_id, myas, cp):
request_url = get_request_url(html_id, myas, cp)
headers = utils.get_random_headers(useragent_list)
proxies = utils.get_random_proxies(proxies_list)
response = requests.get(request_url, headers=headers, proxies=proxies,cookies=cookies)
global response_json
response_json = json.loads(response.text)
if response_json["message"] == "error":
get_response_html_json(html_id, myas, cp)
return response_json
N = 2 # 抓取页数,学习之用
df = pd.DataFrame()
html_id = int(time.time())
for i in range(N):
ascp = get_as_cp(html_id)
response_json = get_response_html_json(html_id, ascp['as'], ascp['cp'])
data = response_json["data"]
data_json = json.dumps(data, ensure_ascii=False)
html_id = response_json["next"]["max_behot_time"]
df_tmp = pd.read_json(data_json)
df = df.append(df_tmp, ignore_index=True)
# 内容保存至文件
df.to_excel("data/toutiao.xlsx")
# 拿到文章中的标签
def get_article_taginfo(url):
headers = utils.get_random_headers(useragent_list)
proxies = utils.get_random_proxies(proxies_list)
response = requests.get(url, headers=headers, proxies=proxies)
response1 = re.sub("s+","",response.text) # 去掉空白字符
res = re.findall('"name":"(w+)"', response1)
return res
# 从文件data/toutiao.xlsx中读取所抓取内容
df = pd.read_excel("data/toutiao.xlsx")
url = [] # 抓取网页中的标题所对应的网址
for i in range(len(df)):
source_url = df.loc[i]["source_url"]
url.append("https://www.toutiao.com/a" + re.findall(r"d+", source_url)[0] + "/")
# 存放标签,第1列为文章标题,第2列为url, 第3列为文章中标签
dat = pd.DataFrame(
{"title": df["title"],
"url": url})
taginfo =[] # 文章标签
for i in range(len(dat)):
taginfo.append(get_article_taginfo(dat['url'][i]))
dat["taginfo"] = taginfo
dat.to_excel("data/toutiao_article_taginfo.xlsx") # 保存至文件四、抓取结果展示
4.1 data/toutiao.xlsx文件

注:有些列已经隐藏。
4.2 data/toutiao_article_taginfo.xlsx文件
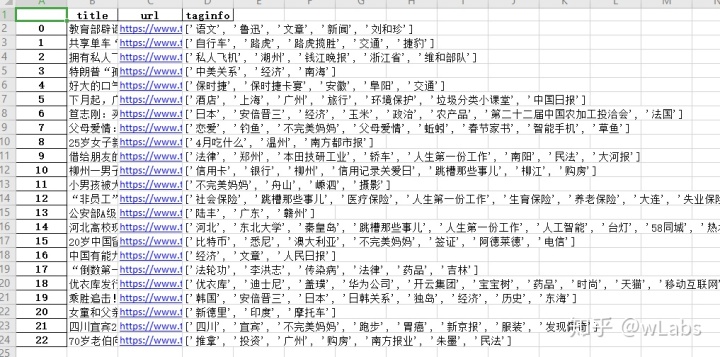
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









