






Master结点存在单点故障,所以要借助zookeeper,至少启动两台Master结点来实现高可用,配置方案比较简单
先停止所有Spark服务,然后安装zookeeper,并启动zookeeper
集群规划:

一、先安装Spark集群(Spark2.2.0安装教程)
二、安装zookeeper:(zookeeper安装教程)
三、高可用配置
在spark-env.sh上删掉SPARK_MASTER_IP配置项,并添加以下内容:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master.hadoop:2181,slave1.hadoop:2181,slave2.hadoop:2181 -Dspark.deploy.zookeeper.dir=/spark"
解释:
#-Dspark.deploy.recoverMode=ZOOKEEPER #代表发生故障使用zookeeper服务
#-Dspark.depoly.zookeeper.url=master.hadoop,slave1.hadoop,slave1.hadoop #主机名的名字
#-Dspark.deploy.zookeeper.dir=/spark #spark要在zookeeper上写数据时的保存目录
[root@master conf]# vi spark-env.sh
export JAVA_HOME=/apps/jdk1.8.0_171
export SCALA_HOME=/apps/scala-2.11.7
#export HADOOP_HOME=/apps/hadoop-2.8.0/
#export HADOOP_CONF_DIR=/apps/hadoop-2.8.0/etc/hadoop
#export SPARK_MASTER_IP=master.hadoop
export SPARK_WORKER_MEMORY=512m
export SPARK_WORKER_CORES=2
export SPARK_WORKER_INSTANCES=1
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=master.hadoop:2181,slave1.hadoop:2181,slave2.hadoop:2181 -Dspark.deploy.zookeeper.dir=/spark"
然后修改slaves文件
[root@master conf]# vi slaves
# A Spark Worker will be started on each of the machines listed below.
master.hadoop
slave1.hadoop
slave2.hadoop
四、启动
先启动zookeeper
可以单台启动,也可以写一个启动脚本,集体启动。
在每台机器上执行该命令:
[root@master /]# zkServer.sh start
启动脚本:https://blog.csdn.net/nuc2015/article/details/81045941
启动后一个leader,其他的是flower
在第一台机器上启动spark
[root@master spark-2.2.0]# sbin/start-all.sh
starting org.apache.spark.deploy.master.Master, logging to /apps/spark-2.2.0/logs/spark-root-org.apache.spark.deploy.master.Master-1-master.hadoop.out
master.hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /apps/spark-2.2.0/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-master.hadoop.out
slave1.hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /apps/spark-2.2.0/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave1.hadoop.out
slave2.hadoop: starting org.apache.spark.deploy.worker.Worker, logging to /apps/spark-2.2.0/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-slave2.hadoop.out
[root@master spark-2.2.0]# jps
2321 Jps
2149 Worker
2028 QuorumPeerMain
2076 Master
[root@master spark-2.2.0]#
在第二台机器上单独启动master
[root@slave1 spark-2.2.0]# sbin/start-master.sh
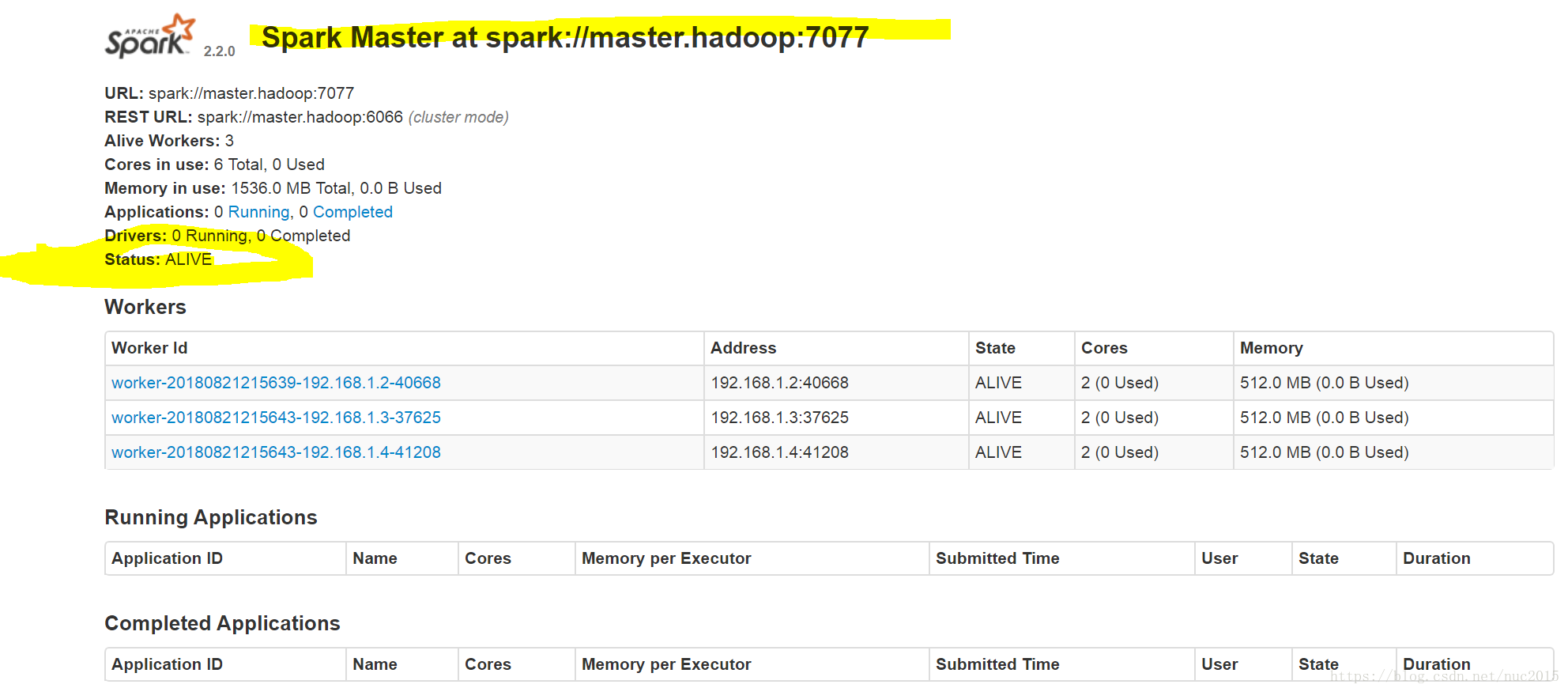
查看web端口
第一个master为
Status: ALIVE
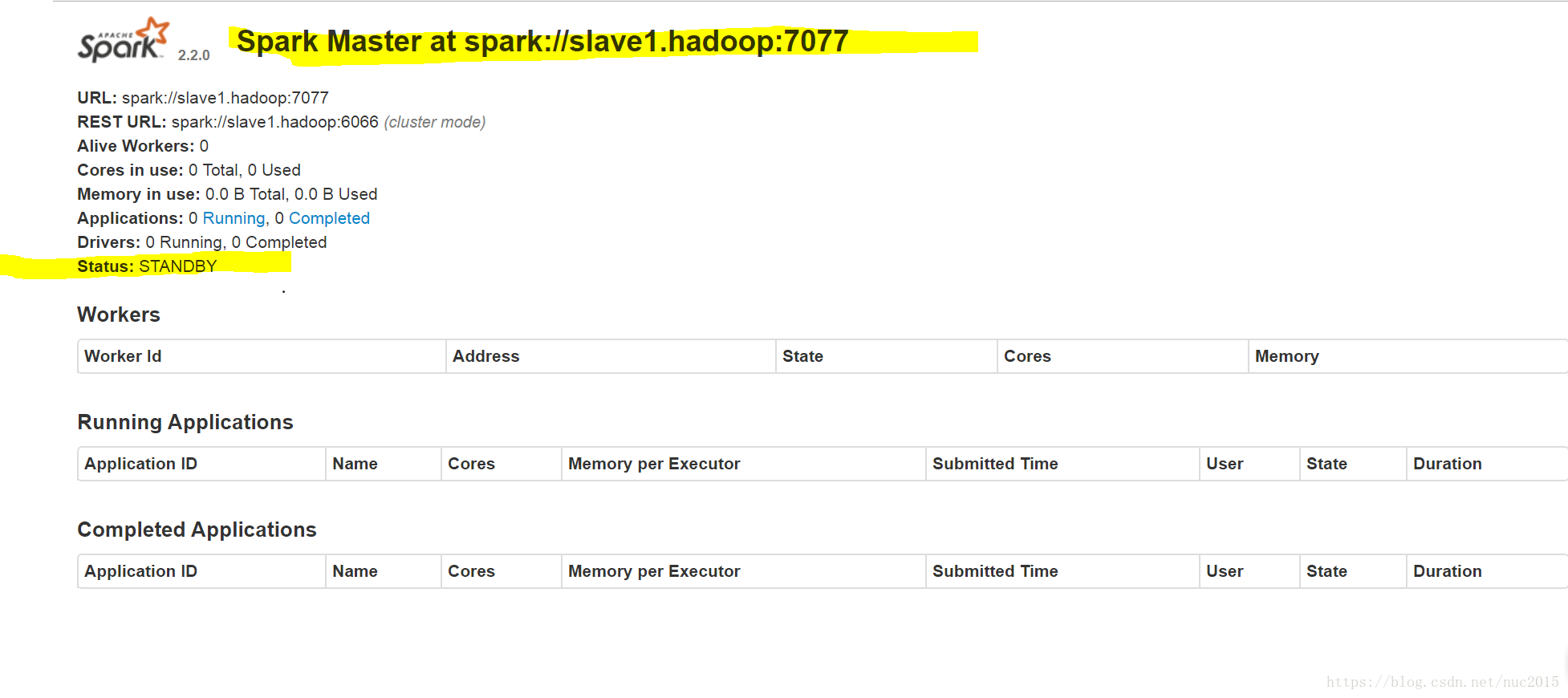
第二个master为
Status: STANDBY
搭建成功
————————————————














 946
946











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









