






 本文介绍了jiebaR库的主要函数,包括worker()加载分词引擎,混合、最大概率、隐式马尔科夫和索引模型的分词方式。重点讲解了如何自定义词典,如使用搜狗词典转换工具,并介绍了停用词的处理方法。此外,还阐述了jiebaR的关键词提取功能,基于TF-IDF算法计算词的权重,用于提取文档关键词。
本文介绍了jiebaR库的主要函数,包括worker()加载分词引擎,混合、最大概率、隐式马尔科夫和索引模型的分词方式。重点讲解了如何自定义词典,如使用搜狗词典转换工具,并介绍了停用词的处理方法。此外,还阐述了jiebaR的关键词提取功能,基于TF-IDF算法计算词的权重,用于提取文档关键词。

一、jiebaR主要函数
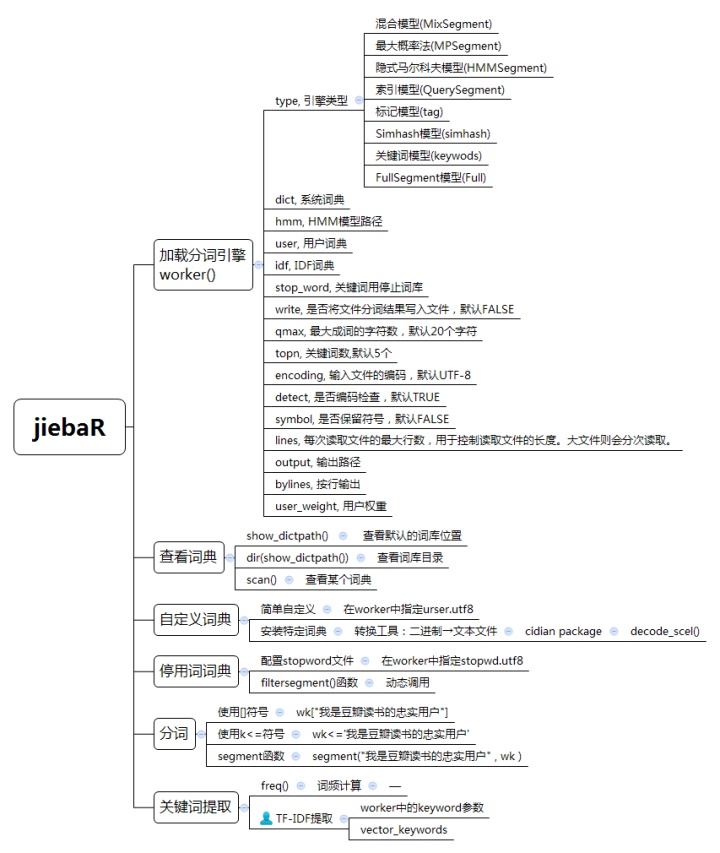
1.worker():加载jiebaR库的分词引擎
worker(type = "mix", dict = DICTPATH, hmm = HMMPATH, user = USERPATH,
idf = IDFPATH, stop_word = STOPPATH, write = T, qmax = 20, topn = 5,
encoding = "UTF-8", detect = T, symbol = F, lines = 1e+05,
output = NULL, bylines = F, user_weight = "max")
--------------------
## 参数解释
type, 引擎类型
dict, 系统词典
hmm, HMM模型路径
user, 用户词典
idf, IDF词典
stop_word, 关键词用停止词库
write, 是否将文件分词结果写入文件,默认FALSE
qmax, 最大成词的字符数,默认20个字符
topn, 关键词数,默认5个
encoding, 输入文件的编码,默认UTF-8
detect, 是否编码检查,默认TRUE
symbol, 是否保留符号,默认FALSE
lines, 每次读取文件的最大行数,用于控制读取文件的长度。大文件则会分次读取。
output, 输出路径
bylines, 按行输出
user_weight, 用户权重jiebaR库提供了八种分词引擎:
混合模型(MixSegment)
四个分词引擎里面分词效果较好的类,使用最大概率法和隐式马尔科夫模型
最大概率法(MPSegment)
负责根据Trie树构建有向无环图和进行动态规划算法,是分词算法的核心
隐式马尔科夫模型(HMMSegment)
根据基于人民日报等语料库构建的HMM模型来进行分词,主要算法思路是根据(B,E,M,S)四个状态来代表每个字的隐藏状态,HMM模型由dict/hmm_model.utf8提供,分词算法即viterbi算法。
索引模型(QuerySegment)
先使用混合模型进行切词,再对于切出来的较长的词,枚举句子中所有可能成词的情况,找出词库里存在
标记模型(tag)
Simhash模型(simhash)
关键词模型(keywods)
FullSegment模型(Full)
2.分词语法:[]、<=和segment函数
jiebaR提供了3种分词语句写法:[]符号语法、<=符号语法、segment()函数,三者形式不同,但分词效果一样。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









