





1. 概念理解
Kubernetes作为时下最火的容器编排引擎,我们非常有必要花时间去学习、研究并且掌握它。
1.1 什么是K8s
Kubernetes简称K8s,最先是 Google 团队发起的一个开源项目,它的目标是管理跨多个主机的容器,用于自动部署、扩展和管理容器化的应用程序,主要实现语言为 Go 语言,后被开源发展到目前大名鼎鼎的Kubernetes。并且Kubernetes非常迅速强势地结束了容器编排市场三足鼎立(Swarm、Mes OS、Kubernetes)的局面,成为目前容器编排的标准。
1.2 K8s架构
如下图所示是K8s的整体架构图(该图片摘自网络):
- K8s整体物理架构图
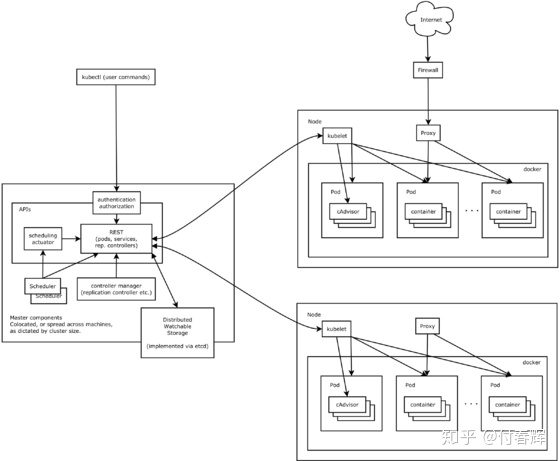
1.3 K8s核心组件
从上述K8s的架构图来看,一个K8s集群物理上是由一个master节点和若干个(一般至少为2个)工作节点组成,而对应不同的节点会因为角色功能的不同都会有各自的核心组件。
master节点
K8s的主控节点,负责管理集群和协调集群中的所有活动,其核心组件至少包括如下几种:
- apiserver: 对内/外提供 HTTP REST资源操作接口,也是唯一与etcd直接交互的组件;
- controller manager:负责维护集群的状态,比如故障检测、自动扩展、滚动更新等;
- scheduler:资源的调度策略,将不同的pod调度到不同的工作节点上执行;
- etcd:保存整个集群的状态信息,其实质是个数据库,同时也用于服务发现;
worker节点
K8s的工作节点,一般在K8s集群中会存在多个,完成最终pod中容器的程序的运行和业务的处理,其核心组件主要包括:
- kubelet:负责Pod整个生命周期的管理比如 Pod 的创建、启动、监控、重启、销毁等工作,同时与 Master 节点协作,实现集群管理的基本功能;
- kube-proxy:实现 Kubernetes Service 的通信和负载均衡;
1.4 核心概念
Node
K8s集群中的计算能力由Node提供,最初Node称为服务节点Minion,后来改名为Node。K8s集群中的Node也就等同于Mesos集群中的Slave节点,是所有Pod运行所在的工作主机,可以是物理机也可以是虚拟机。不论是物理机还是虚拟机,工作主机的统一特征是上面要运行kubelet管理节点上运行的容器。
pod
K8s资源调度的最小单位,它是由紧密联系、资源共享的一组容器在组成,可以理解成一个具体应用的实例。
Replication Controller
RC是K8s集群中最早的保证Pod高可用的API对象。通过监控运行中的Pod来保证集群中运行指定数目的Pod副本。指定的数目可以是多个也可以是1个;少于指定数目,RC就会启动运行新的Pod副本;多于指定数目,RC就会杀死多余的Pod副本。即使在指定数目为1的情况下,通过RC运行Pod也比直接运行Pod更明智,因为RC也可以发挥它高可用的能力,保证永远有1个Pod在运行。RC是K8s较早期的技术概念,只适用于长期伺服型的业务类型,比如控制小机器人提供高可用的Web服务。
ReplicaSets
RS是新一代RC,提供同样的高可用能力,区别主要在于RS后来居上,能支持更多种类的匹配模式。副本集对象一般不单独使用,而是作为Deployment的理想状态参数使用。
Deployment
部署表示用户对K8s集群的一次更新操作。部署是一个比RS应用模式更广的API对象,可以是创建一个新的服务,更新一个新的服务,也可以是滚动升级一个服务。滚动升级一个服务,实际是创建一个新的RS,然后逐渐将新RS中副本数增加到理想状态,将旧RS中的副本数减小到0的复合操作;这样一个复合操作用一个RS是不太好描述的,所以用一个更通用的Deployment来描述。以K8s的发展方向,未来对所有长期伺服型的的业务的管理,都会通过Deployment来管理。
service
提供访问策略,资源的访问入口。RC、RS和Deployment只是保证了支撑服务的微服务Pod的数量,但是没有解决如何访问这些服务的问题。一个Pod只是一个运行服务的实例,随时可能在一个节点上停止,在另一个节点以一个新的IP启动一个新的Pod,因此不能以确定的IP和端口号提供服务。要稳定地提供服务需要服务发现和负载均衡能力。服务发现完成的工作,是针对客户端访问的服务,找到对应的的后端服务实例。在K8s集群中,客户端需要访问的服务就是Service对象。每个Service会对应一个集群内部有效的虚拟IP,集群内部通过虚拟IP访问一个服务。在K8s集群中微服务的负载均衡是由Kube-proxy实现的。Kube-proxy是K8s集群内部的负载均衡器。它是一个分布式代理服务器,在K8s的每个节点上都有一个;这一设计体现了它的伸缩性优势,需要访问服务的节点越多,提供负载均衡能力的Kube-proxy就越多,高可用节点也随之增多。与之相比,我们平时在服务器端使用反向代理作负载均衡,还要进一步解决反向代理的高可用问题。
namespace
为K8s集群提供虚拟的隔离作用,一般地至少会存在两个命名空间:default、kube-system,实际使用中我们可以根据需求自建namespace。
2. K8s单节点集群环境
了解了K8s的基本概念之后,进一步理解K8s最快的方式就是亲自搭建一个K8s集群,此处只有一个节点(也就是同时扮演master和node的角色)。
2.1 安装docker
docker的安装此处不再赘述,可参照我的另一篇博文:https://www.jianshu.com/p/911dba395ef3
2.2 安装K8s基础组件
这里我是通过kubeadm来搭建K8s集群,所以需要首先同时安装kubeadm、kubectl、kubelet,安装的过程其实跟docker类似,可参考如下:
apt-get update && apt-get install -y apt-transport-https
curl https://mirrors.aliyun.com/kubernetes/apt/doc/apt-key.gpg | apt-key add -
echo 'deb https://mirrors.aliyun.com/kubernetes/apt/ kubernetes-xenial main' > /etc/apt/sources.list.d/k8s.list
apt-get update && apt-get install -y kubeadm kubectl kubelet2.3 创建K8s初始集群环境
2.3.1 下载K8s组件
搭建K8s集群所需的组件基本上都放在google网站上,需要科学上网,如果网络搞不定,可以先从docker hub下载这些组件然后修改tag,首先可通过下图命令来查看需要安装的K8s组件: * kubeadm config images list

接着,写一个下载所需docker image和修改tag的shell脚本: * cat pull_and_tag_k8s_images.sh
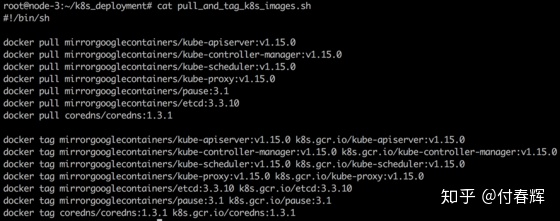
然后执行sh pull_and_tag_k8s_images.sh完成k8s组件镜像的下载和标签的修改。
2.3.2 初始化集群环境
首先执行swapoff -a来关闭,然后执行如下命令构建K8s初始化环境:
kubeadm init --pod-network-cidr=10.244.0.0/16根据输出的提示安装kubectl的配置文件:
mkdir -p $HOME/.kube
cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
chown $(id -u):$(id -g) $HOME/.kube/config安装pod网络是pod间能够通信:
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml出于安全考虑,默认master不允许参与pod调度因为,现在只有一个节点,为了能够让pod调度到master,需要执行:
kubectl taint node vienfu-virtualbox node-role.kubernetes.io/master-
# 如果新添加了node,需要重新恢复master only状态,执行如下命令
kubectl taint node vienfu-virtualbox node-role.kubernetes.io/master=""
#上述命令中的vienfu-virtualbox是master的主机名自此,单节点的K8s集群环境算是部署完成了,可通过kubectl get nodes -o wide命令查看: * kubectl get nodes -o wide



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









