





一、功能需求:
作为一个经常看电影的人,需要对豆瓣电影资源进行分类,豆瓣上有一个交互不友好的地方,每个网页中存在的信息太多,没有办法一次性浏览完,而且部分相应的功能必须点击进入电影界面才能看到,因此个人的感觉增加了很多下工序,所以,我想用Python写一个小功能,直接把相关的电影输出在控制台中,通过看所查找的记录,进而选择电影。
二、功能实现:
①通过关键字搜索相关资源 ②选择记录的条数(页码实现)
③通过控制台将资源记录下来
三、豆瓣网页代码分析
一)网站分析
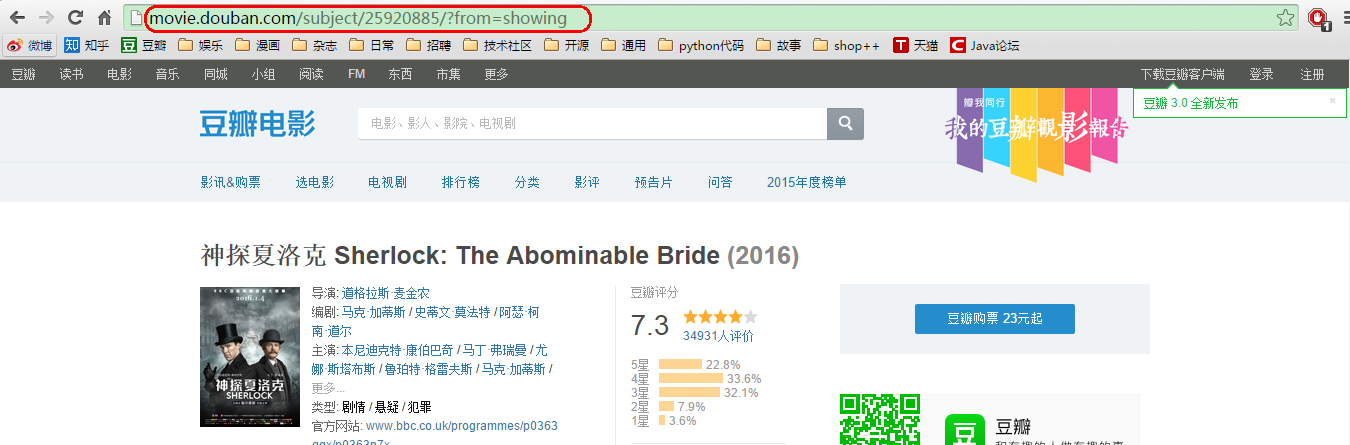
正则表达式匹配:http://movie.douban.com/subject/[0-9.]+)\/"\s+title="(.+)
二)分数地址分析
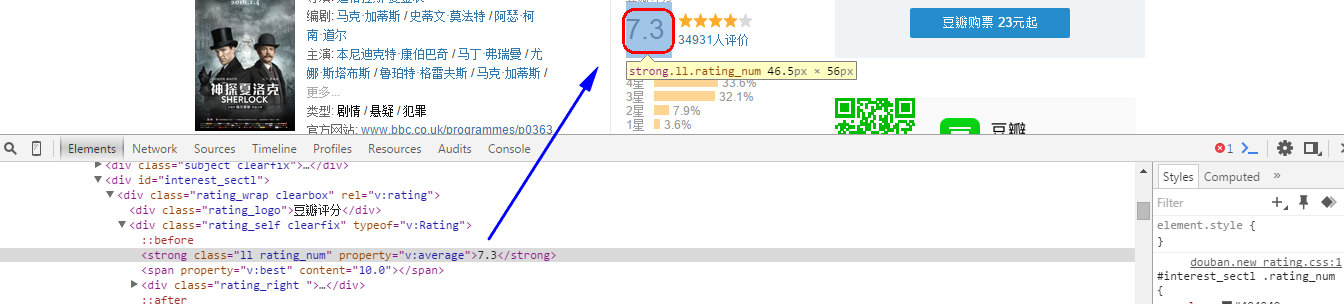
正则表达式匹配:([0-9.]+)<\/span>
三)评分地址分析

正则表达式匹配:\((\w+)人评价\)<\/span>
四、代码实现:
import re
import time
import urllib.request
def Douban_MovieSearch(movieTag):
#打开相应地址
tagUrl=urllib.request.urlopen(url)
#解析网页编码
tagUrl_read = tagUrl.read().decode('utf-8')
#返回所读取的网页
return tagUrl_read
def subject(tagUrl_read):
#关键:正则表达式匹配电影的名字(链接)、评分与评论
searchURL = re.findall(r'(http://movie.douban.com/subject/[0-9.]+)\/"\s+title="(.+)"',tagUrl_read)
gradeURL = re.findall(r'([0-9.]+)<\/span>',tagUrl_read)
evaluateURL = re.findall(r'\((\w+)人评价\)<\/span>',tagUrl_read)
#关键:数据封装(zip的使用)
movieLists = list(zip(searchURL,gradeURL,evaluateURL))
resourceList.extend(movieLists)
#返回数据列表
return resourceList
#用quote处理特殊(中文)字符
movieType = urllib.request.quote(input('请输入电影类型(如剧情、喜剧、悬疑、爱情、动作、魔幻):'))
page_end=int(input('请输入查询页数(每页10条记录):'))
num_end=page_end*10
num=0
page_num=1
resourceList=[]
#while-else的使用方法
while num
url=r'http://movie.douban.com/tag/%s?start=%d'%(movieType,num)
movie_url = Douban_MovieSearch(url)
subject_url=subject(movie_url)
num=page_num*10
page_num+=1
else:
#使用sorted函数对列表进行排列
movieLIST = sorted(resourceList, key=lambda movieList : movieList[1],reverse = True)
for movie in movieLIST:
print(movie)
time.sleep(10)
print('查询结束')
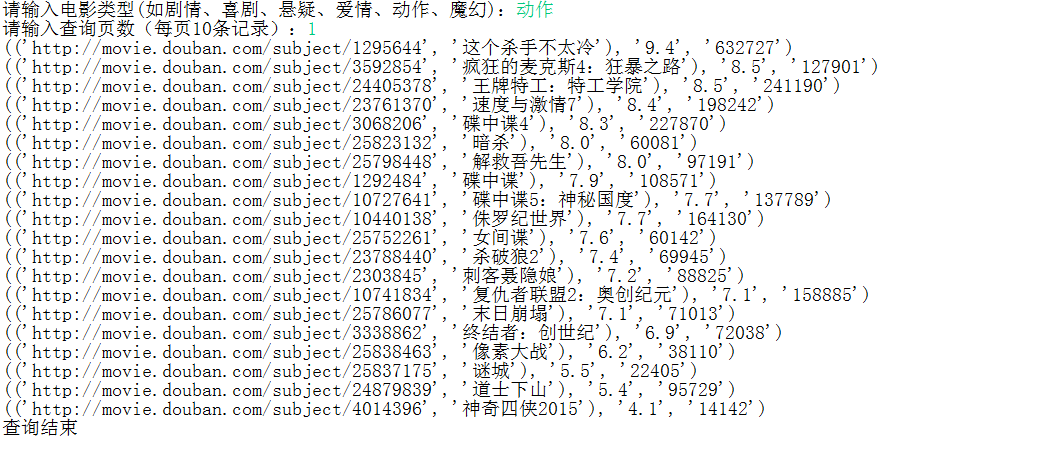
五、运行结果
一)输入相关信息

二)查看结果
六、总结
这个小功能的实现让我对使用正则表达式有了更深厚的理解,也理解了为什么在定义名称时为什么需要将名称规范化化,一旦没有规范,是无法对信息进行检索的,另外,这个功能也让我看到Python的list列表和Zip()方法的强大之处,在理解的基础上,他就像是在Java的list进行了多一层封装,不仅大大简化了我们所遍历条件,还能够自动获取其中的值,这为我们对列表数据的查询提供了巨大的优化,另外,我百度得知,这种封装大大提高了遍历的性能,在百万条数据中,比原来list的遍历要减少20%甚至更多的时间,所以,要熟悉Python的优势和长处,是需要不断地去体验Python的机制,其中最好的一点就是查阅API,zip()方法的封装亦是通过API才找出来的。
这个功能只是实现了简单的信息检索,其实还有很多可以改进的地方,第一、可以加入排序的条件,我觉得这个很重,可以跳高交互的友好度;第二,格式不太美观,排列不太整齐,这是zip()封装的一个弊端,因为他没有办法对数据进行再处理就直接被遍历出来了,如果换做其他方法,性能会降低,所以这是一个取舍问题;三、写出excel文件,一开始是计划写出excel文件,但是对excel文件的操作不是很熟悉,所以最终放弃,选择在控制台进行遍历,如果能找到类似POI这种开源框架支持Python对Excel的操作,相信能对EXCEL的写入写出有莫大的帮助。














 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









