





要点
1.子查询结果只允许返回单行,子查询包括相关子查询:在主查询中,每查询一条记录,需要重新做一次子查询,这种称为相关子查询。非相关子查询:在主查询中,子查询只需要执行一次,子查询结果不再变化,供主查询使用,这种查询方式称为非相关子查询。
2.select后面的子查询只允许返回单行,用于增加字段;from后面的子查询通常是为了提高SQL的运行效率和避免产生重复数据;where中的子查询除了 in、not in、exists、not exists后接的子查询可返回多行外,其他避免返回多行,in后尽量用多表连接。
4.聚合函数
5.多表查询(笛卡尔集、等值连接、外连接、自连接)
6.集合操作union all(常用)、union、insersect、minus
7 、取最后一条记录
8、rownum
9、rowid
10、树结构
11、分析函数
一、in /not in/exixts/not exixts
1、 查询请过假的员工信息:emp_no,emp_name,dep_name
(1)首先明确查哪些列 select ……
(2)然后明确查哪个表 from ……
(3)明确条件:你要取得是什么?lea.emp_id=emp.emp_id,从这里下手,你要取得是(select 后面那个),那么你要取得这个有什么条件吗?后面跟着
(4)exists 与in 的用法在于___________地方不一样
它们搜索不同之处在于:EXISTS当查到满足条件的即退出子查询,IN全部匹配完子查询结果才退出子查询
1) 使用IN 实现:
select emp.emp_no,emp.emp_name,dep.dept_name from SIE_EMP_qyy emp,SIE_DEPT_qyy dep
where emp.dept_no=dep.dept_no and
emp.emp_id in(select lea.emp_id from SIE_EMP_LEAVE_qyy lea where lea.emp_id=emp.emp_id
and lea.days>0 )
2) 使用exists实现:
select emp.emp_no,emp.emp_name,dep.dept_name from SIE_EMP_qyy emp,SIE_DEPT_qyy dep
where emp.dept_no=dep.dept_no and
EXISTS (select lea.emp_id from SIE_EMP_LEAVE_qyy lea where lea.emp_id=emp.emp_id
and lea.days>0 )
2、 查询没有请过假的员工信息:emp_no,emp_name,dep_name
3)使用not IN 实现:
select emp.emp_no,emp.emp_name,dep.dept_name from SIE_EMP_qyy emp,SIE_DEPT_qyy dep
where emp.dept_no=dep.dept_no and
emp.emp_id not in(select lea.emp_id from SIE_EMP_LEAVE_qyy lea where lea.emp_id=emp.emp_id
and lea.days>0 )
4)使用not exists实现
select emp.emp_no,emp.emp_name,dep.dept_name from SIE_EMP_qyy emp,SIE_DEPT_qyy dep
where emp.dept_no=dep.dept_no and
not EXISTS (select lea.emp_id from SIE_EMP_LEAVE_qyy lea where lea.emp_id=emp.emp_id
and lea.days>0 )
in:in在查询的时候,首先查询子查询的表,然后将内表和外表做一个笛卡尔积,然后按照条件进行筛选。所以相对内表比较小的时候,in的速度较快。
exists:指定一个子查询,检测行的存在。遍历循环外表,然后看外表中的记录有没有和内表的数据一样的。匹配上就将结果放入结果集中。
二、子查询
select后面的子查询只允许返回单行,用于增加字段;from后面的子查询通常是为了提高SQL的运行效率和避免产生重复数据;where中的子查询除了 in、not in、exists、not exists后接的子查询可返回多行外,其他避免返回多行,in后尽量用多表连接。
三、聚合函数(avg(xxx)平均、sum(xxx)求和、max(xxx)求最大值、min(xxx)求最小值、count(xxx)统计行数)不能出现在where后的字句中
count(*)、count(1)统计所有行数量,count(字段)统计该列非空行数量
count(distinct 某一列名)统计该列非空不重复行数量,
count:count(*)统计所有行,包括空值;
聚合函数不能出现在where中
四、多表查询
【SQL】SQL中笛卡尔积、内连接、外连接的数据演示
https://www.cnblogs.com/nick-huang/p/4919178.html#my_inner_label1
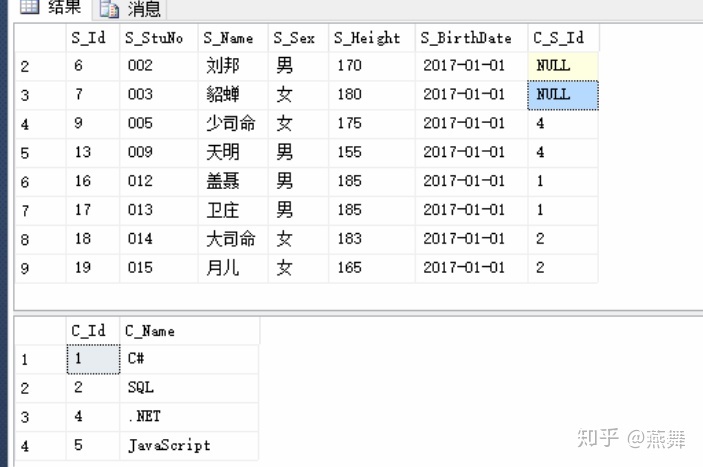
1.等值连接(内连接):表与表之间有相同的字段和存储内容用等号连接
where emp.C_SId=dep.C_Id ------emp表中的dept_no与dep表中的dept_no有相同的内容
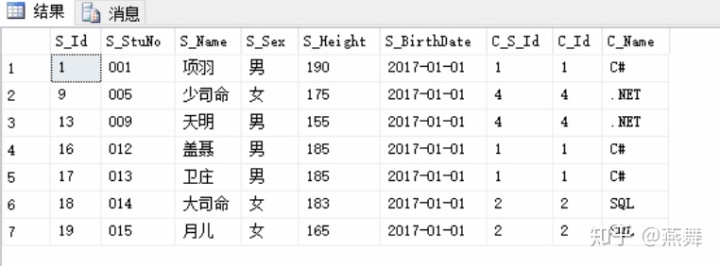
2.外连接:主表(主导表)关联到缺乏表(从表)。需要外连接的表,则关联到该表上的所有字段都必须采用外连接。一个表不能被多个表外连接
(1)左外连接
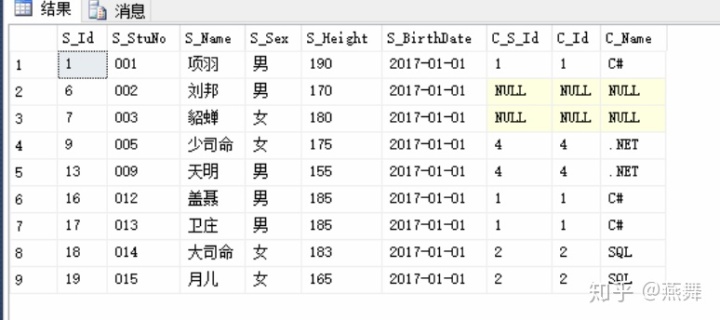
(2)右外连接
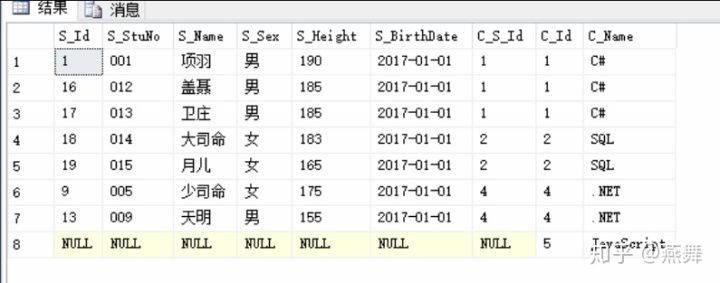
(3)全外连接
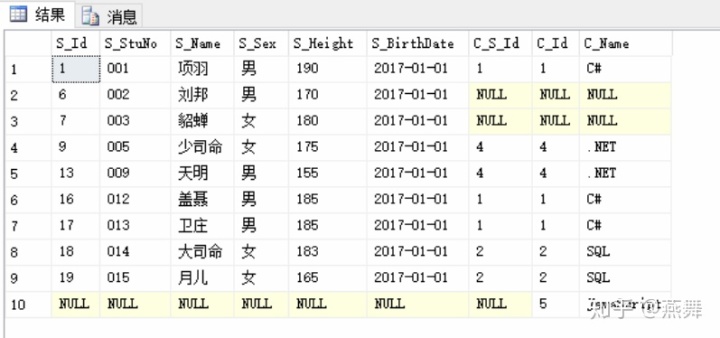
五、UNION ALL不去重,不排序,做加集(A + B)(常用)
UNION去重,按第一列排序,做并集(A U B )
INSERSECT 做交集(A ∩ B )
MINUS 做差集(A - B)
union all:

注意:
order by只能排在select语句的最后面,且是对所有结果集进行排序每段的列的个数及数据类型要一致,名称可不同
最终结果各字段列名与第一段同
排序只能加在最后,但却是对整个结果集的排序
order by 后可以是第一段中的列名、别名、位置记号
order by 后不可出现SELECT后没有出现的列
六、rownum伪列
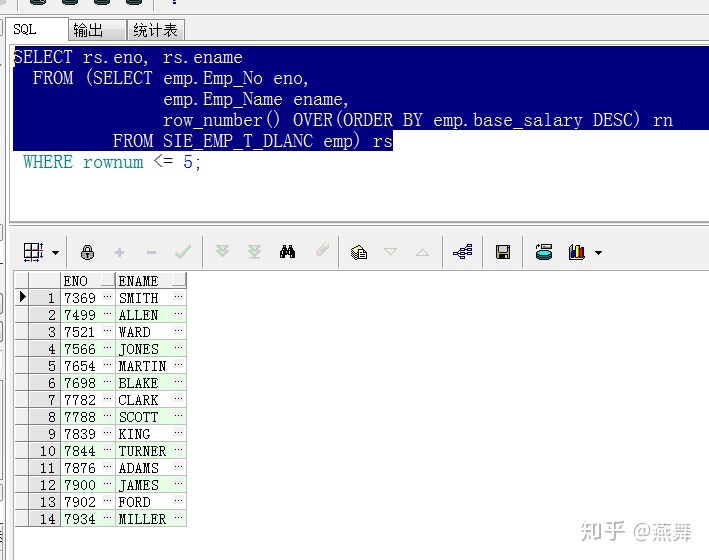
查询出员工表中的前5条员工记录:
select bs.* from(Select emp_no,emp_name from sie_emp_t order by base_salary )bs where rownum<=5 --------显示前五行
where rownum<=1 --------显示第一行
where rownum>=1 --------显示所有
where rownum>=2、3、4、5…… --------显示为没有
where rownum=2、3、4、5…… --------显示为没有
where rownum=1 --------显示第一行
where rownum<>n --------显示前n-1行
七、分析函数
1、排名函数
函数为每条记录产生一个从1开始至n的自然数,n的值可能小于等于记录的总数。这3个函数的唯一区别在于当碰到相同数据时的排名策略。
1.1 row_number() over()
row_number()返回一个唯一的值,当碰到相同数据时,排名按照记录集中记录的顺序依次递增。
1.2 rank() over()
rank()返回一个唯一的值,当碰到相同的数据时,此时所有相同数据的排名是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间空出排名。
1.3 dense_rank() over()
dense_rank()返回一个唯一的值,当碰到相同数据时,此时所有相同数据的排名都是一样的,同时会在最后一条相同记录和下一条不同记录的排名之间紧邻递增。
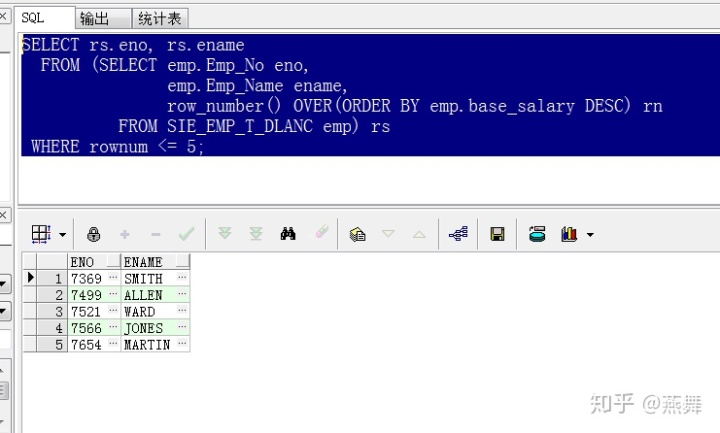
查询出员工表中的前5条员工记录:
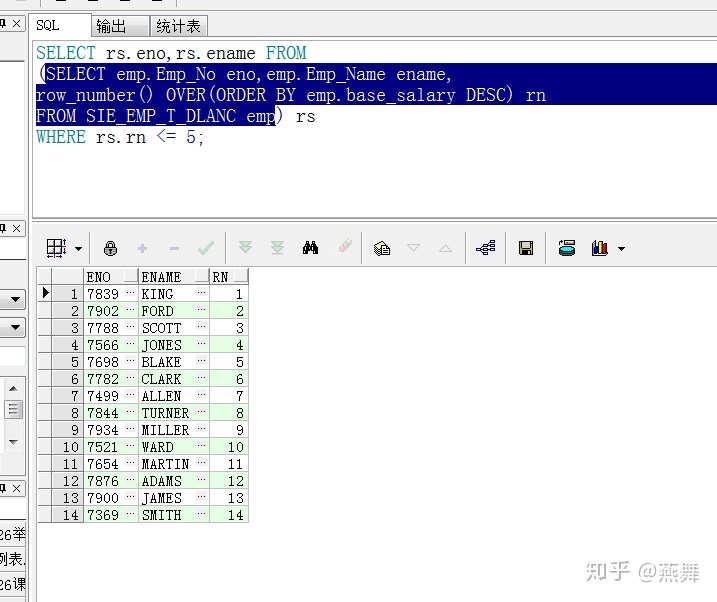
SELECT rs.eno,rs.ename FROM
(SELECT emp.Emp_No eno,emp.Emp_Name ename,
row_number() OVER(ORDER BY emp.base_salary DESC) rn
FROM SIE_EMP_T_DLANC emp) rs
where rownum<=5
row_number() OVER(ORDER BY emp.base_salary DESC) --为表排序用row_number(),按照emp.base_salary降序排列
八、rowid
rowid为物理id,定位记录的最快速方法
九、动态SQL
1、 在一个PL/SQL块中实现:使用动态SQL备份sie_dept_t表中数据;按第8题要求查询数据,并存储到联合数组中;遍历联合数组,若部门表sie_dept_t中对应该部门的avg_salary为空或者不为空但不等于avg_salary_dept,则将该部门表中的avg_salary的值更新为avg_salary_dept,更新成功后输出emp_no,emp_name,old_avg_salary(更新前平均薪水),new_avg_salary(更新后平均薪水);其它要求:更新部门表时根据rowid更新,且每个部门只更新一次avg_salary。
DECLARE
v_sql varchar2(100);
v_t varchar2(30):='v_tab_dept';
type rec_type is record(
v_dept_no LISI_DEPT_T.DEPT_NO%type,
v_dept_name LISI_DEPT_T.DEPT_NO%type,
v_emp_no LISI_EMP_T.EMP_NO%type,
v_emp_name LISI_EMP_T.EMP_NO%type,
v_leave_days number,
v_sum_salary lisi_emp_payment_t.last_salary%type,
v_avg_salary number
);
type v_tab is table of rec_type index by binary_integer;
v_tab_arr v_tab;
cursor cur_tab is (SELECT EMP.DEPT_NO deptno,
DEPT.DEPT_NAME,
EMP.EMP_NO,
EMP.EMP_NAME,
LEAVE.LEAVE_DAYS,
PAYMENT.SUM_SALARY,
ROUND(SUM(PAYMENT.SUM_SALARY)
OVER(PARTITION BY EMP.DEPT_NO) / COUNT(EMP.EMP_ID)
OVER(PARTITION BY EMP.DEPT_NO),
2) AS AVG_SALARY_DEPT
FROM LISI_EMP_T EMP,
LISI_DEPT_T DEPT,
(SELECT LEAVE.EMP_ID, SUM(LEAVE.DAYS) AS LEAVE_DAYS
FROM LISI_EMP_LEAVE_T LEAVE
GROUP BY LEAVE.EMP_ID) LEAVE,
(SELECT PAYMENT.EMP_ID, SUM(PAYMENT.LAST_SALARY) AS SUM_SALARY
FROM LISI_EMP_PAYMENT_T PAYMENT
GROUP BY PAYMENT.EMP_ID) PAYMENT
WHERE EMP.DEPT_NO = DEPT.DEPT_NO(+)
AND EMP.EMP_ID = LEAVE.EMP_ID(+)
AND EMP.EMP_ID = PAYMENT.EMP_ID(+));
v_salary number;
v_dno varchar2(30):='';
v_rid varchar2(100);
begin
/*
BEGIN
v_sql:='create table '||v_t||' as (select * from lisi_dept_t)';
execute immediate v_sql;
END;
*/
begin
open cur_tab;
fetch cur_tab BULK COLLECT into v_tab_arr;
for i in 1..v_tab_arr.count loop
if i>1 and v_tab_arr(i).v_dept_no=v_dno then
continue;
else
--dbms_output.put_line('1');
select avg_salary,rowid into v_salary,v_rid from lisi_dept_t where dept_no=v_tab_arr(i).v_dept_no;
--dbms_output.put_line(v_salary);
if(v_salary=null or v_tab_arr(i).v_AVG_SALARY!=v_salary) then
update lisi_dept_t set avg_salary=v_tab_arr(i).v_AVG_SALARY where rowid=v_rid;
-- if sql%rowcount >0 then
dbms_output.put_line('员工编号:'||v_tab_arr(i).v_emp_no||' 员工姓名:'||v_tab_arr(i).v_emp_name||' 更新前平均薪水:'||v_salary||' 更新后平均薪水:'||v_tab_arr(i).v_AVG_SALARY);
--end if;
end if;
end if;
v_dno:=v_tab_arr(i).v_dept_no;
dbms_output.put_line(v_dno);
end loop;
close cur_tab;
exception when others then
dbms_output.put_line('出错了');
end;
end;
-- select * from lisi_dept_t;
-- rollback
删表中重复数据
DELETE FROM TABLE_NAME
WHERE ROWID NOT IN (SELECT MAX(ROWID)
FROM TABLE_NAME D
group by d.col1,d.col2);














 1523
1523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









