






承接上篇。本篇主要利用逻辑回归算法模型,对即将流失用户进行预测,判断哪些客户会流失。
一、数据预处理
上一篇对基础的缺失值等已经进行过处理,这里主要是根据建模需求再进一步处理。
1.1特征编码
特征主要分为连续特征和离散特征,其中离散特征根据特征之间是否有大小关系又细分为两类。
- 连续特征:“tenure”、“MonthlyCharges”、“TotalCharges”,一般采用归一标准化方式处理。
- 离散特征:特征之间没有大小关系,如:PaymentMethod:[bank transfer,credit card,electronic check,mailed check],付费方式之间没有大小关系,一般采用one-hot编码。
- 离散特征:特征之间有大小关联,则采用数值映射。本数据集无此类特征。
import 1.1.1连续特征编码
对tenure(在网时长),MonthlyCharges(月费用),TotalCharges(总费用)三个特征进行标准化处理,使特征数据方差为1,均值为0,降低数值特征过大对预测结果的影响。
scaler 
#利用transform函数实现标准化
1.1.2离散特征编码
# 查看对象类型字段中存在的值

结合上篇文章4.2节服务属性,发现No internet service(无互联网服务)对客户流失率影响很小,和No基本一致,这里失用No代替No internet service。
df
# 使用Scikit-learn标签编码,将离散特征转换为整数编码

#查看转化后的数据
df.head()
1.2数据相关性分析
# CustomerID表示每个客户的标识,对后续建模不影响,这里选择删除CustomerID列
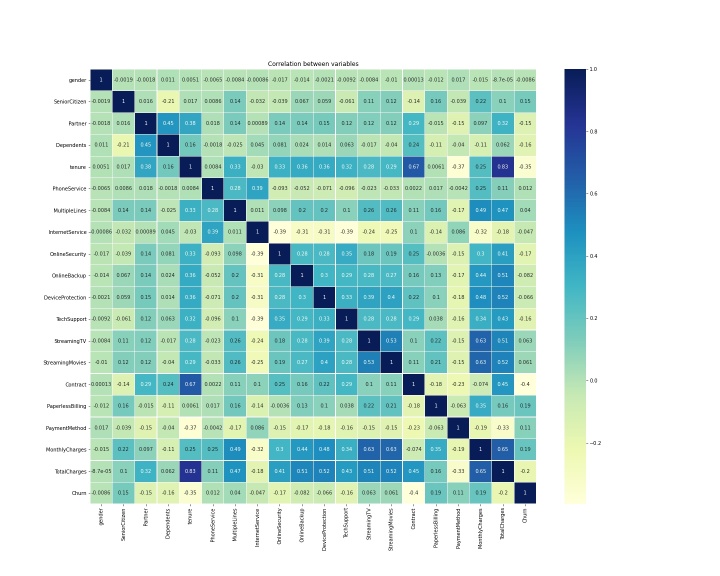
# 电信用户是否流失与各变量之间的相关性
plt.figure(figsize=(15,8))
df.corr()['Churn'].sort_values(ascending = False).plot(kind='bar')
plt.title("Correlations between Churn and variables")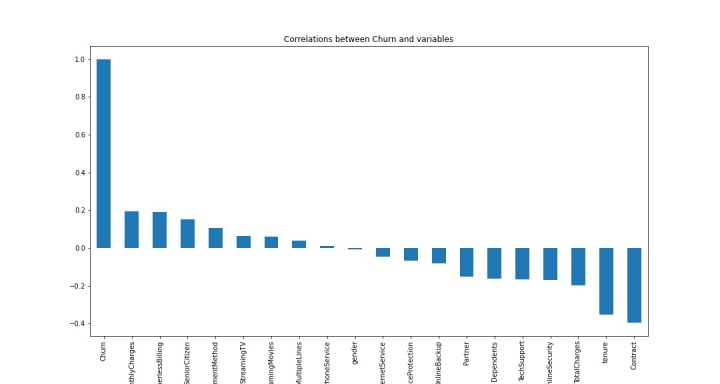
从上图可以直观看出,PhoneService 、gender这两个变量与churn目标变量相关性最弱。
1.3特征选取
特征值选取时,去除相关性较弱的PhoneService 、gender两个变量。这里目标变量是churn。
# 特征选择
dropFea = ['gender','PhoneService']
df.drop(dropFea, inplace=True, axis =1)
X=df.copy()
X.drop(['Churn'],axis=1, inplace=True)
y=df["Churn"]
#查看预处理后的数据
X.head()
二、构建模型
2.1样本不均衡处理
查看正常用户和流失用户数量分布
count_Churn 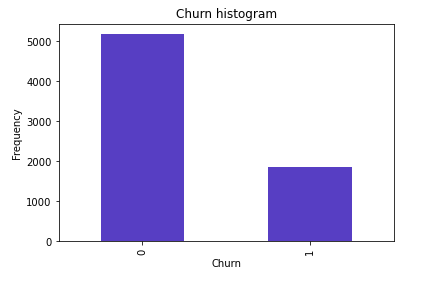
从图中看出,该样本中正常用户和流失用户数量分布不平衡,建模过程中容易忽略数量较少的流失客户,模型出现一边倒的情况,如果模型不重视异常数据,就有悖我们建模的初衷,常用的解决方案有下采样和上采样,我们这里利用下采样方案进行处理。
#下采样方案实现过程

下采样,简单的理解就是,两个唯一值,以数量最少值的个数为标准,随机对另外一个值选取相同个数,从而满足样本均衡化。本案例流失客户数为1869,从正常交易数据中同样选取1869个,各占比50%,总共3738个。
2.2模型交叉验证
我们将数据集分为训练集和测试集,以帮助完成模型测试工作。
from sklearn.model_selection import train_test_split
# 把整体数据集进行切分
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.3, random_state = 0)# test_size = 0.3, 表示30%的数据作为测试集合,即剩余70%的数据作为训练集;state=0在切分时进行数据重洗牌 的标识位。
print("原始训练集包含样本数量: ", len(X_train))
print("原始测试集包含样本数量: ", len(X_test))
print("原始样本总数: ", len(X_train)+len(X_test))
#对下采样数据样本进行切分
X_train_undersample, X_test_undersample, y_train_undersample, y_test_undersample = train_test_split(X_undersample ,y_undersample,test_size = 0.3,random_state = 0)
print("")
print("下采样训练集包含样本数量: ", len(X_train_undersample))
print("下采样测试集包含样本数量: ", len(X_test_undersample))
print("下采样样本总数:", len(X_train_undersample)+len(X_test_undersample))
2.3逻辑回归模型
2.3.1正则化惩罚
在机器学习任务中经常会遇到过拟合现象,最常见的情况就是随着模型复杂程度的提升,训练集效果越来越好,但是测试集效果反而越来越差。如果在训练集上得到的参数值忽高忽低,很可能导致过拟合,这时候就需要用到正则化惩罚,即惩罚数值较大的权重参数,降低它们对结果的影响。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,precision_recall_curve,auc,roc_auc_score,roc_curve,recall_score,classification_report
#Recall = TP/(TP+FN)
from sklearn.linear_model import LogisticRegression
# from sklearn.cross_validation import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
from sklearn.model_selection import cross_val_predict, KFold, cross_val_score
#print(help(KFold))
def printing_Kfold_scores(x_train_data,y_train_data):
#fold = KFold(len(y_train_data),5,shuffle=False)
fold = KFold(5,shuffle=False)
# 定义不同力度的正则化惩罚力度
c_param_range = [0.01,0.1,1,10,100]
# 展示结果用的表格
results_table = pd.DataFrame(index = range(len(c_param_range),2), columns = ['C_parameter','Mean recall score'])
results_table['C_parameter'] = c_param_range
# k-fold 表示K折的交叉验证,这里会得到两个索引集合: 训练集 = indices[0], 验证集 = indices[1]
j = 0
#循环遍历不同的参数
for c_param in c_param_range:
print('-------------------------------------------')
print('正则化惩罚力度: ', c_param)
print('-------------------------------------------')
print('')
recall_accs = []
#下面来分解执行交叉验证
#for iteration, indices in enumerate(fold,start=1):
for iteration, indices in enumerate(fold.split(x_train_data)):
# 指定算法模型,并且给定参数
#lr = LogisticRegression(C = c_param, penalty = 'l1')
lr = LogisticRegression(C = c_param, penalty = 'l1',solver='liblinear')
# 训练模型,注意索引不要给错,训练的时候一定传入的是训练集,所以X和Y的索引都是0
lr.fit(x_train_data.iloc[indices[0],:],y_train_data.iloc[indices[0],:].values.ravel())
# 建立好模型后,预测模型结果,这里用的就是验证集,索引为1
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1],:].values)
# 有了预测结果之后就可以来进行评估了,这里recall_score需要传入预测值和真实值。
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values,y_pred_undersample)
recall_accs.append(recall_acc)
print('Iteration ', iteration,': 召回率 = ', recall_acc)
# 当执行完所有的交叉验证后,计算平均结果
results_table.loc[j,'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('平均召回率 ', np.mean(recall_accs))
print('')
#找到最好的参数,Recall越高,效果越好
best_c = results_table.loc[results_table['Mean recall score'].astype('float32').idxmax()]['C_parameter']
# 打印最好的结果
print('*********************************************************************************')
print('效果最好的模型所选参数 = ', best_c)
print('*********************************************************************************')
return best_c
#交叉验证与不同参数结果
best_c = printing_Kfold_scores(X_train_undersample,y_train_undersample) 


2.3.2混淆矩阵
上面已经训练好模型,这里利用混淆矩阵进行可视化展示分析。
定义混淆矩阵的画法
def plot_confusion_matrix(cm, classes,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
绘制混淆矩阵
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j],
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')传入实际预测结果,调用之前的逻辑回归模型,得到测试结果,再把数据的真实标签值传进去即可:
import itertools
# lr = LogisticRegression(C = best_c, penalty = 'l1')
lr = LogisticRegression(C = best_c, penalty = 'l1', solver='liblinear')
lr.fit(X_train_undersample,y_train_undersample.values.ravel())
y_pred_undersample = lr.predict(X_test_undersample.values)
# 计算所需值
cnf_matrix = confusion_matrix(y_test_undersample,y_pred_undersample)
np.set_printoptions(precision=2)
print("召回率: ", cnf_matrix[1,1]/(cnf_matrix[1,0]+cnf_matrix[1,1]))
# 绘制
class_names = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix
, classes=class_names
, title='Confusion matrix')
plt.show()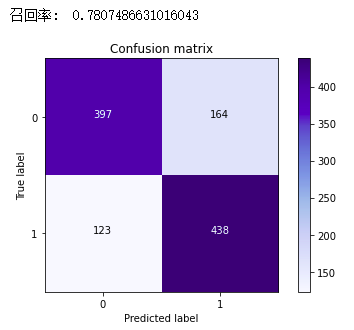
真实为1的召回率:表示在流失客户中有多少能预测到,覆盖面的大小。
用公式表达即:
召回率为 0.78,该分数还算理想。因为下采样时对原数据进行过处理,模型最终要回归实际,这里需要在整体数据集的测试集进行评估效果,使模型更加可信。
# lr = LogisticRegression(C = best_c, penalty = 'l1')
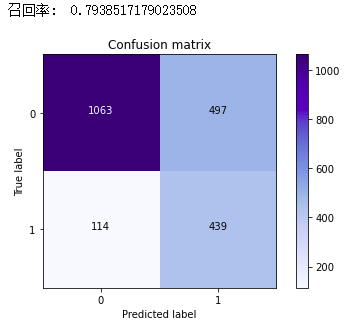
在原始数据进行测试,得到的召回率为0.79,两者结果比较接近。
2.3.3调整阈值
对于逻辑回归算法来说,我们还可以指定一个阈值,也就是说最终结果的概率是大于多少我们把它当成是正或者负样本。这里通过Sigmoid函数将得分值转换成概率值,默认情况下,模型都是以0.5为界限来划分类别:p>0.5为正例,p<0.5为负例。0.5是一个经验值,可以根据实际经验进行调整。我们指定0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,9个不同阈值,分别查看模型效果。
# 用之前最好的参数来进行建模

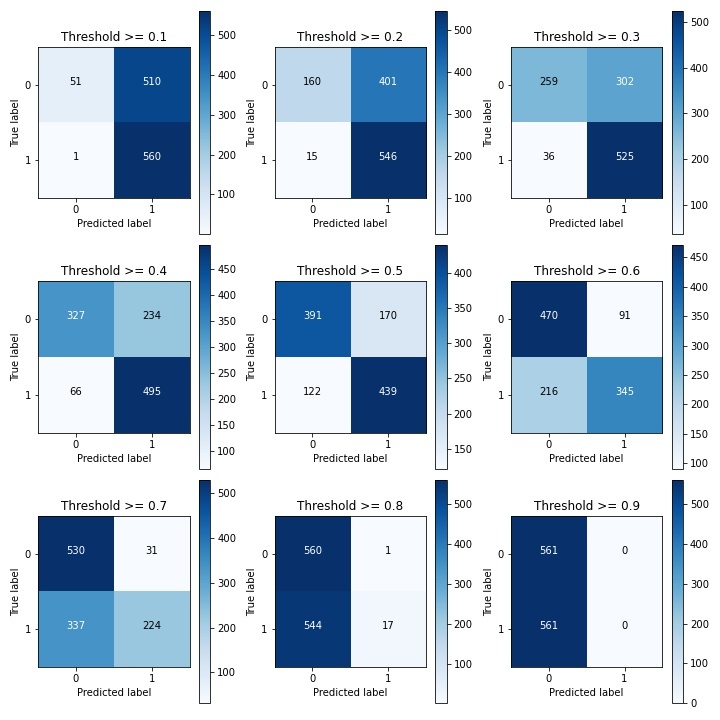
通过对比九个不同阈值发现,当阈值越小时,召回率越高,但“误杀率”也比较高,实际意思不大。随着阈值增大,召回率降低,也就是“漏检”的数量增多,但“误杀率”也会降低。
如当阈值等于0.9时,有560个流失客户被正确预测,有1个流失客户没有被预测到,但有510个正常用户被误认为是流失用户,召回率为0.99,但精确率只有0.54;当阈值等于0.5时,有439个流失客户被正确预测,有122个流失客户没有被预测到,有170个正常用户被误认为是流失用户,召回率为0.78,准确率为0.73,准确率有所上升。
在预测客户流失中,理想状态时,所有的流失用户都被预测到,这样我们就可以提前对这部分客户进行精细化运营,有效阻止客户流失,提高客户留存率;同时,也不存在正常用户被误判断为流失用户,减少运营成本,提高用户体验。但两者很难兼得,具体阈值调整需要结合实际业务,从实际业务出发,选择最优阈值。















 8316
8316











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









