






最近的每日一题,出现了一道图的遍历,力扣第127题单词接龙。本篇文章整体都是讲解这道题的。首先要说明的是这篇题解的代码是我在评论区偷的(但是理解是自己写的)!!我们读书人的事,怎么能叫偷呢?算法这东西你学到了不就是自己的吗?
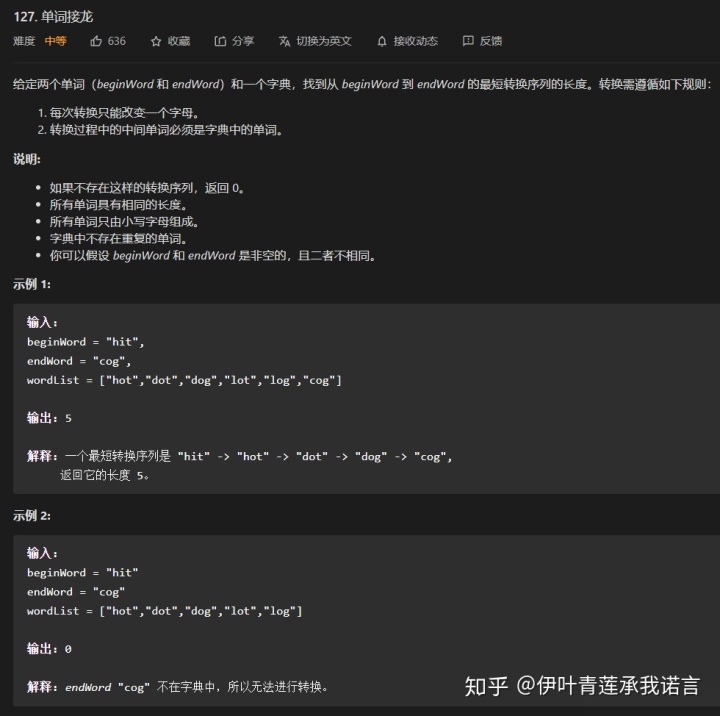
基础思路:仔细读过题之后,可以注意到题目中要求找到最短转换路径。此时可以确定使用BFS搜索,因为BFS可以计算出从根节点开始到达每个可到达节点的距离,我们只需要在这些距离中找到从begin出发到end的最短距离即可。
其中从begin到end的变化中每次改变只能变换一个字母,并且转换后的单词也在wordList中,因此我们可以根据这个两个条件从begin单词开始构建出一个图。(PS:图搜索算法可以用来发现图的结构,许多的图算法在一开始都会先通过搜索来获得图的结构,其他一些图算法则对基本的搜索进行优化。 ----算法导论是这么说的)
如何进行构建?首先BFS,肯定是使用队列的结构。我们可以从第一个单词开始,每次变换一个字母,如果该字母组成的新单词在wordList中,那么将该新单词入队,重复这一过程直到找到endWord。
这一过程在图中的表现就是旧单词(hit)与新单词(hot)之间建立起了一条边。代码中循环遍历对应图中的表现即是从新的单词无限延伸,直到找到end。
需要注意的是,这两条边是可逆的,也就是说该结构是无序图。通俗一点放在代码里讲,其实就是说我们要有一个集合存放已经遍历过的元素,以防止两个单词互相转换或是遍历到了已经遍历过的词,增加不必要的开销,因为我们找的是最短路径。
开始操作:
1、准备工作
# 将列表变成一个哈希表,以便在O(1)时间内进行in操作,
# 判断单词是否在hash表内 (List中这个判断是O(n))。
word_set = set(wordList)
# BFS遍历需要使用队列的结构。同时以第一个单词(beginWord)为起点进行图的生成。
queue = deque()
queue.append(beginWord)
# 上面有提到过要使用一个集合来记录某个节点是否访问过。
visited = set(beginWord)
# 因为题目中有说明"所有的单词长度都相同",那么根据我们的刚才整理的思路,
# 也就是加粗部分,可以看到每个单词遍历的次数就是他的元素个数,比如hit,
# 它有三个字母就需要把h,i,t三个字母分别换成26个字母,看是否可以组成
# 新的单词在wordList中。因此,此处我们需要记录单词的长度,也就是后面
# 我们要用到的每个单词的遍历次数。
word_len = len(beginWord)
# 准备工作的最后肯定需要一个字段来计算我们走过的节点数量。
# 此字段从1开始,即要从自己本身出发。
count = 1
# 然后是两点特殊处理
# 1、当没有字典或者结束单词根本不在字典时候,直接返回0
# 2、把开始单词从字典中删除,因为我们已经使用开始单词作为队列的第一个元素了。
if len(word_set) == 0 and endWord not in word_set:
return 0
if beginWord in word_set:
word_set.remove(beginWord)2、准备工作结束后,现在进入正式的编码操作。
# 下面这几步应该不用解释了吧?BFS模板,无脑写出来就行。
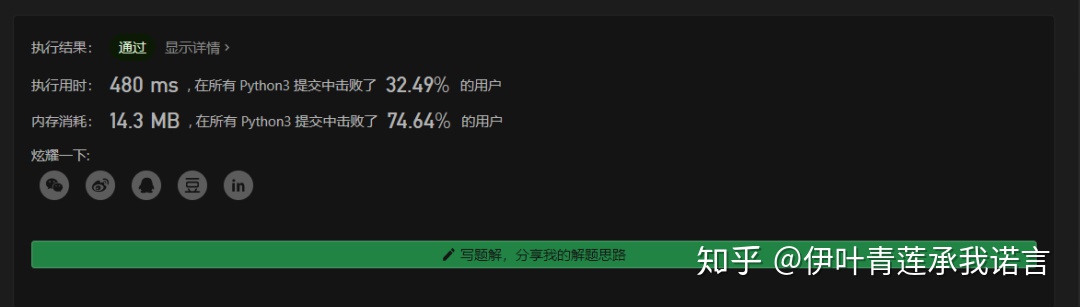
写在最后。可能有的朋友会问了,你这个怎么这么慢呢,才打败30%?其实这是个误会,本题解已经尽量进行速度上的优化了,但是隔壁的双向BFS实在太强了,我们打不赢~
不过!不过!不过!之所以还是要写这篇文章,是因为这是很经典的图的BFS遍历模板,甚至只要微调一下就可以使用在同类型的题目中~
源码在此















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









