





这篇说一下pandas,numpy主要做矩阵处理工作,pandas主要做数据处理,pandas在后续python数据处理工作中占挺大一部分比例,本篇就记录一下pandas的基础操作。(说明一下,本篇主要记录pandas的数据处理方式,所做的数据处理和本数据集没有任何联系。)
pandas 的主要数据类型为Series和DataFrame。Series是一维数据,有点像是带着索引的ndarry,DataFrame为矩阵格式,而且每一列有不同的数据格式,这点与ndarry明显差别,而且DataFrame行与列均具有索引。
一、数据读取
接下来用pandas读取一个csv格式的文件,泰坦尼克的数据。
import pandas as pd
titanic = pd.read_csv('train.csv')首先导入pandas库,并且为了方便使用,进行重命名。
然后使用read_csv方法对文件进行读取。
使用head方法,默认显示数据的前5行。
titanic.head()
这样方便我们快速了解数据。也可以读取后几行。
titanic.tail(3)#读取尾巴
titanic.info()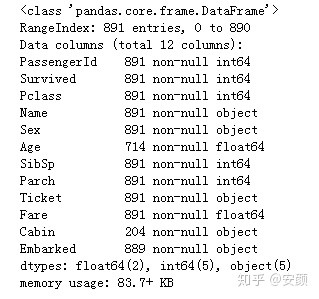
二、索引
接下来是数据索引,需要用到loc函数。
titanic.loc[0]
DataFrame会将首行默认为是列名,想要取某一列的数据,只需传入该列的列名即可。
titanic['Name']
titanic.iloc[[1,4],[3,5]]
提取列名columes方法,将数据的列名进行提取,tolist方法可以将提取的列名生成为list格式。
titanic.columns.tolist()
做一个对本数据毫无意义,不过以后可能用到的,对列名进行筛选,然后将筛选过的列名对数据进行索引,随便选个例子,找出以e结尾的列名,并且进行数据索引。
columns = titanic.columns.tolist()
new_columns = []
for i in columns:
if i.endswith('e'):
new_columns.append(i)
new_df = titanic[new_columns]
new_df.head()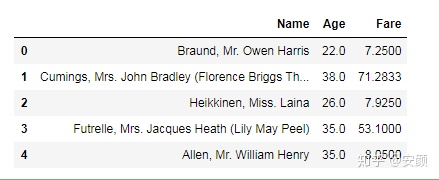
三、运算
和ndarry一样,可以对浮点型或整数型数据进行加减乘除运算。
titanic.Fare*10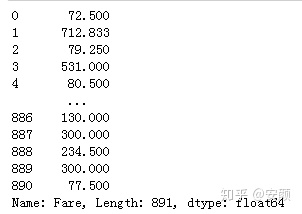
或者两个整数或浮点型的列进行加减乘除,会将对应位置的列的数据进行处理。
titanic.PassengerId*titanic.Fare
titanic['new_column'] = titanic.PassengerId*titanic.Fare
titanic.head()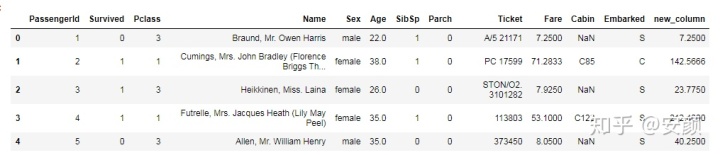
可以将处理过新生成的列增加近DataFrame。
print(titanic['Age'].max())
print(titanic['Age'].min())
print(titanic['Age'].mean())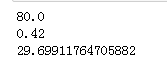
和numpy类似,可以对需要的列求最大值、最小值,平均值等
四、数据处理。
对制定列进行排序,适用sort_values方法。Age为指定要排序的列。inplace=True,为新生成一个DataFrame。ascending=Fales为从大到小排。默认为True从小到大排。空值会按最小值进行计算。
titanic.sort_values('Age',inplace=True,ascending=False)
titanic.Age
缺失值判断,使用isnull函数。
titanic.Age.isnull()
对缺失值进行补充用到fillna函数。
titanic['Age']=titanic['Age'].fillna(titanic['Age'].mean())
titanic.Age.isnull()#使用平均值对空值进行填充。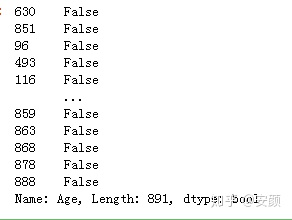















 655
655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









