






 本文介绍了如何使用Python的scikit-learn库进行回归分析,包括加载鸢尾花数据集,探索数据,建立线性回归模型,进行预测以及评估预测性能。通过交叉验证方法评估模型的均方误差,展示了特征选择对模型性能的影响。
本文介绍了如何使用Python的scikit-learn库进行回归分析,包括加载鸢尾花数据集,探索数据,建立线性回归模型,进行预测以及评估预测性能。通过交叉验证方法评估模型的均方误差,展示了特征选择对模型性能的影响。
预测型数据分析有很多很多种分析的类型,回归、分类和聚类是预测型数据分析的几种主要的类型。
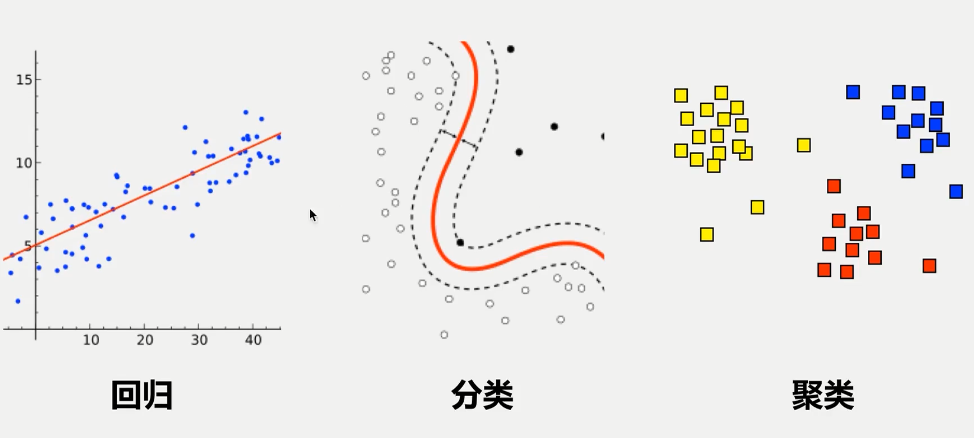
回归和分类属于监督型学习,回归分析在于了解两个或多个变量间是否相关、相关方向与强度,并建立数学模型以便观察特定变量(变量组)来预测研究者感兴趣的变量(因变量),可以帮助了解在只有一个自变量变化时因变量的变化量。而分类的和回归非常类似,分类的因变量是离散的,用离散的数值类进行分类。比如说我们有一些已知植物的属性(分类、叶长、叶宽、花瓣数),建立分类回归模型,通过新的一个样本的叶长、叶宽、花瓣数去预测这个样本的分类。
下面我们说说回归分析
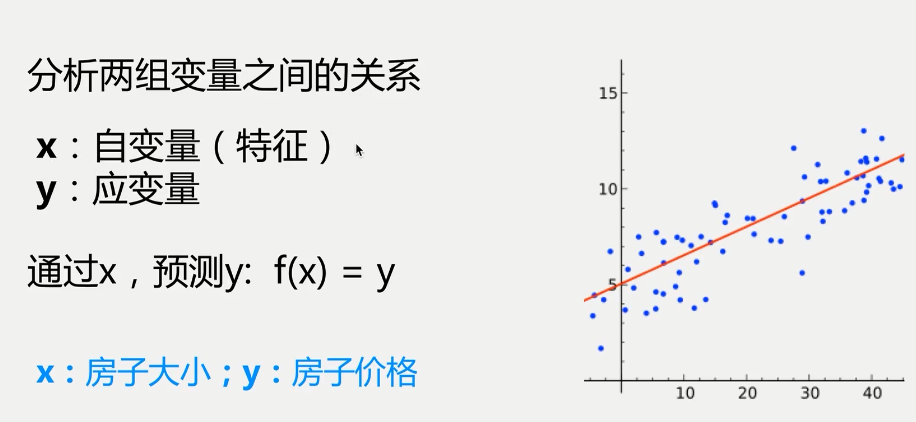
x自变量也叫特征,可以是一维或者多维,y是因变量,我们通过已知的x和y,建立一个y和x之间的函数来评估x和y之间的关系,进行用新的x去预测y。
关于回归分析及通过excel进行回归分析,可以参考我的这篇文章《利用EXCEL函数LINEST进行统计学中的回归分析》,在我的另一篇文章《传统IT应用如何拥抱大数据?谈python大数据的应用落地方法》也有用Python的statsmodels模块如何实现回归分析的应用。
在python中实现回归分析
Python中实现线性回归的主流包是scikit-learn,下面我们一步一步来通过scikit-learn实现回归分析和预测性能的评估。
首先我们来了解一下核心代码
from sklearn import linear_model #引入python的sklearn模块
lm = linear_model.LinearRegression() #创建一个线性回归模型
model = lm.fit(X,y)#对回归模型进行拟合
下面我们从头开始一个完整的回归分析、预测和预测性能评估。
1 加载数据(鸢尾属植物数据集)
mport pandas
iris = pandas.read_csv('http://archive.ics.uci.edu/ml/machine-learning-databases/iris/iris.data',header=None)
iris.columns=['SepalLengthCm','SepalWidthCm','PetalLengthCm','PetalWidthCm','Species']
我们通过下面的代码查看数据
iris.sample(10)
数据如下:
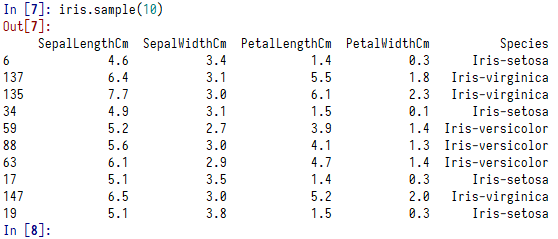
数据总共有五列,分别为:
epalLengthCm:花萼长度
SepalWidthCm:花萼宽度
PetalLengthCm:花瓣长度
PetalWidthCm:花瓣宽度
Species:分类( Iris-setosa、Iris-virginica、Iris-versicolour)
2 探索数据
如果你想知道Species分类有多少个分类,可以通过下面的代码查看,drop不会删除原来的数据集。
iris.drop_duplicates(['Species'])
如下:

接下来我们引入seaborn先探索一下数据。
import seaborn as sns
sns.regplot(x='PetalLengthCm',y='PetalWidthCm',data=iris)
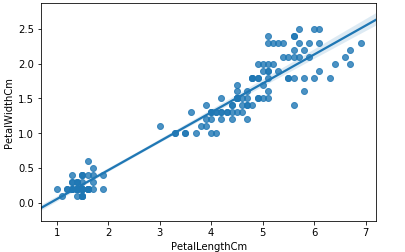
可以看到花瓣长度和花瓣宽度有很好的线性关系,并且seaborn已经自动把这两个变量通过线
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 653
653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









