





工作中遇到的实际问题,应用比较多,比较好用的函数合集:
1.【GROUP_CONCAT】
①GROUP_CONCAT(列名):连接列里的所有非 NULL 的字符串,以逗号为默认的连接字符;
②GROUP_CONCAT(DISTINCT 列名 ORDER BY 列名 DESC SEPARATOR '$'):可以用DISTINCT 去掉重复值,可以加入ORDER BY进行排序,还可以用SEPARATOR指定不同的分隔符;
③GROUP_CONCAT(列名1,"$",列名2 SEPARATOR "$"):将多行多列数据,根据指定分隔符连接成一行一列,再根据需要分列,实际应用如下图:
原始表:
应用:

这个例子是此前工作中实际碰到的一个需求(数据已变更),需要将同个分组下的所有厂家对应的各自最低价,放到同一行。
此时的话就需要先将多行、多列的数据合并成一行一列,在利用分列拆分成一行多列。
注意点:
因为厂家的名字中可能会有“,”,所以分隔符不能使用默认的逗号,需要另外通过”SEPARATOR“进行设置,这样在分列的时候就可以根据新设置的分隔符进行分列,不会造成处理数据时部分数据错乱。
④注意点:最大长度限制默认值1024,当合并的总长度达到1024之后,后面的值就被截断了,可以进行如下设置:
1)SET GLOBAL group_concat_max_len = 102400;
2)SET SESSION group_concat_max_len = 102400。
-- -----以下更新于----- 20200925
2.【排名函数 rank、row_number、dense_rank、NTILE】
①区别:
rank:值相同的归为一组,名次相同,排序不会连续,遇到下一个不同的值,会跳到总的排名;
row_number:排名时序号连续不重复,也就是说,相同的值,也是按照连续数字进行排序,不重复;
dense_rank:值相同的归为一组,名次相同,但排序是连续的,遇到下一个不同的值,也还是按照连续的数字进行排名;
NTILE:把所有需要排名的数值,根据数值大小,平均分成n个组。
②应用:
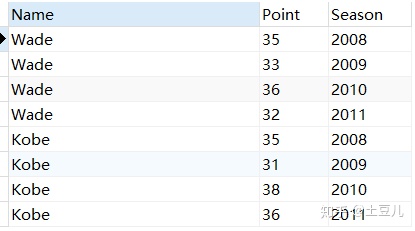
1)原始数据:
| Name | Season | Point |
|---|---|---|
| Wade | 2006 | 30 |
| Wade | 2007 | 36 |
| Wade | 2008 | 31 |
| Wade | 2009 | 33 |
| Wade | 2010 | 29 |
| Wade | 2011 | 28 |
| Wade | 2012 | 28 |
| Kobe | 2006 | 35 |
| Kobe | 2007 | 33 |
| Kobe | 2008 | 31 |
| Kobe | 2009 | 30 |
| Kobe | 2010 | 33 |
| Kobe | 2011 | 29 |
| Kobe | 2012 | 28 |
2)代码:
SELECT
3)结果:
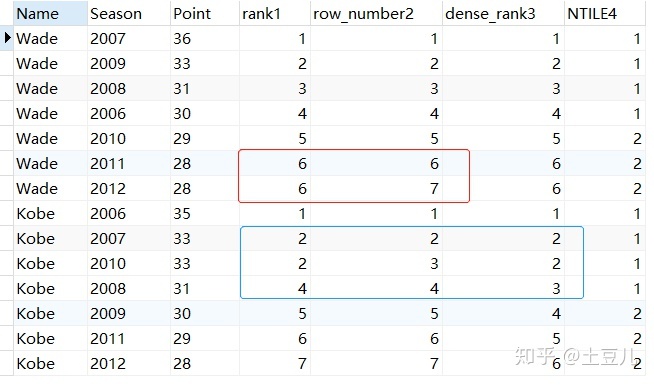
从上图的结果中,可以明显看出这几个排名函数的具体区别,根据需求选用合适的即可。
3.【聚合函数与OVER PARTITION BY相结合的妙用】
1)需求:根据上图结果新增一列,判断哪个赛季是最高分赛季,哪个赛季是最低分赛季,哪个赛季是其他赛季,分别打上标签;
2)思考:如果用CASE WHEN 排名= 1 ---> '最高分赛季',看起来好像没毛病,但是如果每个分组的个数是不定的,不相同的,没法确定最末尾的数字是多少(此例子比较特殊,个数都是7,但如果用的是rank或者dense_rank,排名尾数也是不一样的,也是没办法用CASE WHEN 来批量判断排名要等于多少才是对应的最低分赛季),因此就需要用到聚合函数与OVER PARTITION BY相结合;
3)代码:
WITH 4)结果:
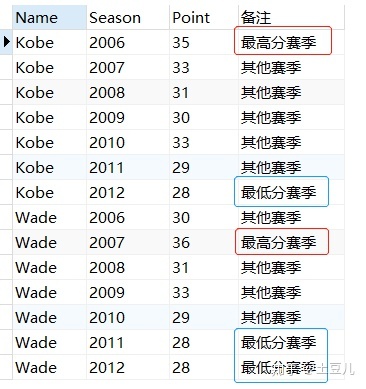
5)Tips:第三小点的代码中有用到WITH Table Name AS (代码块),这个就是比较常应用于,当你的这段代码块需要重复使用的时候,需要利用他关联好几个地方,关联好几个表,就可以使用这个语句,避免过多的子查询,用一个表名即可解决,让代码看起来比较简洁,排查定位问题也比较精准。
-- -----以下更新于-----20200926
4.【日期时间函数】
①1)解释:将日期加上一个指定的间隔时间
date:合法的日期;
expr:时间间隔(可正可负,负的时候相当于date_sub()函数);
unit:用的比较多的就是HOUR、DAY、WEEK、MONTH、QUARTER、YEAR。
2)代码:
SELECT --------------------------------------------
②与date_add同样的用法,当expr为正数时,add是加,sub是减;当expr为负数时,add是减,sub是加。
③1)解释:返回两个日期之间的天数(date1 - date2)
2)代码:
SELECT --------------------------------------------
④1)解释:返回两个时间之间的时间差(time1 - time2)
2)代码:
SELECT --------------------------------------------
接下来这个时间函数应用是最多的!!!!!因为他功能比较强大。
⑤1)解释:返回两个日期之间的数值(datetime_expr2 - datetime_expr1)
unit:是类型,返回可以是DAY、WEEK、MONTH、QUARTER、YEAR
2)代码:
SELECT --------------------------------------------
⑥1)解释:相当于date_add()函数
2)代码:
SELECT 














 2711
2711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









