





作者 | 糖甜甜
地址 | https://mp.weixin.qq.com/s/aicB4K2o_TzserWazTyCrw
这一讲,我会为大家讲解常见的静态页面(同步加载)爬虫技巧以及一般网页的分析过程。
静态网页手动分析方法和工具
我们以作者初学爬虫时发现的一个站点作为第一个案例,宅男可能会发现一个新大陆括弧笑,给大家隆重介绍这个站点------豆瓣妹子(若链接失效请访问:https://www.dbmeinv.com/)。放一张截图激发一下大家学习的热情:
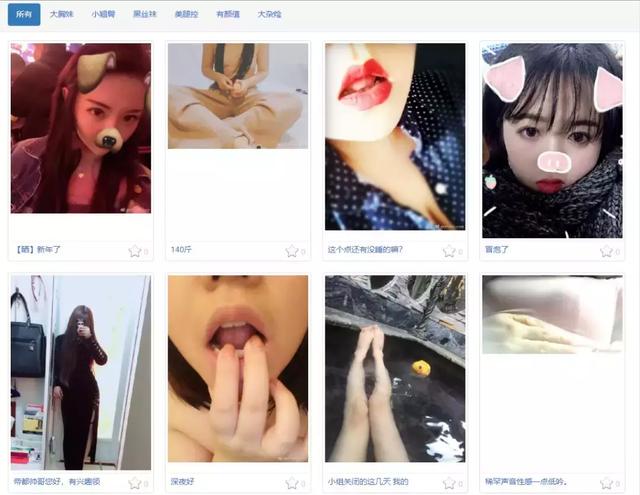
生活学习中,我们可能有时需要收集很多的图片,比如做机器学习的图像识别,就是建立在数以亿计的图片基础上通过一定的算法训练学习出来的。这里以这个网站为例,假装我们需要下载很多的妹子的图片。从这个网页上看,妹子图片是不少,但是要把这些图片一一保存到我们的本地文件夹里,只能一个一个的在图片上右键,选择"图片另存为",能不能由计算机快速的、批量的完成这一枯燥的工作呢?答案当然是肯定的,毕竟这是爬虫专场教程。
首先,需要给大家科普的一点就是,爬虫的核心并不是爬,而是对网页的分析,拿到一个陌生的网页,如何获取到自己想要的最干净、最简洁、最稳定的部分,才是爬虫的奥义所在,因此,我将首先教大家如何分析一张简单的网页。
这里要用到的工具是Chrome Developer Tools。这是谷歌浏览器内嵌的一个开发者工具,我们可以按F12打开它,或者在网页空白处右键,选择检查(N),或者按住默认快捷键Ctrl + Shift + I来召唤这个工具。开发者工具大概长下面这个样子:
在这一讲里,我们介绍的网页主要内容不是由异步获取的,而是随网页的加载同步生成的,因此主要用到的是开发者工具左上角的元素选取工具(我是这么叫的。。可能不专业),也就是下图红色框中的那个按钮:
点击一下这个按钮,按钮会变成蓝色的选取状态,如下图:

这时候将鼠标移至我们需要的网页元素上,比如这里我们想下载图片,就将鼠标移至图片上,图片上会出现一个淡蓝色的浮层,如下图所示:

这时候再次点击鼠标,开发者工具便会将代码定位到图片所在位置的代码,并用蓝色高亮显示,如下图所示:
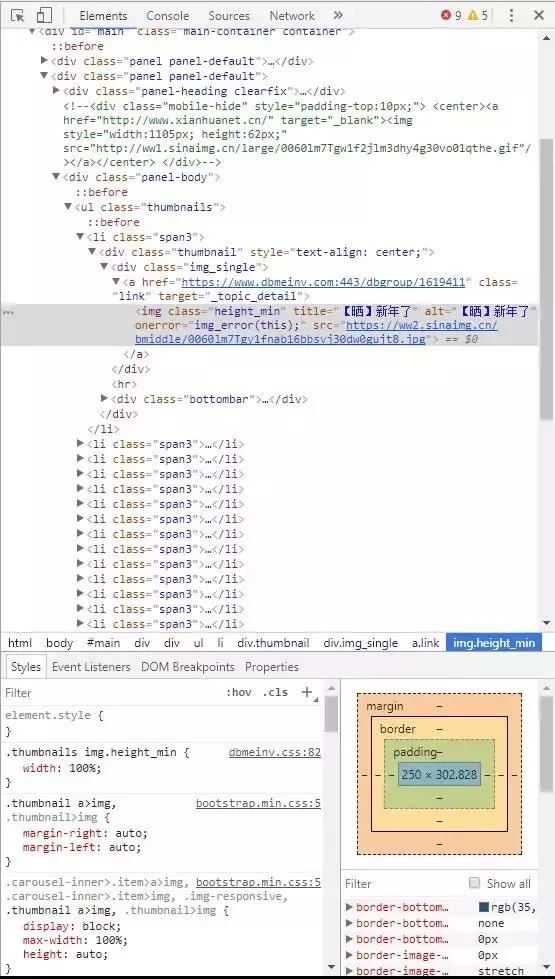
在这里,我们可以在img标签里找到图片的真实地址。
网页解析模块 -- BeautifulSoup
以上是我们手动分析网页的过程,那么如何用Python语言将这一过程自动化,实现批量的下载图片呢?这里需要再给大家介绍一个新的模块,叫做Beautifulsoup。
BeautifulSoup是一个可以从HTML或XML文件中提取数据的Python库。它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。Beautiful Soup会帮你节省数小时甚至数天的工作时间。(解释来自Beautiful Soup 4.2.0 文档(若链接无法打开,请访问https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html))
简单的说,Beautifulsoup就是一个用来解析网页的模块,同样,我们用第一讲所说的pip工具来安装,由于Beautifulsoup 3已经停止维护,Beautifulsoup模块迁移到bs4,因此,我们需要在命令行输入pip install bs4来完成Beautifulsoup模块的安装,完成后使用from bs4 import BeautifulSoup进行调用。
如第一讲一样, 先写一个demo:
# -*- coding: utf-8 -*-from bs4 import BeautifulSoupimport requestsurl = 'https://www.dbmeinv.com/'headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'}response = requests.get(url=url, headers=headers)content = response.content.decode()soup = BeautifulSoup(content, 'html.parser') # 注释1img_list = soup.find_all(name='img', class_='height_min') #注释2for img in img_list: # 注释3 src = img.attrs['src'] # 注释4 title = img.attrs['title'] # 注释5 response = requests.get(url=src, headers=headers) content = response.content with open('image/%s.jpg' % title, 'wb') as f: # 注释6 f.write(content)- 注释1:这里新建了一个Beautifulsoup对象,它有两个必要的参数,第一个参数是HTML代码对象,比如这里content存储了URL为"https://www.dbmeinv.com/"的这张网页的HTML代码,它是个字符串或者是一个文件句柄第二个参数是HTML解析器,这个解析器可以使用内置标准的"html.parser",也可以安装第三方的解析器,比如lxml和html5lib。
- 说到"lxml"模块的安装,我们需要再一次使用第一讲所提到的pip工具来安装。按照第一讲所说的,我们可以在命令行里直接输入pip install lxml来安装。但是,这里有点小问题,或许是不兼容,或许是其他什么原因,作者也没有去详细了解,导致无法正确安装lxml模块,在这里给大家推荐一个网站Unofficial Windows Binaries for Python Extension Packages(若链接失效请访问:https://www.lfd.uci.edu/~gohlke/pythonlibs/),可以理解为这是一个Python非标准库的合集,专业治疗各种pypi版模块不能正确安装的问题,里面有很多模块,选择对应Python版本的就可以安装了。网页截图如下:
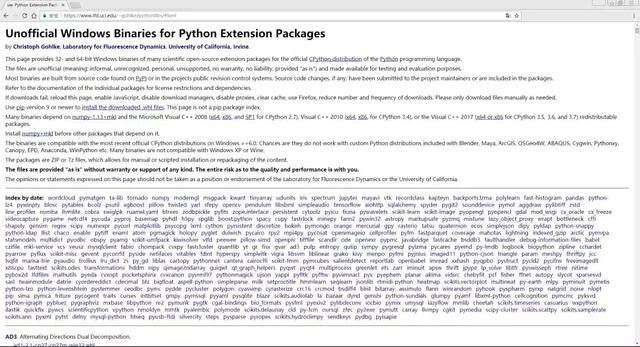
- 比如我们要安装基于32位Python 3.5版本的lxml模块,就可以按Ctrl + F查询lxml然后找到如下图的内容:
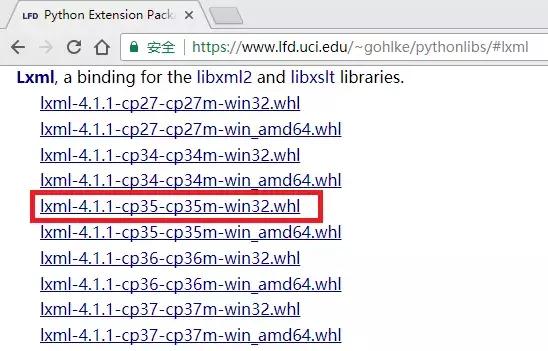
- 点击红色框中的内容便可以下载,下载完成后,打开命令行 ,切换到下载文件的目录,执行命令pip install lxml-4.1.1-cp35-cp35m-win32.whl(这里一定要写完整的文件名),便可以成功安装lxml模块了。
- "html5lib"模块因为作者没使用过,所以不多说了,大家可以自行尝试。
- 附:几种解析器的对比:(参考Beautifulsoup官方文档)
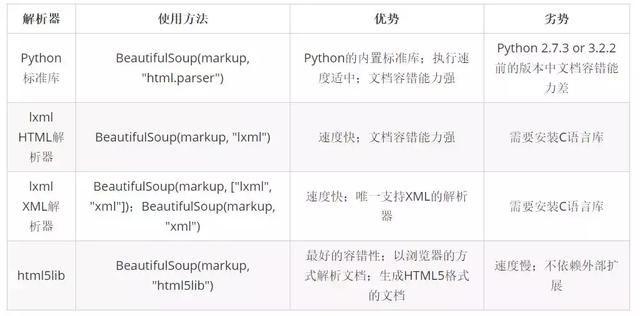
- 注释2:这里使用了soup对象的一个方法"find_all()",字面理解就是"找出所有的",那么找出什么,如何定位这个所谓的"什么"?这里就要传入两个参数,第一个是HTML文档的节点名,也可以理解为HTML的标签名;第二个则是该节点的class类名,比如上面代码中,我要找出该网页上所有的img节点,且我需要的img节点的类名为"height_min"。但是对于一些没有class类名的HTML元素我们该如何寻找?
- 我们还可以用到另一个属性:attrs,比如这里可以写成:
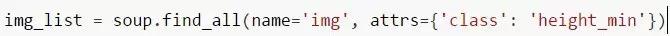
attrs是字典类型,冒号左边为关键字,右边为关键字的值。不一定要通过class来查找某一个元素,也可以通过比如"id","name","type"等各种HTML的属性,如果想要的元素实在没有其他属性,可以先定位到该元素的父属性,再使用".children"定位到该元素。更多Beautifulsoup的高级用法请参考上面的"Beautiful Soup 4.2.0 文档"。
- 注释3:注释2返回的是一个列表对象,包含了整张网页上的图片,因此这里用一个循环,分别处理每一张图片。
- 注释4:因为img实际上是一个BeautifulSoup的Tag对象,所以可以通过"attrs"属性将img解析为一个字典对象,通过键值"src"取出图片的真实地址。
- 注释5:同注释4,取出了图片的标题,作为图片的文件名。
- 注释6:这里需要重新请求图片的地址,获得图片二进制的返回值,因为是图片,所以不能用decode()解码,必须以二进制的方式写入,后面的写入模式"wb",加了个"b"就是表示以二进制的形式,具体Python文件的读写请参考一篇博文:Python 文件I/O | 菜鸟教程(若链接失效请访问:http://www.runoob.com/python/python-files-io.html)。
本讲小结
本讲主要为大家讲解了两个知识点:
- 静态网页的手动分析方法和工具
- 网页解析模块 ------ BeautifulSoup
在这里建议大家使用Google Chrome作为默认浏览器,当然FireFox也可以,作者比较偏好谷歌,个人喜好吧啊哈哈,还有就是Chrome的开发者工具确实很强大,还有其他很多功能将在后面的章节为大家继续讲解。
至于Beautifulsoup的功能也非常强大,作者这里只是以取出图片作为一个例子,还可以取出很多的东西,至于有的童鞋想实现"翻页下载",我就给大家提供一个思路,就是去获取页面翻页按钮的链接地址,如果能发现什么URL的规律,就很方便了,再嵌套一个for循环或者while循环就好了,如果没什么规律,那大概就是后面要说的动态页面的内容了(我刚才试了一下还是有规律的,大家可以举一反三,自行尝试)。另外,豆瓣妹子有反爬虫系统,在爬取一定数量的图片后,会无法爬取,这个我也将在后面为大家讲解。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









