






内容目录
- 表的加法
- 多表关联
- 多表关联应用案例
- case when 表达式
- 练习题
一.表的加法 (union,union all)
EXCEL的应用场景中经常会有表的追加,追加是指行追加,列名称都一样的 不同记录的表
工作场景中经常会有 1月份 2月份 3月份......每个月份 或者 不同合作部门提供给你的数据表(前提是表的列数是一样的)的数据记录要追加到一张表里便于做数据透视表
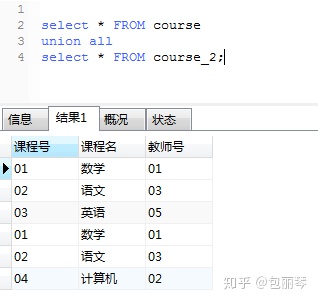
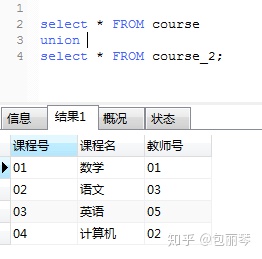
SQL中追加相同表结构的表的记录的时候要用 union (union all)
union :去掉重复记录
union all :不去重


二.多表关联(内关联 ,左关联,右关联)
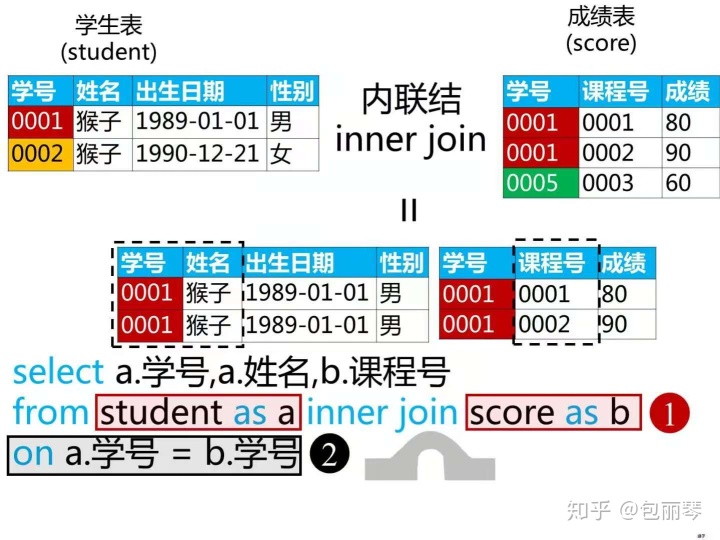
日常工作中我们常常需要从不同的表中提取不同的字段在进行汇总分析,就是我们常说的跨表处理数据,EXCELE中我们常常会用VLOOKUP ,LOOKUP 等函数来处理跨表问题,那么SQL重我们要怎么解决多表操作的问题呢? 答案就是做表表关联,找到表与表之间的联系,在用关联字段进行联接,例如下面的图:

多表联接有内联接inner join 、外联接(左联接left join 右联接 right join)等方式
内联接:内联接是取多表之间的交集部分
Select
From 表A
(INNER)JOIN 表B on 表A.字段=表B.字段
(INNER ) JOIN 表C on 表C.字段=表B.字段
…….
Where .条件
Group by 汇总
内关联:多表操作之多表关连(列)左关联: 左表的所有信息都包括进去
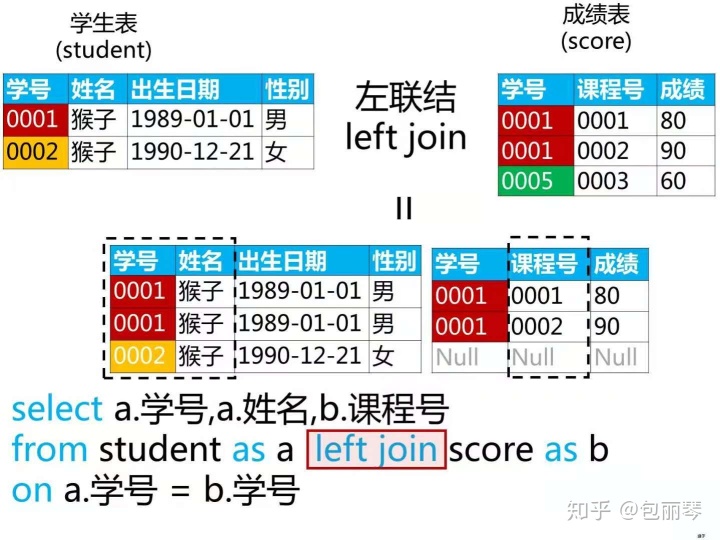
select *
from 表名1
left (inner) join 表名2 on关联字段
where …….右关联: 右表的所有信息都包括进去

select *
from 表名1
right (inner) join 表名2 on 关联字段
where …….三.多表关联应用案例
下面我们构建几张表,应用下多表关联
学生表:student
create table student(sid varchar(10),sname varchar(10),sage datetime,ssex varchar(10));
insert into Student values('01' , 'zhaolei' , '1990-01-01' , '男');
insert into Student values('02' , 'qianfeng' , '1990-12-21' , '男');
insert into Student values('03' , 'sunyun' , '1990-05-20' , '男');
insert into Student values('04' , 'liyun' , '1990-08-06' , '男');
insert into Student values('05' , 'zhoumei' , '1991-12-01' , '女');
insert into Student values('06' , 'wulan' , '1992-03-01' , '女');
insert into Student values('07' , 'zhengzhu' , '1989-07-01' , '女');
insert into Student values('08' , 'wangju' , '1990-01-20' , '女');课程表:Course
create table Course(cid varchar(10),cname varchar(100),tid varchar(10));
insert into Course values('01' , 'yuwen' , '02');
insert into Course values('02' , 'shuxue' , '01');
insert into Course values('03' , 'yingyu' , '03');教师表:Teacher
create table Teacher(tid varchar(10),tname varchar(10));
insert into Teacher values('01' , 'zhangsan');
insert into Teacher values('02' , 'lisi');
insert into Teacher values('03' , 'wangwu');成绩表:SC
create table SC(sid varchar(10),cid varchar(10),score decimal(18,1));
insert into SC values('01' , '01' , 80);
insert into SC values('01' , '02' , 90);
insert into SC values('01' , '03' , 99);
insert into SC values('02' , '01' , 70);
insert into SC values('02' , '02' , 60);
insert into SC values('02' , '03' , 80);
insert into SC values('03' , '01' , 80);
insert into SC values('03' , '02' , 80);
insert into SC values('03' , '03' , 80);
insert into SC values('04' , '01' , 50);
insert into SC values('04' , '02' , 30);
insert into SC values('04' , '03' , 20);
insert into SC values('05' , '01' , 76);
insert into SC values('05' , '02' , 87);
insert into SC values('06' , '01' , 31);
insert into SC values('06' , '03' , 34);
insert into SC values('07' , '02' , 89);
insert into SC values('07' , '03' , 98);- 案列1.查询所有同学的学号、姓名、选课数、总成绩 (左/右关联)
select A.sid,sname name,B.选课数,B.总成绩
from student as A
left join
(select sid,count(distinct cid )as 选课数 ,sum(score) as 总成绩
from sc
group by sid ) as B
on A.sid = B.sid;解题思路:首先要汇总出每个学生的选课数,总成绩,在用学生号跟学生表做关联,该案例要保留所有同学的学生信息,不管有没有成绩,都要保留,所以首先想到的是用学生表做主表,保留出所有同学的信息,在关联到成绩表取出其它信息
左关联和右关联的区别其实就是顺序的问题,把表的顺序换一下 左关联就变成右关联了。
代码如下:
select B.sid,sname name,A.选课数,A.总成绩
from (select sid,count(distinct cid )as 选课数 ,sum(score) as 总成绩
from sc group by sid ) as A
RIGHT join student as B
on A.sid = B.sid;- 案例2:查询所有课程成绩小于60分的同学的学号、姓名;
select a.sid ,sname , score
from student a
join sc b
on a.sid=b.sid
where b.score >60;解题思路:这个案例就只需保留要两个表中有交集的部分就可以了,所以用内关联 inner join,inner join 可以省略 关键字inner;
案例3:查询各科成绩最高分、最低分和平均分:以如下形式显示:课程ID,课程name,最高分,最低分,平均分,及格率
select sc.cid 课程ID ,course .cname 课程名,max(score) 最高分,
min(score) 最低分,avg(score) 平均分,
count( if (score >60,sid ,null))/count(sid) as 及格率
from sc
left join course
on sc.cid =course .cid
group by sc.cid ;解题思路:这个案例里面 课程ID,最高分,最低分,平均分,及格率等信息均可以从成绩表SC里获得,课程name ,是成绩表SC里面没有的 得从课程表course里获得,另外没有指出要保留所有信息,所以首先想到的就是做内关联;
四.case when 表达式
excel 中我们写的最多的函数恐怕是if了吧;
if(成绩>60,'及格',if(成绩>80,'良'......)这样的函数我们肯定写过无数次,条件多的时候,感觉完全把自己绕晕了有没有,迫切想得到更优解的方法来解决不够用的脑回路,那么SQL中的 case when 表达式肯定会让你欣喜万分了。
Case when 条件then 结果
when 条件then 结果
when 条件then 结果
end;案例:统计各科合格人数,不合格人数
select cid
,sum( case when score >=60 then 1 else 0 end ) as 及格
,sum( case when score <60 then 1 else 0 end ) as 不及格
from sc
group by cid;五.练习题:
网址:SELECT within SELECT Tutorial/zh;
1.列出每個國家的名字name,當中人口population是高於俄羅斯'Russia'的人口。
SELECT name FROM world
WHERE population >
(SELECT population FROM world
WHERE name='Russia')2.列出歐州每國家的人均GDP,當中人均GDP要高於英國'United Kingdom'的數值。
select name
from world
where gdp/population >
(select gdp/population from world where name = 'United Kingdom')
and continent = 'Europe';3.在阿根廷Argentina及 澳大利亞Australia所在的洲份中,列出當中的國家名字name及洲分continent。按國字名字順序排序
select name, continent from world
where continent in
(select continent
from world
where name='Argentina' or name='Australia')
order by name;4.哪一個國家的人口比加拿大Canada的多,但比波蘭Poland的少?列出國家名字name和人口population 。
select name ,population
from world
where population > (select population from world where name ='Canada')
and population < (select population from world where name ='Poland');5.Germany德國(人口8000萬),在Europe歐洲國家的人口最多。Austria奧地利(人口850萬)擁有德國總人口的11%。
顯示歐洲的國家名稱name和每個國家的人口population。以德國的人口的百分比作人口顯示。
小數位數
select name,
concat(round(population/(select population from world where name = 'Germany')*100,0),'%') as rate
from world
where continent = 'Europe';6.哪些國家的GDP比Europe歐洲的全部國家都要高呢? [只需列出name。] (有些國家的記錄中,GDP是NULL,沒有填入資料的。)
SELECT name
FROM world
WHERE gdp > ALL(SELECT gdp
FROM world
WHERE GDP>0
and continent = 'Europe');7.在每一個州中找出最大面積的國家,列出洲份continent, 國家名字name及面積area。 (有些國家的記錄中,AREA是NULL,沒有填入資料的。)
select continent,name,area
from world x
where area >= all (select area from world y
where x.continent= y.continent
and area>0);8.列出洲份名稱,和每個洲份中國家名字按子母順序是排首位的國家名。(即每洲只有列一國)
select continent,name
from world as x
where name <= all (select name from world as y where x.continent= y.continent);9.找出洲份,當中全部國家都有少於或等於 25000000 人口. 在這些洲份中,列出國家名字name,continent洲份和population人口。
select name,continent,population
from world as a
where 25000000>= all (select population from world as b where a.continent=b.continent);10.有些國家的人口是同洲份的所有其他國的3倍或以上。列出 國家名字name 和 洲份 continent
select name,continent
from world as a
where population >= all(select 3*population from world as b where a.continent=b.continent
and a.name<>b.name);













 2637
2637











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









