





本篇聊下Python对pdf的各种操作,包含pdf转word,pdf转图片,pdf翻转,加密,加水印等。

pdf转换word文档 保留格式
pdf转换为word文档,被大众经常使用的是纯Python库pdfminer和python-docx搭配使用,不过pdfminer转换成word,会丢失原来的pdf格式(图片和样式会丢失),只能是一个纯文本的。
比如下面是一个pdf文档,是一个目录索引样式。

使用pdfminer和python-docx转换的话样式会丢失,如下。

为了研究怎么保留样式,我花了好些时间,最终测试验证了一种能接受的方案:使用libreoffice
libreoffice是一个免费的办公软件,能打开和操作docx,ppt,pdf等,提供不同文档格式之间的转换,而且支持命令行。
支持命令行的话,我们就能通过python的os.system()等方法调用libreoffice软件去做文档转换工作了。
首先要安装libreoffice:
下载地址如下:
https://zh-cn.libreoffice.org/download/libreoffice-still/
windows,linux,max三种版本都有。
安装成功后,在libreoffice/program 目录下面有个soffice.exe命令,我们就是用python调用soffice来做pdf和word转换。来测试一下pdf转word功能。
import osos.system('D:Program Fileslibreofficeprogramsoffice --infilter=writer_pdf_import --convert-to docx D:codepdfss.pdf --outdir D:codepdf')上面的命令是把ss.pdf 转换成docx格式,保存在D:codepdf 目录里,文件名是跟pdf同名,只是文件会变成.docx 。
来打开转换后的docx文档看一下,样式保留得还可以,要用office2007以上版本打开,office2003的打开样式有问题。

libreoffice转换的缺点是,不报错,你不知道是否转换成功。还有表格和多图的转换还有瑕疵。转换耗时会随着文档页数快速增加。
pdf转word文档 不保留格式
不保留格式,只需要文本的话,就直接使用 pdfminer和python-docx两个库搭配就好。pdfminer把pdf里的文字内容抽取出来,python-docx负责把抽取出来的写进word文档里。
from pdfminer.pdfinterp import PDFResourceManagerfrom pdfminer.converter import TextConverterfrom pdfminer.layout import LAParamsfrom pdfminer.pdfinterp import process_pdffrom io import StringIOffrom docx import Documentdef remove_characters(content): mpa = dict.fromkeys(range(32)) return content.translate(mpa) def convert_pdf_to_txt(path): with open(path,'rb') as f: rsrcmgr = PDFResourceManager() retstr = StringIO() laparams = LAParams() device = TextConverter(rsrcmgr, retstr, laparams=laparams) process_pdf(rsrcmgr, device, f) text = retstr.getvalue() device.close() retstr.close() return text def convert_txt_to_doc(text, doc_path): doc = Document() for line in text.split(''): paragraph = doc.add_paragraph() paragraph.add_run(remove_characters(line)) doc.save(doc_path)def convert(): text = convert_pdf_to_txt('d:/sphinx_doc_zhcn.pdf') convert_txt_to_doc(text, 'd:/test.docx')convert()写进word文档之前要把内容split分行,不然内容全都在一行,没有段落。还有要删掉一些乱七八糟的控制字符,不然保存word文档的时候要报错。
当然你需要使用pip install pdfminer 和 python-docx 这两个库。
pdf转图片
把pdf转换成图片的方案很多,比如wand库、PythonMagick等都能实现,pdf转图片的方案选择主要是考虑转换性能和图片质量上。转换一个几百K的pdf文档分辨不出哪个好使,如果是批量转换成百上千个pdf文档,又或者是转换一个几十M大小的pdf文档时就有优劣。
如果想程序简单和转换后的图片质量还OK,可使用pdf2image + Poppler 方案。Poppler 是一个处理pdf文档很有用的库,支持windows/linux/mac 。pdf2image是一个wrapper,提供调用Poppler的python接口。
首先要下载Poppler
https://blog.alivate.com.au/poppler-windows/
windows用户下载带x86字样的。
下载解压后,要把poppler下的bin目录绝对路劲加入到系统环境变量里,
比如我的是 D:Program Filespoppler-0.68.0bin ,要加入到系统环境变量Path变量里。不然pdf2image不知道去哪儿调用poppler。
然后安装pdf2image
pip install pdf2image
最后调用运行
from pdf2image import convert_from_pathpages = convert_from_path('D:/test/18.pdf')for i, page in enumerate(pages): page.save('D:/test/18_{}.jpg'.format(str(i)), 'JPEG')不过这种方法要处理十几M以上的pdf时,我亲测慢如蜗牛,内存还可能不够。处理大文件可以使用ghostscript,也是一个c程序,速度还过得去,我用它一次批处理数千个十几M pdf文档也花了好几个小时。这里就不再赘述如何使用ghostscript了。
读取pdf文档元信息
比如获取文档作者,主题,创作时间,文档页数等等。
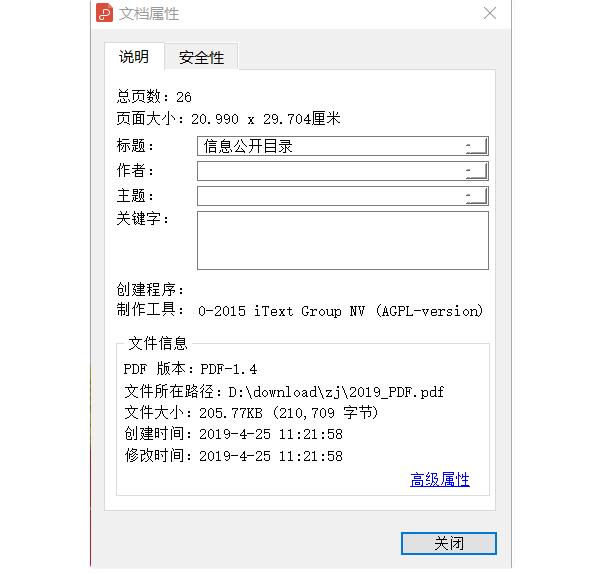
这里使用经典的PyPDF2库来操作,下面的操作都PyPDF2完成,当然你需要先安装,
pip install PyPDF2
from PyPDF2 import PdfFileReaderdef extract_information(pdf_path): with open(pdf_path, 'rb') as f: pdf = PdfFileReader(f) information = pdf.getDocumentInfo() number_of_pages = pdf.getNumPages() txt = f""" Information about {pdf_path}: Author: {information.author} Creator: {information.creator} Producer: {information.producer} Subject: {information.subject} Title: {information.title} Number of pages: {number_of_pages} """ print(txt) returnextract_information('D:/download/zj/2018.pdf')翻转pdf
对pdf文档向左向右翻转90度,并保存为一个新的文档。
from PyPDF2 import PdfFileReader, PdfFileWriterdef rotate_pages(pdf_path): # 新建一个空白pdf pdf_writer = PdfFileWriter() # 读取要翻转的pdf pdf_reader = PdfFileReader(path) # 把pdf第一页向右翻转90度并写入新建的空白pdf里 page_1 = pdf_reader.getPage(0).rotateClockwise(90) pdf_writer.addPage(page_1) # 把pdf第二页向左翻转90度并写入新建的空白pdf里 page_2 = pdf_reader.getPage(1).rotateCounterClockwise(90) pdf_writer.addPage(page_2) # 把pdf第三页不翻转正常写入 pdf_writer.addPage(pdf_reader.getPage(2)) # 把新建的pdf文档保存到本地 with open('D:/download/rotate_pages.pdf', 'wb') as fh: pdf_writer.write(fh) rotate_pages('D:/download/zj/18.pdf')从上面读取pdf文档元信息和翻转pdf可以看出,操作PyPDF2来读取和写入pdf的方法分别是PdfFileReader和PdfFileWriter
合并pdf文档
把多个pdf文档合并成一个,操作方法也很简单,仍然是先使用PdfFileReader方法读取pdf每一个页面,然后用PdfFileWriter写入一个到新的pdf文档中。
from PyPDF2 import PdfFileReader, PdfFileWriterdef merge_pdfs(paths, output): pdf_writer = PdfFileWriter() for path in paths: pdf_reader = PdfFileReader(path) for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) with open(output, 'wb') as out: pdf_writer.write(out) paths = ['d:/test/1.pdf', 'd:/test/2.pdf']merge_pdfs(paths, output='d:/test/merged.pdf')拆分pdf分档
把一个pdf文档拆分成多个,操作思路都差不多,先用PdfFileReader读取pdf文档,再用PdfFileWriter把每一页写入新的。
下面的例子是把一个pdf文档每一页都拆分成一个pdf文档,按文件页数来命令新的文档。
from PyPDF2 import PdfFileReader, PdfFileWriterdef split(path): pdf = PdfFileReader(path) for page in range(pdf.getNumPages()): pdf_writer = PdfFileWriter() pdf_writer.addPage(pdf.getPage(page)) output = f'{page}.pdf' with open(output, 'wb') as output_pdf: pdf_writer.write(output_pdf)split('d:/test/test.pdf')给pdf文档添加水映
可以调用mergePage()方法给pdf文档加水印,PyPDF2的操作方法是把一个水印pdf文档(这个pdf文档里只有水印,水印可以是文字或图片),重叠到待加水印的pdf文档中,其实就是把两个pdf页面重叠在一起。
如下程序是给每一个页面都加上水印。
from PyPDF2 import PdfFileWriter, PdfFileReaderdef create_watermark(input_pdf, output, watermark): #读取只有水印的那个文档 watermark_obj = PdfFileReader(watermark) watermark_page = watermark_obj.getPage(0) # 读取待加水印的文档 pdf_reader = PdfFileReader(input_pdf) pdf_writer = PdfFileWriter() # 给每一个页面都加上水印 for page in range(pdf_reader.getNumPages()): page = pdf_reader.getPage(page) page.mergePage(watermark_page) pdf_writer.addPage(page) # 保存为新的文档 with open(output, 'wb') as out: pdf_writer.write(out)create_watermark(input_pdf='D:/code/pdf/sphinx.pdf', output='D:/code/pdf/watermarked_sphinx.pdf', watermark='D:/download/zj/watermark.pdf')给pdf文档加密
给你一个pdf文档加密也很简单,调用encrypt()方法即可。
from PyPDF2 import PdfFileWriter, PdfFileReaderdef add_encryption(input_pdf, output_pdf, password): pdf_writer = PdfFileWriter() pdf_reader = PdfFileReader(input_pdf) for page in range(pdf_reader.getNumPages()): pdf_writer.addPage(pdf_reader.getPage(page)) # 加密 pdf_writer.encrypt(user_pwd=password, owner_pwd=None, use_128bit=True) with open(output_pdf, 'wb') as fh: pdf_writer.write(fh)add_encryption(input_pdf='no_password.pdf', output_pdf='password.pdf', password='yuanrenxue')加密之后,如何解密打开呢?
from PyPDF2 import PdfFileReaderpdfFile = open('password.pdf','rb')pdfReader = PdfFileReader(pdfFile) #为True表示是加密文档 yuanrenxue 是密码if pdfReader.isEncrypted: pdfReader.decrypt('yuanrenxue')上面可以看出,PyPDF2库是不能对pdf文本内容进行写操作,只能对pdf文档进行读取,页面拷贝,加解密,新建pdf文档操作。















 544
544

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









