





前言
近期小编在进行评测语料的制作时,涉及到一些复杂字符串的过滤和提取等内容,例如找出某一句话中在某个特定语句结构下出现的文字,虽然使用循环,if-else等语句可以搞定,但是比较麻烦,使用正则表达式处理就比较方便。

No.1
正则表达式定义
正则表达式,又称正规表达式(英文:Regular Expression,RE),它使用单个字符串来描述,匹配一系列符合某个句法规则的字符串,在很多的文本编辑器里,正则表达式通常被用来检索和替换那些匹配某个模式的文本。
No.2
正则表达式使用
举个栗子,假设使用爬虫获得一个HTML源码,其中一段为:
str1=r"<html><body><h1>hello.world<h1>body>html><h1>hello:world<h1><h1>helloAworld<h1>"这时候如果想提取所有的hello(x)world,通常需要对字符串进行split操作等,但是当第二个
变为
, 问题就会变得复杂起来。而用如下正则表达式则可以直接将hello (x)word提取出来:import rep1 = r"hello.world"pattern =re.compile(p1)print(re.findall(pattern, str1))其中,p1为正则表达式字符串,hello与world之间的“.”为一个可以匹配任何字符的元字符(后面有介绍),pattern为经过编译后得到的正则表达式对象,这样做的目的是便于后面的匹配中可以复用,上述表达式得到结果为:

No.3
正则表达式匹配方法
除了上面介绍的findall方法之外,正则表达式常用的匹配方法还有 match和search,三者之间的区别为:
match:从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回None;
search: 它在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果,如果搜索完了还没找到,则返回None;
findall: 该方法会搜索整个字符串,然后返回一个list,匹配正则表达式的所有内容。
No.4
正则表达式范围匹配
在一段字符串内,我们可以在一段范围内选择要或者不要某些字符,例如有如下字符串:
str2 = r"lap &ap nap rap xap xap pap"对于str2,我们想要除了&ap之外的所有正常的字符串,通过如下表达式即可完成:
p2 = r"[lnrxp]ap" #字母开头ap都要pattern = re.compile(p)print (re.findall(pattern,str2))上述代码得到的结果为:
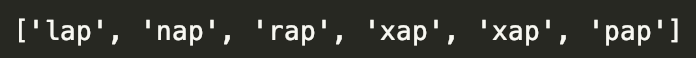
上述正则表达式中,对于str2中存在类别较少的(x)ap,当有26个字母并且区分大小写时使用该语句显然不现实,Python内置了很多简洁的正则表达式,避免我们在提取的过程中需要把想要的字母一个个写出来,常见的有:
[0-9]0123456789任意之一
[a-z]小写字母任意之一
[A-Z]大写字母任意之一
\d 等同于[0-9]
\D 等同于[^0-9]即匹配非数字
\w 等同于[a-z0-9A-Z]匹配大小写字母,数字和下划线
\W 等同于上一条取非
因此对于上述正则表达式p2,使用r"\wap",r“[a-z]ap”得到的结果是一样的。此外我们在前面已经介绍过“.”元字符,在p2中,“[]”也是一个元字符,它表示的是当前表达式匹配[]内任意的字符。Python中还内置了很多元字符,方便了我们在写正则表达式时能够更简洁的表述。读者可以访问一下网址来查看定义:https://www.runoob.com/regexp/regexp-metachar.html。
No.5
正则表达之贪心与懒惰
假设有如下字符串:
str3 = r"sogoutest@sogou-inc.com.cn"我们想要把str3中从@开始一直到“.”之前的内容匹配出来,则可以这样去实现
p3 = r"@.+\."pattern= re.compile(p3)print (re.findall(pattern,str3))
其中,“+”也是也是一个元字符,表示匹配前面的最近的字符一次或多次,可以看到,此时表达式尽可能多地进行匹配,匹配到了com后面的“.”,即贪心模式。若只想匹配到第一个点结束,即可使用如下语句改为懒惰模式。
p3 = r"@.+?\."pattern= re.compile(p3)print (re.findall(pattern,str3))
此时我们可以看到,结果在匹配到inc后面的“.”就结束了。
参考链接:
1.https://www.py.cn/spider/guide/14488.html
2.https://www.py.cn/faq/python/12021.html
3.https://www.runoob.com/regexp/regexp-metachar.html
结语
2020/03/17
正则表达式在处理字符串时作用很大,结合Python提供的元字符列表可以实现功能更多更复杂的语句,针对同一个问题的解决方式可能会有很多种,需要在平时使用中加以运用熟练掌握。















 486
486











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









