





由于安装配置Hadoop牵涉的内容较多,我将Hadoop的安装配置拆成了3篇文章来讲述。
这是第二篇。

第一篇的内容参考我的上一篇文章:一、怎么进行分布式计算和分布式存储?安装大数据计算核心Hadoop
本文的主要内容是:
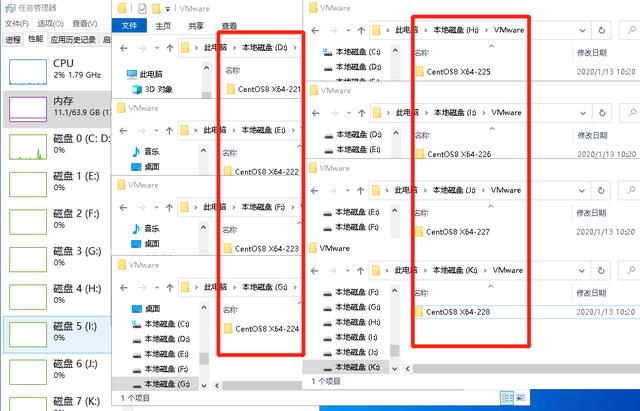
1、配置完Hadoop以后,把虚拟机复制7份然后分别配置,或者在实体服务器上将Hadoop软件包复制给另外7台服务器;
2、进行首次启动Hadoop,执行一些初始化的工作,并且格式化HDFS等等。
Hadoop配置完成以后的操作
注意:以下内容需要一步一步的来操作,如果你还不熟悉,一定不要跳过任何一步。
将配置好的虚拟机复制出来7份,并分别都启动,接着进行如下操作:
修改网卡IP
先用root权限操作:先用root权限操作:先用root权限操作:
重要的事情说3遍。
用root用户执行下述命令:
在222-228服务器上运行以下指令,修改成对应的IP
vi /etc/sysconfig/network-scripts/ifcfg-ens160
IP配置完毕以后,输入一下指令,重启网卡:
先载入新的网卡配置文件:
nmcli c reload
执行网卡重启(下面的三条命令都可以):
nmcli c up ens160
nmcli d reapply ens160
nmcli d connect ens160
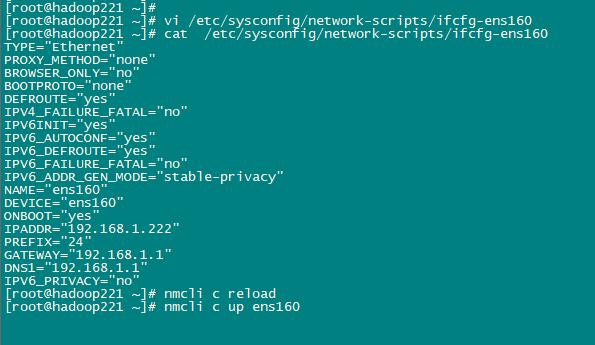
总结:重启CentOS Linux 8的网卡,先载入新的配置文件,然后再执行重启网卡命令即可。
修改各自的hostname
先用root权限操作:先用root权限操作:先用root权限操作:
重要的事情说3遍。
用root用户执行下述命令:
在222-228服务器上分别运行以下指令,修改成对应的hostname
hostnamectl set-hostname hadoop222
hostnamectl set-hostname hadoop223
hostnamectl set-hostname hadoop224
hostnamectl set-hostname hadoop225
hostnamectl set-hostname hadoop226
hostnamectl set-hostname hadoop227
hostnamectl set-hostname hadoop228

配置免密码登录
生成各种密码文件(如果是虚拟机,可在安装全部的软件后再操作)
下面以hadoop用户操作:下面以hadoop用户操作:下面以hadoop用户操作
重要的事情说3遍。
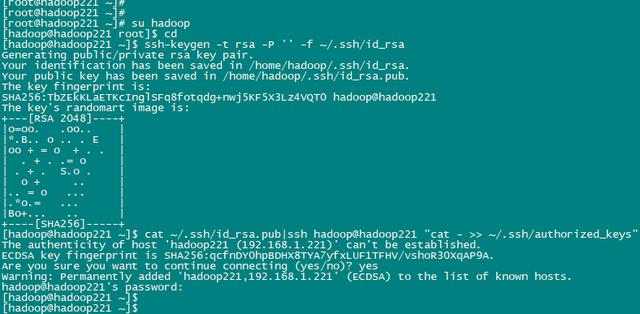
1、 在所有的服务器上执行以下命令(包括主服务器)
切换到hadoop用户,并进入hadoop的主目录:
su hadoop
cd
生成验证密钥:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
验证密钥发送给主服务器:
cat ~/.ssh/id_rsa.pub|ssh hadoop@hadoop221 "cat - >> ~/.ssh/authorized_keys"
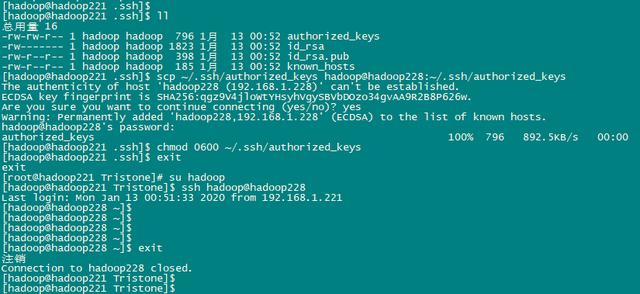
2、如果需要互相免密码登录,则主服务器执行下面命令,把密钥分发给从服务器
scp ~/.ssh/authorized_keys hadoop@hadoop222:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hadoop223:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hadoop224:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hadoop225:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hadoop226:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hadoop227:~/.ssh/authorized_keys
scp ~/.ssh/authorized_keys hadoop@hadoop228:~/.ssh/authorized_keys
在所有的服务器上执行以下命令(包括主服务器)
chmod 0600 ~/.ssh/authorized_keys
退出hadoop用户,再重新 su hadoop进入一次即可免密登录了
修改Zookeeper的myid
下面以hadoop用户操作:下面以hadoop用户操作:下面以hadoop用户操作
重要的事情强调3遍。
用hadoop用户执行下述命令,在226-228上分别执行下列命令:
echo 226 > /home/hadoop/data/zkdata/myid #hadoop226上执行这个命令
echo 227 > /home/hadoop/data/zkdata/myid #hadoop227上执行这个命令
echo 228 > /home/hadoop/data/zkdata/myid #hadoop228上执行这个命令
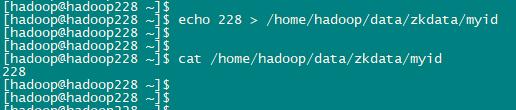
如果是在真实的服务器上操作,则需要将hadoop安装包分发到其他集群节点
重点强调: 每台服务器中的hadoop安装包的目录必须一致, 安装包的配置信息还必须保持一致
下面以hadoop用户操作:下面以hadoop用户操作:下面以hadoop用户操作
重要的事情强调3遍。
命令如下:
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop222:$PWD
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop223:$PWD
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop224:$PWD
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop225:$PWD
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop226:$PWD
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop227:$PWD
scp -r /home/hadoop/server/hadoop-3.2.1/ hadoop228:$PWD
第一次启动Hadoop服务
重点强调:一定要按照以下步骤逐步进行操作,下面以hadoop用户操作
重点强调:一定要按照以下步骤逐步进行操作,下面以hadoop用户操作
重点强调:一定要按照以下步骤逐步进行操作,下面以hadoop用户操作
su hadoop
1、启动Zookeeper
启动3台服务器上的zookeeper服务,一台一台启动(226-228)
zkServer.sh start
查看是否启动成功:
jps
查看各台服务器的状态:
zkServer.sh status
显示内容类似如下:
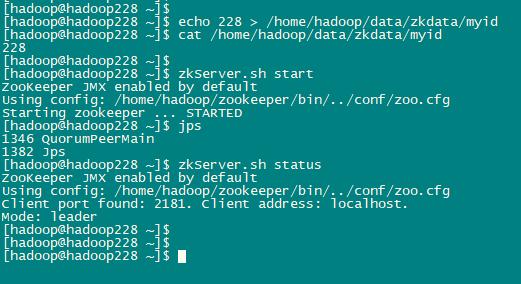
三台机器,一台一台启动并显示集群成功以后,继续执行以下内容。
2、启动journalnode
按照之前的规划,我的是在hadoop223、hadoop224、hadoop225上进行启动,启动命令如下:
hdfs --daemon start journalnode
jps
显示内容如下:
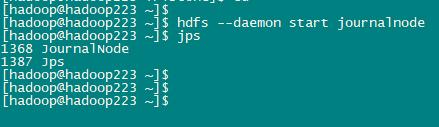
3、格式化namenode
格式化namenode,在hadoop221上执行,只在第一次安装的时候运行此命令,会清空数据
hdfs namenode -format
显示内容部分如下:
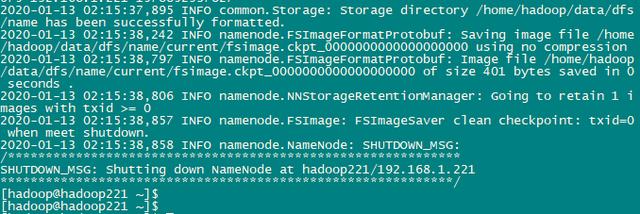
重要的是这一句:
Storage directory /home/hadoop/data/dfs/name has been successfully formatted.
4、复制namenode数据给hadoop222
要把在hadoop221节点上生成的元数据 给复制到 另一个namenode(hadoop222)节点上,只在第一次安装的时候运行此命令
cd /home/hadoop/data
ll
显示内容如下:
dfs journaldata zkdata
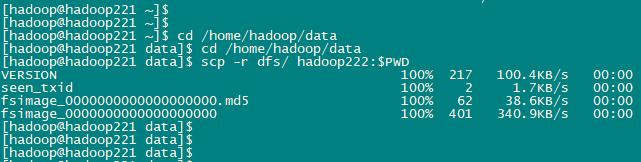
复制namenode数据给hadoop222
scp -r dfs/ hadoop222:$PWD
显示内容如下:
5、格式化zkfc
重点强调:只能在nameonde节点进行(hadoop221/ hadoop222)
重点强调:只能在nameonde节点进行(hadoop221/ hadoop222)
重点强调:只能在nameonde节点进行(hadoop221/ hadoop222)
hdfs zkfc -formatZK
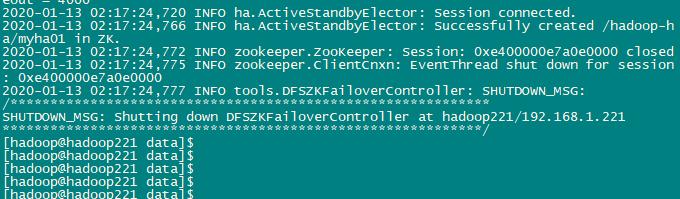
重要的是这一句:Successfully created /hadoop-ha/myha01 in ZK.
第一次启动Hadoop的时候运行的命令,结束!!!!
日常的启动,请看下一篇内容。
以后不要再重复执行本文内容,否则。。。。。后果自负
















 874
874











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









