





背景:
需要读取一个csv文件,并将其数据保存在dictionary中,并按照读文件的顺序输出,且不能引用第三方包,只能使用python自带模块。输出格式如下:
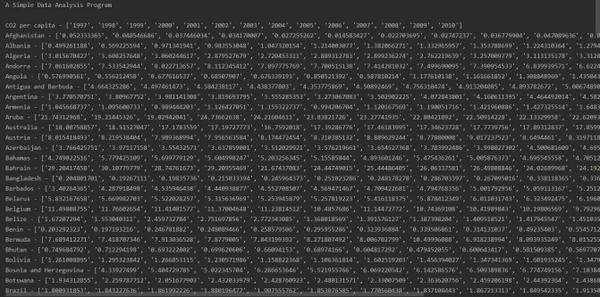
在使用python的dictionary结构时,发现输出顺序跟输入顺序不一样,而场景需要的是输出顺序跟输入顺序一致。
分析:
从python2.7官方文档得知,dictionary是无序存储的,所以并不能保证输出顺序跟输入顺序完全一样。
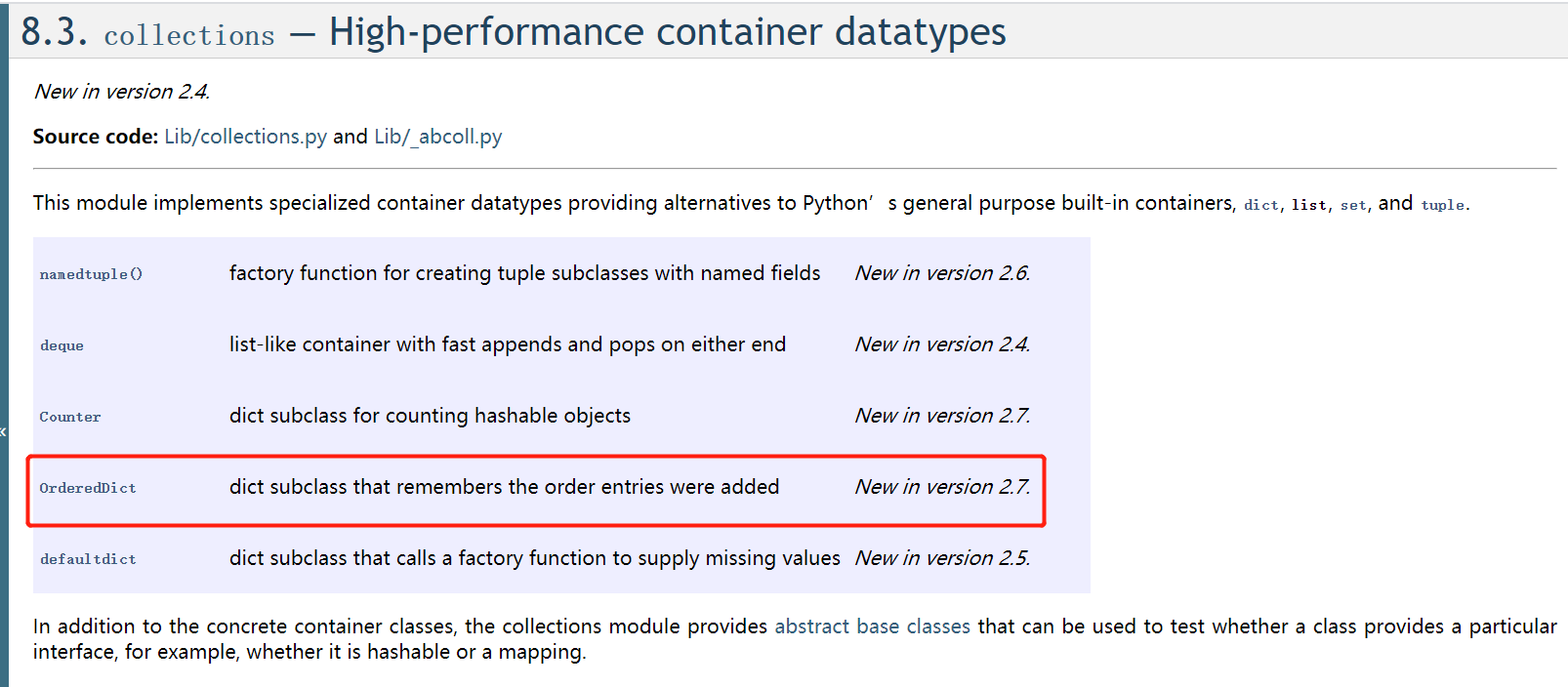
但是python2.7同时也提供了另一种扩展的存储对象collection.OrderedDict(),可以记录dict的添加顺序,并按照添加顺序输出。
另外,我们也可以在把数据添加到字典时用list来保存添加的key值,然后输出时按照list的key值顺序输出。
下面,就是这两种方式的实现步骤。
实现:
1)通过引用python自带的collection模块,声明collection.OrderedDict()对象,将csv文件每行的第一个字段作为key,其他字段作为value(list格式),顺序添加至字典对象dcitT中,之后按照格式输出。
1 importcollections2
3 defmain():4 f = open('Emissions.csv')5 line =f.readlines()6 #声明对象
7 dictT =collections.OrderedDict()8 for tmp inline:9 tmp = tmp.rstrip("\n")10 dictT[tmp.split(",")[0]] = tmp.split(",")[1:]11 f.close()12 keys =dictT.keys()13 for key inkeys:14 value =dictT[key]15 print key, '-', value
2)仍然声明为无序存储的dict()对象,在添加数据至字典对象dictT中时,并将key值添加至list对象listT,之后输出时去listT的值输出对象的字典value。
1 defmain():2 f = open('Emissions.csv')3 line =f.readlines()4 dictT =dict()5 listT =[]6 for tmp inline:7 tmp = tmp.rstrip("\n").split(",")8 dictT[tmp[0]] = tmp[1:]9 list.append(listT,tmp[0])10 f.close()11 for key inlistT:12 value =dictT[key]13 print key, '-', value
结果:
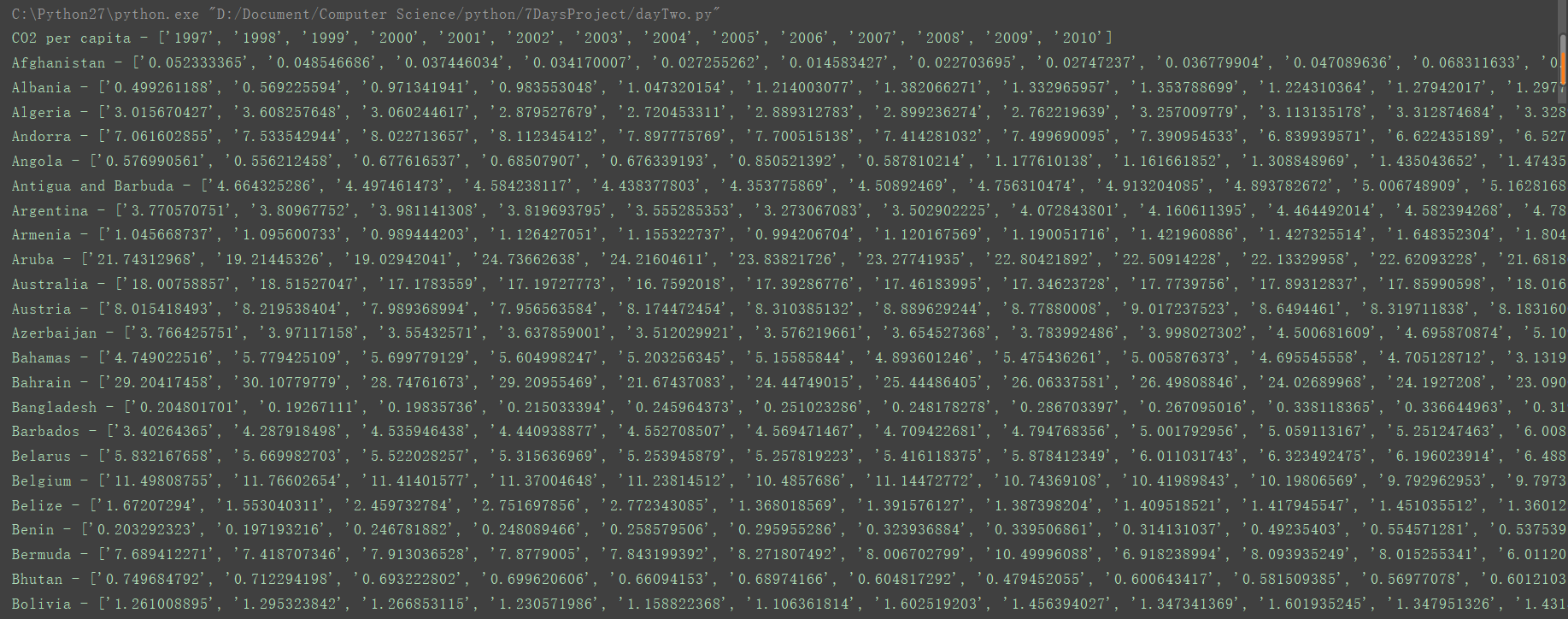















 1382
1382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









