





前言
使用过IK Analysis plugin的兄弟都知道,要扩展IK的词库,有两种方式:
- 通过ext_dict指定本地词库文件,例如:
ext.dic
- 通过remote_ext_dict指定远程词库请求地址,例如:
http://yoursite.com/getCustomDict
第一种方式扩展简单,但维护起来比较麻烦。假设ES集群包含多个节点,那么每个节点都要更新词库文件,而且要使其生效,还必须重启每个节点。
第二种方式扩展稍显麻烦,但能在不重启ES的情况下动态扩展词库。但要实现该功能,需要提供HTTP接口,而且还要按照约定在响应头中返回Last-Modified,ETag header。线程收到响应时会比较这两个header(详细操作可查看源码),以便实现增量更新.
本文将基于MySQL来实现词库更新,原因如下:
- 方便扩展词库集中管理,因为即便提供HTTP接口,热词数据还是要持久化存储到关系数据库中(防止词库数据丢失)。
- 增量更新更简单,首次更新热词时,先记录下最后一条单词的时间戳,下次更新就可以该时间戳为起点,实现后续的增量更新。
实现步骤
1.下载elasticsearch-analysis-ik-6.0.0源码,其下载地址为:
https://github.com/medcl/elasticsearch-analysis-ik/archive/v6.0.0.zip
2.解压并以Maven Project导入Eclipse,导入后如下所示:
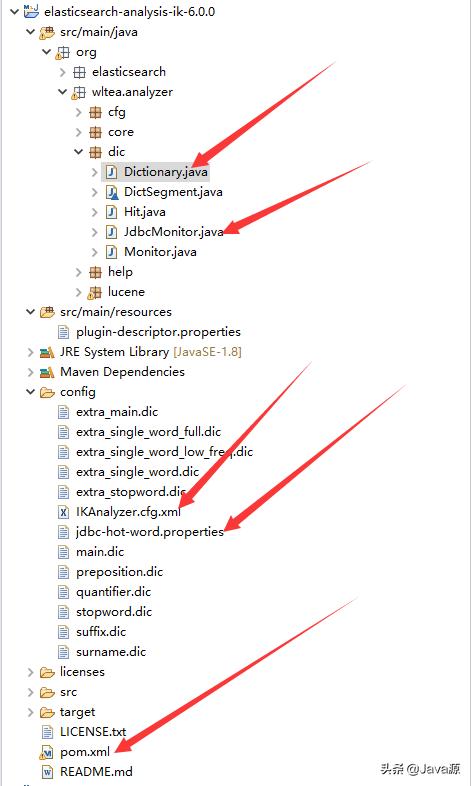
上面标有红色箭头的就是本次要修改或添加的内容。
3.修改pom.xml,在元素下增加mysql-jdbc驱动依赖:
mysqlmysql-connector-java5.1.474.在test数据库下创建hot_words表:
CREATE TABLE `hot_words` ( `word` varchar(32) NOT NULL, PRIMARY KEY (`word`)) ENGINE=InnoDB DEFAULT CHARSET=utf8;5.在工程的config目录下新增jdbc-hot-word.properties文件。其内容为:
#数据库URLjdbc.url=jdbc:mysql://192.168.88.130:3306/test#数据库用户名jdbc.user=test#数据库密码jdbc.password=test123456#加载词库的sqljdbc.reload.sql=select word from hot_words#重新加载词库的频率jdbc.reload.interval=56.编码
- 在org.wltea.analyzer.dic包下新增JdbcMonitor类,其代码为:
package org.wltea.analyzer.dic;import org.apache.logging.log4j.Logger;import org.elasticsearch.common.logging.ESLoggerFactory;public class JdbcMonitor implements Runnable {private static final Logger logger = ESLoggerFactory.getLogger(JdbcMonitor.class.getName()); public void run() {try {logger.info("JdbcMonitor...");Dictionary.getSingleton().reLoadMainDict();} catch (Exception e) {}}}- 修改org.wltea.analyzer.dic.Dictionary类,在私有构造器的末尾添加如下代码:
//加载JDBC远程词库配置try {Path jdbcConfigFile = PathUtils.get(getDictRoot(), PATH_JDBC_HOT_WORD);props.load(new FileInputStream(jdbcConfigFile.toFile()));logger.info("加载"+PATH_JDBC_HOT_WORD+"成功");} catch (Exception e) {logger.error("加载"+PATH_JDBC_HOT_WORD+"失败














 915
915











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









