





来源 | AI实战派
作者 | AI实战派
在自然语言处理领域中,语料是非常关键的一个部分。然而,中文的自然语言处理领域在大的通用型语料上虽然不少,但在特定方向上的语料仍然匮乏。
在要进行拼音型文本纠错任务过程中,笔者发现这方面的语料着实少,因此在语料的获取和处理上花费较多时间,以下是笔者面对语料匮乏情况下的探索和总结。
语料的获取
语料获取分为两个部分:
一是搜索:查询并获取已有的特定方向的语料。
二是制造:自行制造出需要的语料。
语料搜索
首先我们自然要考虑能否找到已经标记好的公开语料。
没有查询到相应结果之后,开始寻找这方面的公开比赛,最好是去年或前年这类年份较近且比赛已经结束的,一来更可能可以获取完整语料,二来可以参考比赛结束后放出的优胜者的论文,而年份越近则参赛者更可能用上更先进的方法。
此外还可以参考这方面的论文,论文中会给出评测的方法和样例文本,根据文中出现的语料来源关键词再进行搜索。由此我搜索到几份台湾的拼音型质量较高的语料,分别是13-15年的Chinese Spelling Check Task的语料:
汇总链接:https://www.sigcall.org/data-sets.html
SIGHAN 2013 Bake-off: Chinese Spelling Check Task:http://ir.itc.ntnu.edu.tw/lre/sighan7csc.html
CLP 2014 Bake-off: Chinese Spelling Check Task:http://ir.itc.ntnu.edu.tw/lre/clp14csc.html
SIGHAN 2015 Bake-off: Chinese Spelling Check Task:http://ir.itc.ntnu.edu.tw/lre/sighan8csc.html
以下是语料的一个样例:

可以看出,这份语料的错误类型是拼音相近的词语,它不仅标出了错误词语,还给出了正确答案,由此还可以将错误检测模型扩展为纠正模型。
填写资料下载后可以看到,压缩包中除了训练、测试语料外还包含相似拼音字表和相近字形字表。
虽然语料质量较高,但还是有些缺点的:
- 首先自然是语料的规模不足,将三份语料汇总之后也不过得到3M左右的语料
- 其次是文本问题,可以看出语料使用的是繁体字,在建立面向简体字的模型的过程中,我们需要将其转换为简体字
- 第三是文化问题,文字虽然可以转换为简体字,但文本的组织结构、表述以及用词还是附带较浓的台湾气息,如“幼儿园”在文本中称为“幼稚园”,“什么”在文本中为“什幺”
在浏览完各类论文和语料库之后,就可以开始发散思维了。原本打算爬取小学生病句作为语料,然而点开几份病句题之后却发现,小学生的病句里就已经涉及到知识推理、指代不明等高难度问题了,由此不得让人感慨,我们还有很长的路要走。
可以直接用于训练的语料并不多,接下来该考虑语料制造了
语料制造
语料制造分为人工制作新语料和在现有语料上进行改造。
人工制作
人工制作新语料可以是完全人为构造新句子,当然还有方便得多的方法就是从已有的句子上挑选词语,选择相近音的字词进行替换。除了项目人员自行替换之外,也可外包出去花费金钱获取有一定数目和质量的人工语料。
此外,也可以从外国人学习中文的作文着手,已有的语法错误、词语错误语料有相当一部分是来自外国人的作文加上人工标记形成的,如北京语言大学的HSK动态作文语料库,但笔者并未发现有能够获取完整语料的地方。仅有官方提供的各种小规模查询方式。
改造语料
在网上各类公开语料库上得到大量中文通用语料并进行预处理之后,最简单的方法就是对于每个句子以一定的概率随机替换掉某个字或词(取决于模型是基于字还是基于词的,但一般来说基于字效果更好、字典更小、速度更快),替换的字或词的数目可以自行调整, 不同的概率对应不同的替换数目。优点是足够自动化、方便快速、语料数目大,缺点则是语料和将要纠错的句子的贴合度并不高。
在前面的方法之上为了更贴近待纠错句子,可以构造相近音的字表或词表,替换时查表随机替换。
以上就是语料获取方面的总结。在获取到Chinese Spelling Check Task的语料之后,还需要对其进行处理。
CSC语料处理
繁体转简体工具介绍及安装
为了建立面向简体中文的纠错模型,我们首先得将繁体语料转换成简体。在搜索python转换的工具包时,网上博客一水的推荐https://github.com/skydark/nstools/tree/master/zhtools的转换工具,然而在实际使用过后发现效果并不是很好,在剔除使用zhtools的文章之后,发现一个在github有3k stars的工具包opencc:https://github.com/BYVoid/OpenCC
使用python的可以 pip install opencc,但会报错并且需要各种设置。以下介绍一下Ubuntu下编译安装的方法,安装完成后直接可以在命令行中使用opencc而无需特定语言。
先找个空白文件夹安装需要的其它工具:git clone https://github.com/doxygen/doxygen.gitcd doxygenmkdir buildcd buildsudo apt-get install flexsudo apt-get install bisoncmake -G "Unix Makefiles" ..makesudo make install而后就可以开始安装opencc了:git clone git@github.com:BYVoid/OpenCC.gitcd OpenCCmakesudo make install安装完成后就可以在命令行中以:
opencc -c -i -o 的格式进行使用了,-c中支持的配置文件名可以在github上找到,若不加-o选项则会直接将转换后的结果显示出来。
进一步处理
将所有的Input txt 和Truth txt拷到一个文件夹后,使用
cat *Input* > input.txtcat *Truth* > truth.txtopencc -c tw2sp.json -i input.txt -o input.txtopencc -c tw2sp.json -i truth.txt -o truth.txt就可以得到转换后的文件了。
在进行简繁转换后,笔者发现其内部的英文和数字使用的是全角字符,然后在网上找段转换代码将文本转换成半角,之后再将数字转换成星号
在检测阶段,我们还不需要正确的词语,只需要错误词语的索引即可,在用正则表达式将truth中的汉字剔除后,就得到处理后的文本了:
文本

答案(只有索引)
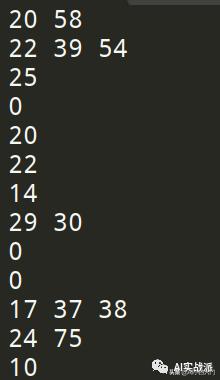
答案(带正确字)

值得注意的是,测试语料中错误字所使用的索引是从1开始的,并且0代表句子完全正确。
训练语料使用的sgml格式,可以用parser处理也可以直接暴力用正则表达式替换再用python细处理。
其它
上面的处理完成之后,已经可以投入训练了,但是也可以进一步进行处理:
- 长句切短句。将长句子按照逗号、句号、感叹号等切分成几个短句子,因为只是要检测简单的词语错误,因此不大需要考虑前后短句子的逻辑关系,将句子切开之后语料数目也同样增加了。
- 增加STA、END、UNK标签,自然语言处理领域中常常使用的方法,对于要输入LSTM的句子,开头加上STA标签,结尾加上END标签(也可以开头和结尾使用同一个标签),加上标签可以让模型知道是句子开头和结尾,由此可以加强判断第一个词和最后一个词正确与否的能力。而UNK则是用于标记词表外单词的标签,若单词频率太低则将其替换成UNK,减少词表大小。
- 保存字词和索引转换表,提前切分并替换成索引。将字词和索引的转换以固定文件保存下来,而后将语料预先转换成索引序列,可以省去大规模语料在内存中转换成索引的时间。要注意STA、END和UNK标签不要被单独切开了。
以上就是我在语料方面的探索和总结,希望能对读者有些许帮助。
The End















 3197
3197











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









