






一、聚类的概念
聚类分析是在数据中发现数据对象之间的关系,将数据进行分组,组内的相似性越大,组间的差别越大,则聚类效果越好。我们事先并不知道数据的正确结果(类标),通过聚类算法来发现和挖掘数据本身的结构信息,对数据进行分簇(分类)。聚类算法的目标是,簇内相似度高,簇间相似度低
二、基本的聚类分析算法
1. K均值(K-Means):
基于原型的、划分的距离技术,它试图发现用户指定个数(K)的簇。
2. 凝聚的层次距离:
思想是开始时,每个点都作为一个单点簇,然后,重复的合并两个最靠近的簇,直到尝试单个、包含所有点的簇。
3. DBSCAN:
一种基于密度的划分距离的算法,簇的个数有算法自动的确定,低密度中的点被视为噪声而忽略,因此其不产生完全聚类。
三、距离量度
不同的距离量度会对距离的结果产生影响,常见的距离量度如下所示:


四、K-Means
在聚类算法中K-Means算法是一种最流行的、使用最广泛的一种聚类算法,因为它的易于实现且计算效率也高。聚类算法的应用领域也是非常广泛的,包括不同类型的文档分类、音乐、电影、基于用户购买行为的分类、基于用户兴趣爱好来构建推荐系统等。
优点:易于实现
缺点:可能收敛于局部最小值,在大规模数据收敛慢
算法思想:
1 选择K个点作为初始质心2 repeat3 将每个点指派到最近的质心,形成K个簇4 重新计算每个簇的质心5 until 簇不发生变化或达到最大迭代次数
这里的重新计算每个簇的质心,更新过程是:首先找到与每个点距离最近的中心点,构成每个中心点划分的k个点集,然后对于每个点集,计算点的均值代替中心点。
如何计算是根据目标函数得来的,因此在开始时我们要考虑距离度量和目标函数。
考虑欧几里得距离的数据,使用误差平方和(Sum of the Squared Error,SSE)作为聚类的目标函数,两次运行K均值产生的两个不同的簇集,我们更喜欢SSE最小的那个:
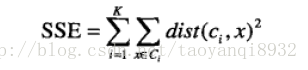
k表示k个聚类中心,ci表示第几个中心,dist表示的是欧几里得距离。
前面说的我们更新质心是让所有的点的平均值,这里就是SSE所决定的:

因此K-Means算法的实现步骤,主要分为四个步骤:
1、从样本集合中随机抽取k个样本点作为初始簇的中心。
2、将每个样本点划分到距离它最近的中心点所代表的簇中。
3、用各个簇中所有样本点的中心点代表簇的中心点。
4、重复2和3,直到簇的中心点不变或达到设定的迭代次数或达到设定的容错范围。
五、k-means代码实现
本文采用sklearn来实现一个k-means算法的应用,细节的底层实现可见文末第一个链接。
1.首先使用sklearn的数据集,数据集中包含150个随机生成的点,样本点分为三个不同的簇:
1 from sklearn.datasets importmake_blobs2 importmatplotlib.pyplot as plt3
4
5 if __name__ == "__main__":6 '''
7 n_samples:代表样本点的个数8 n_features:表示每个样本由两个特征组成9 center:表示样本点中心的个数(簇)10 cluster_std:表示每个样本簇方差的大小11 '''
12 x,y = make_blobs(n_samples=150,n_features=2,centers=3,13 cluster_std=0.5,shuffle=True,random_state=0)14 #绘点
15 plt.scatter(x[:,0],x[:,1],marker="o",color="blue")16 #以表格的形式显示
17 plt.grid()18 plt.show()
效果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









