





【免责声明:用于教学资料整理】
目录:
一. 用箱线图检测异常值
二. 使用局部异常因子法(LOF法)检测异常值
三. 用聚类方法检测异常值
四. 检测时间序列数据中的异常值
五. 基于稳健马氏距离检测异常值
正文:
异常值,是指测量数据中的随机错误或偏差,包括错误值或偏离均值的孤立点值。在数据处理中,异常值会极大的影响回归或分类的效果。
为了避免异常值造成的损失,需要在数据预处理阶段进行异常值检测。另外,某些情况下,异常值检测也可能是研究的目的,例如,数据造假的发现、电脑入侵的检测等。
一、用箱线图检测异常值
在一条数轴上,以数据的上下四分位数(Q1-Q3)为界画一个矩形盒子(中间50%的数据落在盒内);在数据的中位数位置画一条线段为中位线;用◇标记数据的均值;默认延长线不超过盒长的1.5倍,之外的点认为是异常值(用○标记)。
盒形图的主要应用就是,剔除数据的异常值、判断数据的偏态和尾重。
R语言实现,使用函数boxplot.stats(),基本格式为:
[stats, n, conf, out]=
boxplot.stats(x, coef=1.5, do.conf=TRUE, do.out=TRUE)
其中,x为数值向量(NA、NaN值将被忽略);coef为盒须的长度为几倍的IQR(盒长),默认为1.5;do.conf和do.out设置是否输出conf和out
返回值:stats返回5个元素的向量值,包括盒须最小值、盒最小值、中位数、盒最大值、盒须最大值;n返回非缺失值的个数;conf返回中位数的95%置信区间;out返回异常值。
单变量异常值检测:
set.seed(2016)
x<-rnorm(100) #生成100个服从N(0,1)的随机数
summary(x) #x的汇总信息
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.7910 -0.7173 -0.2662 -0.1131 0.5917 2.1940
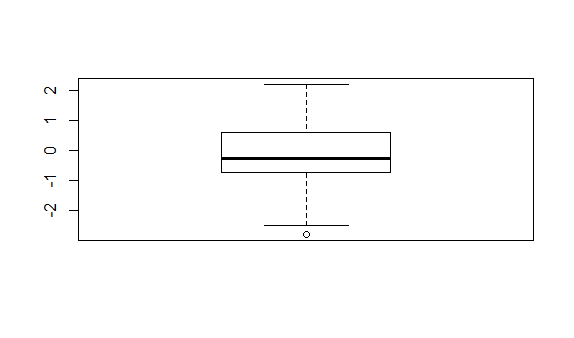
boxplot.stats(x) #用箱线图检测x中的异常值
$stats
[1] -2.5153136 -0.7326879 -0.2662071 0.5929206 2.1942200
$n
[1] 100
$conf
[1] -0.47565320 -0.05676092
$out
[1] -2.791471
boxplot(x) #绘制箱线图
多变量异常值检测:
x<-rnorm(100)
y<-rnorm(100)
df<-data.frame(x,y) #用x,y生成两列的数据框
head(df)
x y
1 0.41452353 0.4852268
2 -0.47471847 0.6967688
3 0.06599349 0.1855139
4 -0.50247778 0.7007335
5 -0.82599859 0.3116810
6 0.16698928 0.7604624
#寻找x为异常值的坐标位置
a<-which(x %in% boxplot.stats(x)$out)
a
[1] 78 81 92
#寻找y为异常值的坐标位置
b<-which(y %in% boxplot.stats(y)$out)
b
[1] 27 37
intersect(a,b) #寻找变量x,y都为异常值的坐标位置
integer(0)
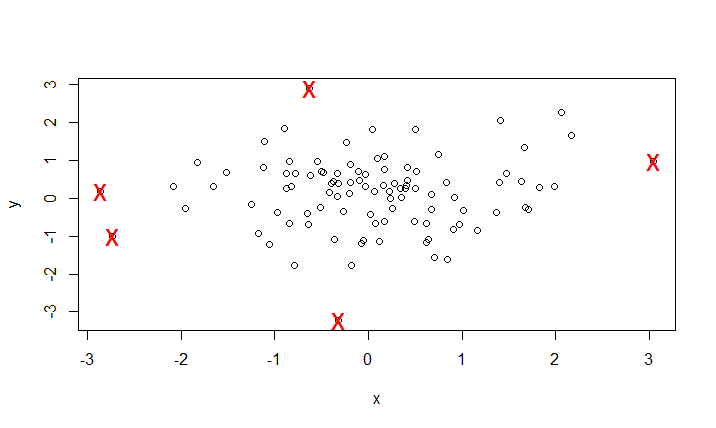
plot(df) #绘制x, y的散点图
p2<-union(a,b) #寻找变量x或y为异常值的坐标位置
[1] 78 81 92 27 37
points(df[p2,],col="red",pch="x",cex=2) #标记异常值
二、使用局部异常因子法(LOF法)检测异常值
局部异常因子法(LOF法),是一种基于概率密度函数识别异常值的算法。LOF算法只对数值型数据有效。
算法原理:将一个点的局部密度与其周围的点的密度相比较,若前者明显的比后者小(LOF值大于1),则该点相对于周围的点来说就处于一个相对比较稀疏的区域,这就表明该点是一个异常值。
R语言实现:使用DMwR或dprep包中的函数lofactor(),基本格式为:
lofactor(data, k)
其中,data为数值型数据集;k为用于计算局部异常因子的邻居数量。
library(DMwR)
iris2<-iris[,1:4] #只选数值型的前4列
head(iris2)
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.1 3.5 1.4 0.2
2 4.9 3.0 1.4 0.2
3 4.7 3.2 1.3 0.2
4 4.6 3.1 1.5 0.2
5 5.0 3.6 1.4 0.2
6 5.4 3.9 1.7 0.4
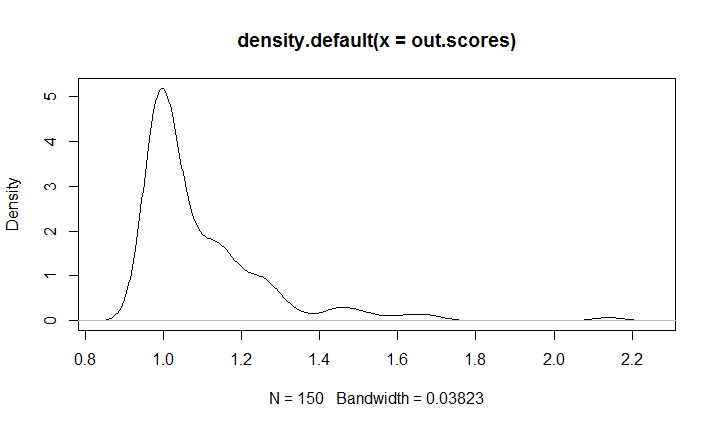
out.scores<-lofactor(iris2,k=10) #计算每个样本的LOF值
plot(density(out.scores)) #绘制LOF值的概率密度图
#LOF值排前5的数据作为异常值,提取其样本号
out<-order(out.scores,decreasing=TRUE)[1:5]
out
[1] 42 107 23 16 99
iris2[out,] #异常值数据
Sepal.Length Sepal.Width Petal.Length Petal.Width
42 4.5 2.3 1.3 0.3
107 4.9 2.5 4.5 1.7
23 4.6 3.6 1.0 0.2
16 5.7 4.4 1.5 0.4
99 5.1 2.5 3.0 1.1
对鸢尾花数据进行主成分分析,并利用产生的前两个主成分绘制成双标图来显示异常值:
n<-nrow(iris2) #样本数
n
[1] 150
labels<-1:n #用数字1-n标注
labels[-out]<-"." #非异常值用"."标注
biplot(prcomp(iris2),cex=0.8,xlabs=labels)
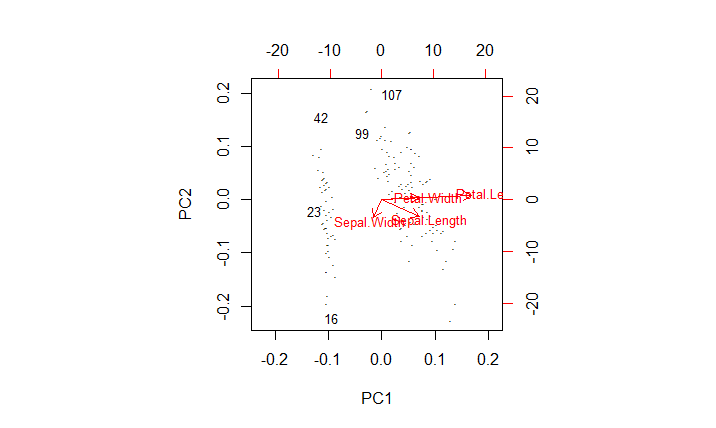
说明:函数prcomp()对数据集iris2做主成份分析,biplot()取主成份分析结果的前两列数据即前两个主成份绘制双标图。上图中,x轴和y轴分别代表第一、二主成份,箭头指向了原始变量名,其中5个异常值分别用对应的行号标注。
也可以通过函数pairs()绘制散点图矩阵来显示异常值,其中异常值用红色的"+"标注:
pchs<-rep(".",n)
pchs[out]="+"
cols<-rep("black",n)
cols[out]<-"red"
pairs(iris2,pch=pchs,col=cols)
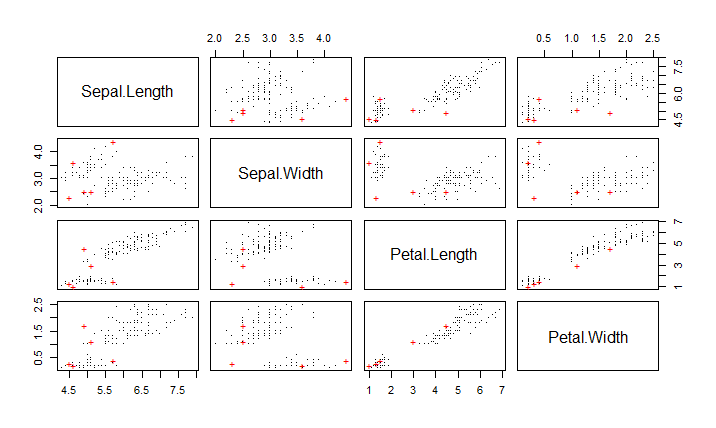
注:另外,Rlof包中函数lof()可实现相同的功能,并且支持并行计算和选择不同距离。
三、用聚类方法检测异常值
通过把数据聚成类,将那些不属于任何一类的数据作为异常值。比如,使用基于密度的聚类DBSCAN,如果对象在稠密区域紧密相连,则被分组到一类;那些不会被分到任何一类的对象就是异常值。
也可以用k-means算法来检测异常值:将数据分成k组,通过把它们分配到最近的聚类中心。然后,计算每个对象到聚类中心的距离(或相似性),并选择最大的距离作为异常值。
kmeans.result<-kmeans(iris2,centers=3) #kmeans聚类为3类
kmeans.result$centers #输出聚类中心
Sepal.Length Sepal.Width Petal.Length Petal.Width
1 5.901613 2.748387 4.393548 1.433871
2 5.006000 3.428000 1.462000 0.246000
3 6.850000 3.073684 5.742105 2.071053
kmeans.result$cluster #输出聚类结果
[1] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
[30] 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 1 1 3 1 1 1 1 1
[59] 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 1 1 1 1 1 1 1 1
[88] 1 1 1 1 1 1 1 1 1 1 1 1 1 3 1 3 3 3 3 1 3 3 3 3 3 3 1 1 3
[117] 3 3 3 1 3 1 3 1 3 3 1 1 3 3 3 3 3 1 3 3 3 3 1 3 3 3 1 3 3
[146] 3 1 3 3 1
#centers返回每个样本对应的聚类中心样本
centers <- kmeans.result$centers[kmeans.result$cluster, ]
#计算每个样本到其聚类中心的距离
distances<-sqrt(rowSums((iris2-centers)^2))
#找到距离最大的5个样本,认为是异常值
out<-order(distances,decreasing=TRUE)[1:5]
out #异常值的样本号
[1] 99 58 94 61 119
iris2[out,] #异常值
Sepal.Length Sepal.Width Petal.Length Petal.Width
99 5.1 2.5 3.0 1.1
58 4.9 2.4 3.3 1.0
94 5.0 2.3 3.3 1.0
61 5.0 2.0 3.5 1.0
119 7.7 2.6 6.9 2.3
#绘制聚类结果
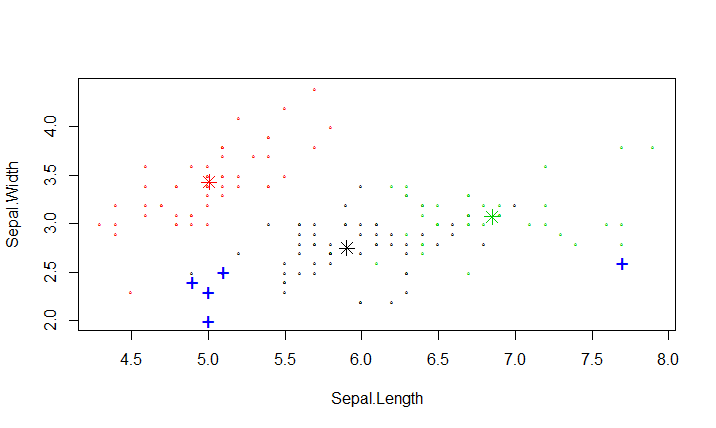
plot(iris2[,c("Sepal.Length","Sepal.Width")],pch="o",col=kmeans.result$cluster,cex=0.3)
#聚类中心用"*"标记
points(kmeans.result$centers[,c("Sepal.Length", "Sepal.Width")], col=1:3, pch=8, cex=1.5)
#异常值用"+"标记
points(iris2[out,c("Sepal.Length", "Sepal.Width")], pch="+", col=4, cex=1.5)
四、检测时间序列数据中的异常值
对时间序列数据进行异常值检测,先用函数stl()进行稳健回归分解,再识别异常值。
函数stl(),基于局部加权回归散点平滑法(LOESS),对时间序列数据做稳健回归分解,分解为季节性、趋势性、不规则性三部分。
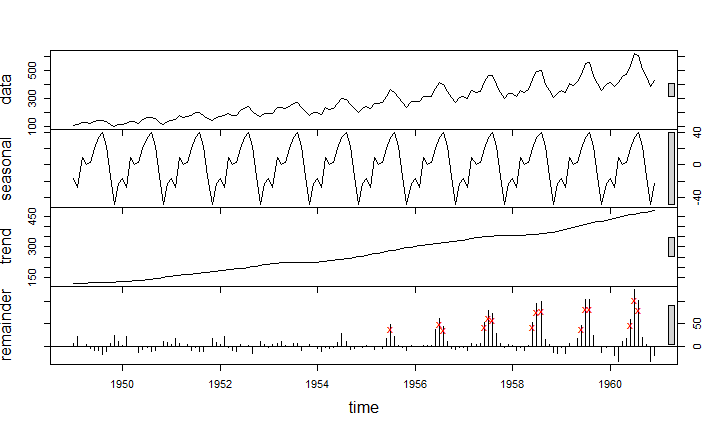
f<-stl(AirPassengers,"periodic",robust=TRUE)
#weights返回稳健性权重,以控制数据中异常值产生的影响
out<-which(f$weights < 1e-8) #找到异常值
out
[1] 79 91 92 102 103 104 114 115 116 126 127 128 138 139 140
#设置绘图布局的参数
op<-par(mar=c(0,4,0,3), oma=c(5,0,4,0), mfcol=c(4,1))
plot(f,set.pars=NULL)
#time.series返回分解为三部分的时间序列
> head(f$time.series,3)
seasonal trend remainder
[1,] -16.519819 123.1857 5.3341624
[2,] -27.337882 123.4214 21.9164399
[3,] 9.009778 123.6572 -0.6670047
sts<-f$time.series
#用红色"x"标记异常值
points(time(sts)[out], 0.8*sts[,"remainder"][out], pch="x", col="red")
par(op)
五、基于稳健马氏距离检测异常值
检验异常值的基本思路是观察各样本点到样本中心的距离,若某些样本点的距离太大,就可以判断是异常值。
若使用欧氏距离,则具有明显的缺点:将样本不同属性(即各指标变量)之间的差别等同看待。而马氏距离则不受量纲的影响,并且在多元条件下,还考虑到了变量之间的相关性。
对均值为μ,协方差矩阵为Σ的多变量向量,其马氏距离为
(x-μ)TΣ-1(x-μ)
但是传统的马氏距离检测方法是不稳定的,因为个别异常值会把均值向量和协方差矩阵向自己方向吸引,这就导致马氏距离起不了检测异常值的所用。解决方法是利用迭代思想构造一个稳健的均值和协方差矩阵估计量,然后计算稳健马氏距离,这样异常值就能正确地被识别出来。
用mvoutlier包实现,
library(mvoutlier)
set.seed(2016)
x<-cbind(rnorm(80),rnorm(80))
y<-cbind(rnorm(10,5,1), rnorm(10,5,1)) #噪声数据
z<-rbind(x,y)
res1<-uni.plot(z) #一维数据的异常值检验
#返回outliers标记各样本是否为异常值,md返回数据的稳健马氏距离
which(res1$outliers==TRUE) #返回异常值的样本号
[1] 81 82 83 84 85 86 87 88 89 90
res2<-aq.plot(z) #基于稳健马氏距离的多元异常值检验
which(res2$outliers==TRUE) #返回异常值的样本号
[1] 81 82 83 84 85 86 87 88 89 90
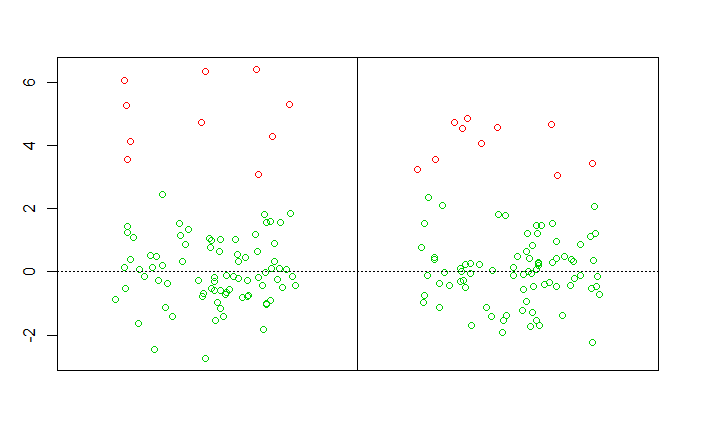
上图为在一维空间中观察样本数据。

说明:图1-1为原始数据;图1-2的X轴为各样本的稳健马氏距离排序,Y轴为距离的经验分布,红色曲线为卡方分布,蓝色垂线表示阀值,在阀值右侧的样本判断为异常值;图2-1和2-2均是用不同颜色来表示异常值,只是阀值略有不同。
若数据的维数过高,则上述距离不再有很大意义(例如基因数据有几千个变量,数据之间变得稀疏)。此时可以融合主成份降维的思路来进行异常值检验。mvoutlier包中提供了函数pcout()来对高维数据进行异常值检验。
data(swiss) #使用swiss数据集
res3<-pcout(swiss)
#返回wfinal01标记是否为异常值,0表示是
which(res3$wfinal01==0) #返回异常值的样本号
Delemont Franches-Mnt Porrentruy Broye
2 3 6 7
Glane Gruyere Sarine Veveyse
8 9 10 11
La Vallee Conthey Entremont Herens
19 31 32 33
Martigwy Monthey St Maurice Sierre
34 35 36 37
Sion V. De Geneve
38 45
注:对于分类数据,一个快速稳定的异常检测的策略是AVF (Attribute Value Frequency)算法。
主要参考文献:
《R语言-异常值处理1-3》,银河统计学,博客园
http://www.cnblogs.com/cloudtj/category/780800.html
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









