






今天是学习java的第20天,今天接着学习了IO的相关知识。
基本的学习内容是对象流;序列话和反序列化;文件夹的复制;装饰器模式等。
我们前边学到的数据流只能实现对基本数据类型和字符串类型的读写,并不能读取对象(字符串除外),如果要对某个对象进行读写操作,我们需要学习一对新的处理流:ObjectInputStream/ObjectOutputStream。
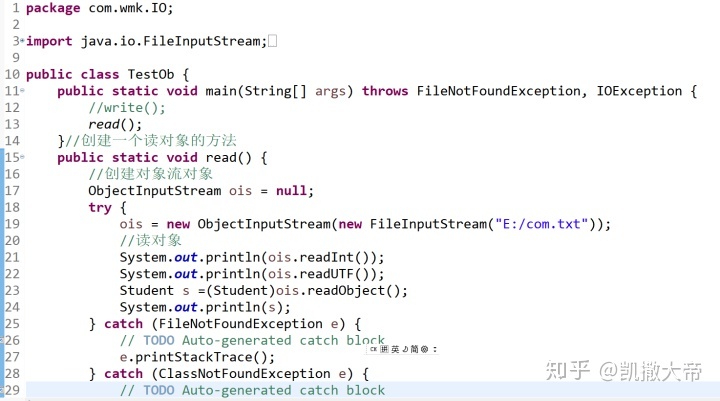

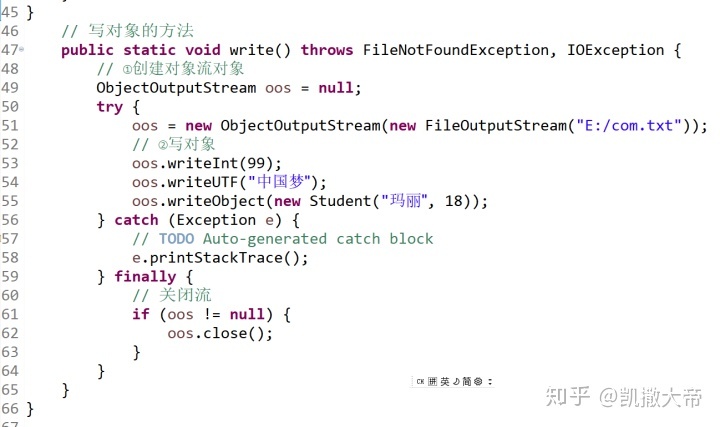
ObjectInputStream/ObjectOutputStream是以“对象”为数据源,但是必须将传输的对象进行序列化与反序列化操作。
之所以需要序列化,是因为序列化后的对象不仅可以存储到磁盘上,还可以在网络上传输,使得不同的计算机/不同的系统可以共享对象(序列化之后字节序列会与平台无关)。 当两个进程远程通信时,彼此可以发送各种类型的数据。 无论是何种类型的数据,都会以二进制序列的形式在网络上传送。比如,我们可以通过http协议发送字符串信息;我们也可以在网络上直接发送Java对象。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象才能正常读取。
对象序列化的作用有如下两种:
1. 持久化: 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中,比如:休眠的实现。以后服务器session管理,hibernate将对象持久化实现。
2. 网络通信:在网络上传送对象的字节序列。比如:服务器之间的数据通信、对象传递。
ObjectOutputStream代表对象输出流,它的writeObject(Object obj)方法可对参数指定的obj对象进行序列化,把得到的字节序列写到一个目标输出流中。
ObjectInputStream代表对象输入流,它的readObject()方法从一个源输入流中读取字节序列,再把它们反序列化为一个对象,并将其返回。
对象的序列化的条件为:只有实现了Serializable接口的类的对象才能被序列化。 Serializable接口是一个空接口,只起到标记作用。如果对象的属性是对象,属性对应类也必须实现Serializable。
对象序列化的注意事项为:
同一个对象多次序列化的处理:
①、所有保存到磁盘中的对象都有一个序列化编号
②、序列化一个对象中,首先检查该对象是否已经序列化过
③、如果没有,进行序列化
④、如果已经序列化,将不再重新序列化,而是输出编号即可
如果不希望某些属性(敏感)序列化,或不希望出现递归序列:
①、为属性添加transient关键字(完成排除在序列化之外)
②、自定义序列化(不仅可以决定哪些属性不参与序列化,还可以定义属性具体如何序列化)
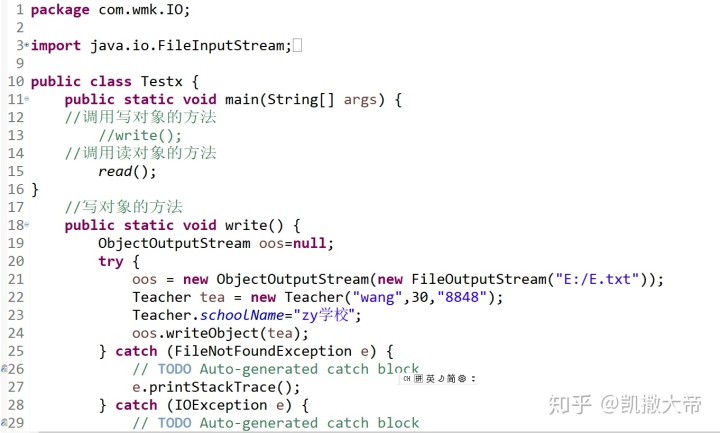


文件夹的复制会使用到:
字节流,字符流
BufferedInputStream,BufferedOutputStream
FileInputStream,FileOutputStream
文件夹复制的过程可以简述为:
如果目录下文件类型不同,种类较多,应该选择字节流+缓冲流提高效率。
1、复制一个文件
2、指定目录下的所有文件
3、指定目录下单的所有文件及子目录下的所有文件
在网络上,两台计算机进行互相交流通信的时候,传递的就是字节(byte)。
装饰模式是一种用于代替继承的技术,无须通过继承增加子类就能扩展对象的新功能。使用对象的关联关系代替继承关系,更加灵活,同时避免类型体系的快速膨胀。
装饰模式是一种用于代替继承的技术,无须通过继承增加子类就能扩展对象的新功能。使用对象的关联关系代替继承关系,更加灵活,同时避免类型体系的快速膨胀。
装饰模式的优缺点
优点:
*扩展对象功能,比继承灵活,不会导致类个数急剧增加
*可以对一个对象进行多次装饰,创建出不同行为的组合,得到功能更加大的对象
*具体构建类和具体装饰类可以独立变化,用户可以根据需要自己增加新的具体构件子类和具体装饰子类
缺点
*产生很多小对象。大量小对象占据内存,一定程序上影响性能
*装饰模式易于出错,调试排查比较麻烦
IO
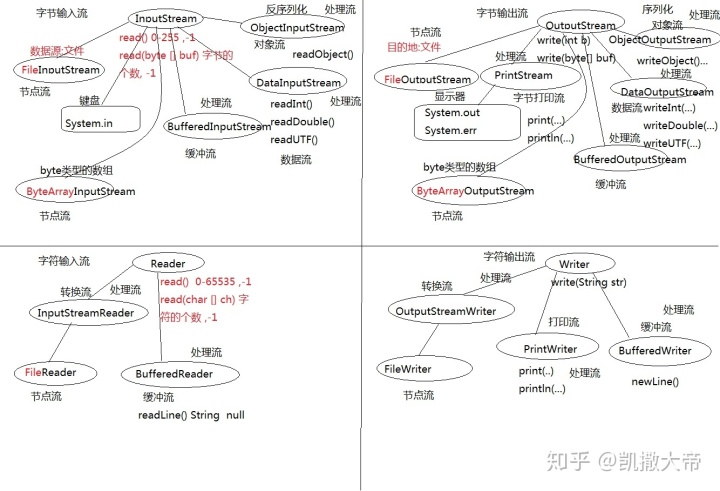
节点流:FileInputStream、FileOutputStream、ByteArrayInputStream、ByteArray
OutStream、FileReader、FileWriter。
处理流:不直接连接到数据源或目的地,是其他流进行封装。不能单独使用,配合节点流使用。例如缓冲流、数据流、对象流……
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
JDK中提供的文件操作相关的类,但是功能都非常基础,进行复杂操作时需要做大量编程工作。实际开发中,往往需要你自己动手编写相关的代码,尤其在遍历目录文件时,经常用到递归,非常繁琐。 Apache-commons工具包中提供了IOUtils/FileUtils,可以让我们非常方便的对文件和目录进行操作。
Apache FileUtils中常用的方法有:
cleanDirectory:清空目录,但不删除目录。
contentEquals:比较两个文件的内容是否相同。
copyDirectory:将一个目录内容拷贝到另一个目录。可以通过FileFilter过滤需要拷贝的 文件。
copyFile:将一个文件拷贝到一个新的地址。
copyFileToDirectory:将一个文件拷贝到某个目录下。
copyInputStreamToFile:将一个输入流中的内容拷贝到某个文件。
deleteDirectory:删除目录。
deleteQuietly:删除文件。
listFiles:列出指定目录下的所有文件。
openInputSteam:打开指定文件的输入流。
readFileToString:将文件内容作为字符串返回。
readLines:将文件内容按行返回到一个字符串数组中。
size:返回文件或目录的大小。
write:将字符串内容直接写到文件中。
writeByteArrayToFile:将字节数组内容写到文件中。
writeLines:将容器中的元素的toString方法返回的内容依次写入文件中。
writeStringToFile:将字符串内容写到文件中。
Apache IOUtils中常用的方法有:buffer方法:将传入的流进行包装,变成缓冲流。并可以通过参数指定缓冲大小。
closeQueitly方法:关闭流。
contentEquals方法:比较两个流中的内容是否一致。
copy方法:将输入流中的内容拷贝到输出流中,并可以指定字符编码。
copyLarge方法:将输入流中的内容拷贝到输出流中,适合大于2G内容的拷贝。
lineIterator方法:返回可以迭代每一行内容的迭代器。
read方法:将输入流中的部分内容读入到字节数组中。
readFully方法:将输入流中的所有内容读入到字节数组中。
readLine方法:读入输入流内容中的一行。
toBufferedInputStream、
toBufferedReader:将输入转为带缓存的输入流。
toByteArray,toCharArray:将输入流的内容转为字节数组、字符数组。
toString:将输入流或数组中的内容转化为字符串。
write方法:向流里面写入内容。
writeLine方法:向流里面写入一行内容。














 9664
9664











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









