





1 背景
前段时间,出现过这么一个问题:因为往es 写入数据的是不同的业务部门,而对这些数据进行分析的又是另一部门;写数据的分别在es里面建立了不同的索引表,但是查数据的需要对这些表一起查询进行。想进行查询,在代码里查询的可能是这样的 `GET index1,index2,.../_search`;这样写不会有什么功能性的问题,但是如果有新的索引表,查询方可能又要修改一下查询;虽然需要改动的地方不大,但总归是一件麻烦的事情从设计的角度来讲不具有可扩展性。了解ES 的同学可能已经想到了,索引别名;索引别名就像一个快捷方式或软连接,可以指向一个或多个索引,也可以给任何一个需要索引名的API来使用。2 索引别名的应用
2.1 降低代码与es索引表名的耦合
正如文章中背景部分所描述的问题,索引别名就可以很好的解决这个问题,且具有较高的扩展性,如图2-1使用索引别名与不使用索引别名的区别。
图2-1 使用索引别名和不使用索引别名的区别
从图2-1中可以看出,不使用别名客户端直接与真实索引耦合,而使用别名客户端直接与别名耦合;但是如果我们增加一个真实索引(同样需求数据处理的索引表),使用别名和不使用索引别名的区别如图2-2所示,不使用索引别名需要修改客户端程序,而使用索引别名只需要简单将新增的索引表关联到索引别名即可。
图2-2 不使用索引别名与使用时增加新索引表
2.2 零停机索引表拆分
因为日志具有实效性,且具有时序性,所以日志的索引表可以很方不便的按照天或者小时级别划分。对于一些业务比如oa和订单的es似乎就不是那么好划分索引表了,通常随着时间的推移索引表的数据量变得越来越大,索引越大shard越大会引起一些性能问题;熟悉es同学可能都知道es索引表创建成功之后,主分片数目是不可变的(因为数据的路由条件是依靠主分片数据做hash确定数据应该写到哪一个分片,如果想要改变主分片数目只能通过split和shrink索引表进行扩缩分片数目)。如果在机器固定的情况下,在一个index变的越来越大,单个shard也越来越大,查询和存储的速度也越来越慢,更重要的是一个index其实是有存储上限的(除非你设置足够多的shards和机器),如官方声明单个shard的文档数不能超过20亿(受限于Lucene index,每个shard是一个Lucene index),考虑到IO,针对index每个node的shards数最好不超过3个,那面对这样一个庞大的index,我们是采用更多的shards,还是更多的index我们如何选择,index的shards总量也不宜太多,更多的shards会带来更多的IO开销。为了节省机器,我们可能通常会选择拆分索引表,选择更多的index。
ES提供的Rollover Api + Index Template可以非常便捷和友好的实现index的拆分工作,把单个index docs数量控制在百亿内,也就是一个index默认5个shards左右即可,保证查询的即时响应。下面简单介绍一下Rollover Api 和 Index Template这两个东西,如何实现index的拆分。
1)template
ES可以为同一目的或同一类索引创建一个Index template,之后创建的索引只要符合匹配规则就会套用这个template,不必每次指定settings和mappings等属性。一个index可以被多个template匹配,那settings和mappings就是多个template合并后的结果,有冲突通过template的属性"order" : 0解决,order的值越大,则其优先级越高。
例如我们创建如下一个模板test-roller,所有真实索引表名称以test_起始,都会套用这个模板,除非有order更大的索引模板或者其创建时就已经指定这些别名、setting和mapping等。
#代码块2-1PUT _template/test-roller{ "order": 1, "index_patterns": [ "test_*" ], "aliases": { "test_search": {} }}2)rollerover
rollerover能够依据一定的规则索引进行切分,如索引大小、age和doc count等条件进行切分索引表。
示例:首先我们创建一个索引表,表名称xxx-000001;如下示例中我们给该索引起了两个索引别名一个用于写入,一个用于查询;
#代码块2-2PUT test_logs-000001{ "aliases": { "test_write": {}, "test_search": {} }}2)rollerover
rollerover能够依据一定的规则索引进行切分,如索引大小、age和doc count等条件进行切分索引表。
示例:首先我们创建一个索引表,表名称xxx-000001;如下示例中我们给该索引起了两个索引别名一个用于写入,一个用于查询;
#代码块2-2PUT test_logs-000001{ "aliases": { "test_write": {}, "test_search": {} }}#代码块2-3POST test_write/log{ "name":11}#代码块2-4POST /test_write/_rollover { "conditions": { "max_age": "1m", "max_docs": 1 }}
图2-3 rollerover reponse
当我们查看test_logs-000001,我们发现其只剩下查询别名test_search,如图2-4所示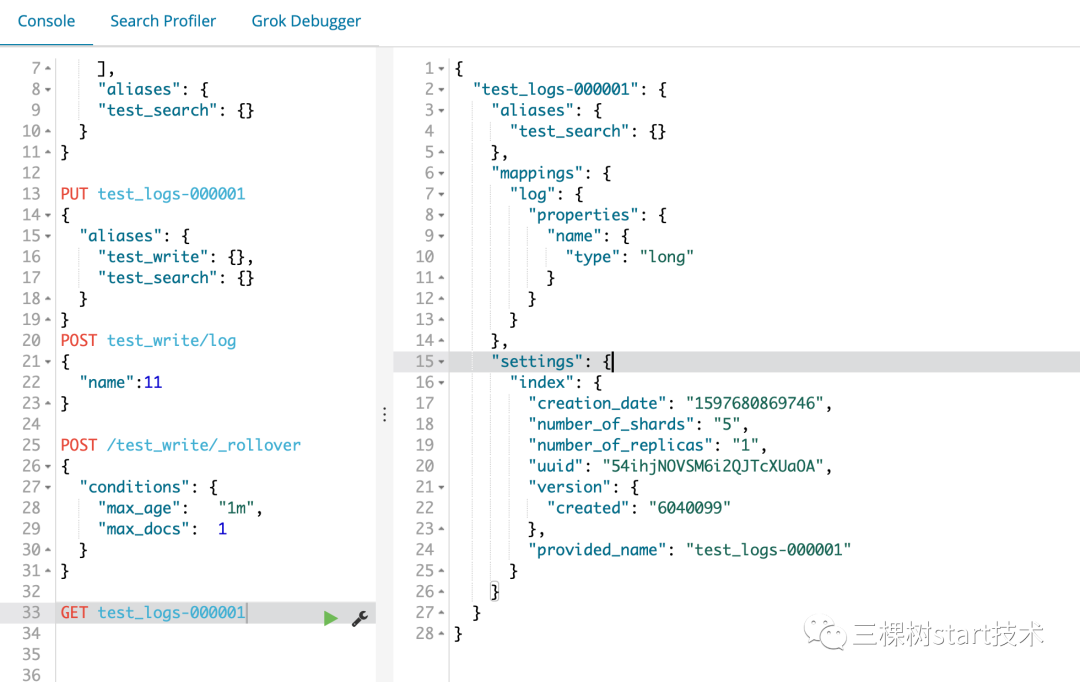
图 2-4 索引表test_logs-000001信息
而test_logs-000002索引关联两个别名,如图2-5所示,查询和写入别名。

图 2-5 索引表test_logs-000001信息
我们查看两个索引表的文档数,如图2-6所示

图 2-6 索引表test_logs-*索表的文档(1)
当我们再次执行代码块2-3时,我们发现数据已经写入真实索引est_logs-000002,再次查看两个索引表的文档数如图2-7所示。
图 2-7 索引表test_logs-*索表的文档(2)
当我们POST /test_write/_rollover时数据已经写入第二个索引表了,这样就完成索引表的切换(拆分);如果配上定时任务脚本或者按照自己的业务需求,去执行rollerover就更完美了。同时如果我们想要查询所有的索引表可以通过查询别名进行查询(示例中为test_search)。rollerover的精髓就是巧妙的运用了索引别名,只要保持一个别名始终只关联一个真实索引,那么就可以保证通过索引别名把数据写入对应的真实索引表中。rollerover除了可以使用索引名字为000001这种模式,还支持日期类型。使用日期类型的rollerover,索引表后缀必须加 '-数字`# 代码块2-5PUT logs-2020.08.18-1{ "aliases": { "logs_write": {} }}PUT logs_write/_doc/1{ "message": "a dummy log"}POST logs_write/_refresh当执行完代码2-5块在,再执行代码块2-6
#代码块2-6POST /logs_write/_rollover { "conditions": { "max_docs": "1" }}
图 2-8 索引表logs-2020.08.18当日rollerover
2.3 kibana
使用过kibana的同学可能都知到,在使用kibana的discovery时,需要创建index-pattern,即discovery中的下拉列表。起一个具有实际意义的索引别名,如代码块2-7所示。# 代码块2-7POST _aliases{ "actions": [ { "add": { "index": "basiclog-trace_10_655*", "alias": "某部门日志" } } ]}
图2-9 创建索引模式
完成索引别名的创建之后,便可以再kibana的搜索界面,选择别名,拿到自己关心的几个真实索引的数据;如图2-10,选择“某部门日志”。
图2-10 kibana搜索
2.4 零停机索引表合并
如果有部署过elasticsearch hot-stale架构集群或者一些指标型数据都有过一些这种经验,肯定会使用过索引合并。当从elasticsearch的hot域迁移到stale ,为了减小磁盘占用空间,以及fst占用的jvm堆内存空间,通常会把之前几个同类型较小的索引表合并成一个索引表,日志场景特别适合这种情况;时序型指标类型数据,一开始指标可能是按秒记的数据,但随着时间的推移,当时间过了一个月,那么可能秒级的数据对我们的参看意义就不大了,这是可以进行数据的上卷;比如将秒级别的数据放到改为天级别的数据,这个时候就需要用到索引合并。示例:借助索引别名在零停机的情况下完成索引表合并;假如我们有多个小时级别的索引表log-2020-08-18-00、log-2020-08-18-01等24时小时的索引表,他们都关联的索引别名为log-2020.08.18。#代码块2-8POST _reindex{ "source": { "index": "log-2020-08-18-*" }, "dest": { "index": "log-2020-08-18" }}#代码块2-9POST /_aliases{ "actions": [ { "remove": { "index": "log-2020-08-18-0*,log-2020-08-18-1*,log-2020-08-18-2*", "alias": "log-2020.08.18" }}, { "add": { "index": "log-2020-08-18", "alias": "log-2020.08.18" }} ]}3 索引别名的操作
3.1 创建索引别名
批量添加索引别名
#代码块3-1POST /_aliases{ "actions" : [ { "add" : { "index" : "test1", "alias" : "alias1" } } ]}给某个索引表添加索引别名
#代码块3-2PUT /{index}/_alias/{name}PUT /logs_201305/_alias/2013{index}支持*,_all,glob pattern以及用逗号分隔的多个索引表;除此之外,创建索引别名时还可以增加过滤和routing等
#代码块3-3PUT /users{ "mappings" : { "_doc" : { "properties" : { "user_id" : {"type" : "integer"} } } }}#代码块3-4//索引别名只会作用到满足条件的数据PUT /users/_alias/user_12{ "routing" : "12", "filter" : { "term" : { "user_id" : 12 } }}我们还可以在索引模版中指定索引别名,或者在创建索引时指定索引别名
#代码块3-5//索引模版中指定PUT _template/test-roller{ "order": 1, "index_patterns": [ "test_*" ], "aliases": { "test_search": {} }}#代码块3-6 //创建索引表时指定索引别名,如果索引模版中也指定了则取并集PUT test_logs-000002{ "aliases": { "test_search": {}, "test_write": {} }, "mappings": { "log": { "properties": { "name": { "type": "long" } } } }, "settings": { "index": { "number_of_shards": "5", "number_of_replicas": "1" } }}3.2 查看索引别名
查看所有别名test_search关联的真实索引
#//代码块3-7两者都可以GET /_alias/test_searchGET /_alias/test_sear*//返回内容如下{ "test_logs-000001": { "aliases": { "test_search": {} } }, "test_logs-000002": { "aliases": { "test_search": {} } }}查看真实索引关联的索引别名
/代码块3-8GET test_logs-000002/_alias//返回内容{ "test_logs-000002": { "aliases": { "test_search": {}, "test_write": {} } }}判断索引别名是否存在
//代码块3-9HEAD /_alias/2016HEAD /_alias/20*HEAD /logs_20162801/_alias/*3.3 删除索引别名
DELETE /{index}/_alias/{alias}
/代码块3-10DELETE /logs_20162801/_alias/current_day或者
//代码块3-11POST /_aliases{ "actions" : [ { "remove" : { "index" : "test1", "alias" : "alias1" } } ]}4 总结
索引别名是一个非常不错的功能,能够在零停机的情况下帮助我们解决很多生产性的问题,降低索引表于与代码的耦合,起一个好的索引别名能够帮助我们更好的理解业务等;索引别名带给我们极大的灵活性:
在运行的集群中可以无缝的从一个索引切换到另一个索引
给多个索引分组 (例如, last_three_months)
给索引的一个子集创建视图
索引别名的用法通常是索引别名+索引模版,索引别名+索引模版+rollerover和索引别名+reindex+索引模板等。
5 参考
[1]https://www.elastic.co/guide/en/elasticsearch/reference/6.4/indices-rollover-index.html
[2] https://www.elastic.co/guide/cn/elasticsearch/guide/current/index-aliases.html
[3]https://www.elastic.co/guide/en/elasticsearch/reference/6.4/indices-aliases.html
[4]https://www.elastic.co/guide/en/elasticsearch/reference/7.9/docs-reindex.html















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









