






标星★公众号 爱你们♥
作者:George Seif
编译:公众号翻译部
近期原创文章:
♥ 基于无监督学习的期权定价异常检测(代码+数据)
♥ 5种机器学习算法在预测股价的应用(代码+数据)
♥ 深入研读:利用Twitter情绪去预测股市
♥ Two Sigma用新闻来预测股价走势,带你吊打Kaggle
♥ 利用深度学习最新前沿预测股价走势
♥ 一位数据科学PhD眼中的算法交易
♥ 基于RNN和LSTM的股市预测方法
♥ 人工智能『AI』应用算法交易,7个必踩的坑!
♥ 神经网络在算法交易上的应用系列(一)
♥ 预测股市 | 如何避免p-Hacking,为什么你要看涨?
♥ 如何鉴别那些用深度学习预测股价的花哨模型?
♥ 优化强化学习Q-learning算法进行股市
全网进行中···
你为什么劝入/劝退Quant?
前言使用Pandas dataframe执行数千甚至数百万次计算仍然是一项挑战。你不能简单的将数据丢进去,编写Python for循环,然后希望在合理的时间内处理数据。
Pandas是为一次性处理整个行或列的矢量化操作而设计的,循环遍历每个单元格、行或列并不是它的设计用途。所以,在使用Pandas时,你应该考虑高度可并行化的矩阵运算。
本文将教你如何使用Pandas设计使用的方式,并根据矩阵运算进行思考。在此过程中,我们将向你展示一些实用的节省时间的技巧和窍门,这些技巧和技巧将使你的Pandas代码比那些可怕的Python for循环更快地运行!
数据准备在本文中,我们将使用经典的鸢尾花数据集。
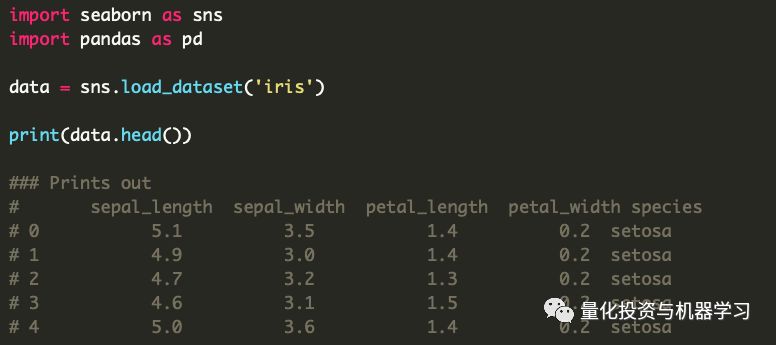
现在让我们建立一个标准线,用Python for循环来测量我们的速度。我们将通过循环遍历每一行来设置要在数据集上执行的计算,然后测量整个操作的速度。这将为我们提供一个基准,以了解我们的新优化对我们有多大帮助。
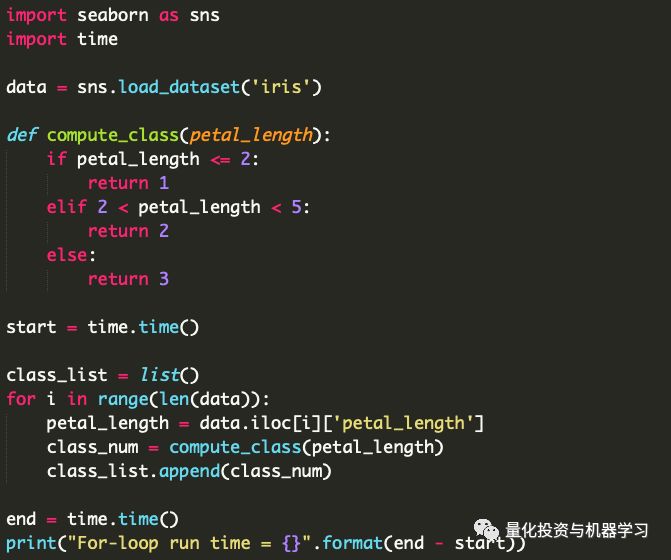
在上面的代码中,我们创建了一个基本函数,它使用If-Else语句根据花瓣的长度选择花的类。我们编写了一个for循环,通过循环dataframe对每一行应用函数,然后测量循环的总时间。
在i7-8700k计算机上,循环运行5次平均需要0.01345秒。
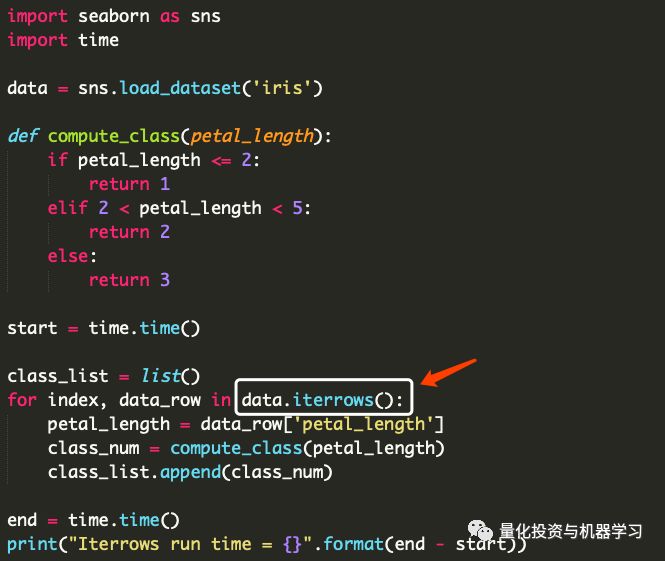
使用.iterrows()我们可以做的最简单但非常有价值的加速是使用Pandas的内置 .iterrows() 函数。
在上一节中编写for循环时,我们使用了 range() 函数。然而,当我们在Python中对大范围的值进行循环时,生成器往往要快得多。
Pandas的 .iterrows() 函数在内部实现了一个生成器函数,该函数将在每次迭代中生成一行Dataframe。更准确地说,.iterrows() 为DataFrame中的每一行生成(index, Series)的对(元组)。这实际上与在原始Python中使用 enumerate() 之类的东西是一样的,但运行速度要快得多!
生成器(Generators)
生成器函数允许你声明一个行为类似迭代器的函数,也就是说,它可以在for循环中使用。这大大简化了代码,并且比简单的for循环更节省内存。
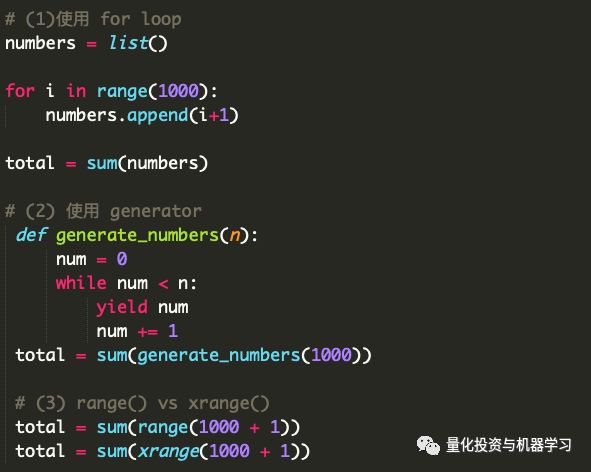
考虑这样一个例子,我们想把1到1000之间的所有数字加起来。下面代码的第一部分说明了如何使用for循环来实现这一点。
如果列表很小,比如长度为1000,那就很好了。当你想要处理一个庞大的列表时,比如10亿个浮点数,问题就出现了。使用for循环,在内存中创建了大量的内存huge列表,并不是每个人都有无限的RAM来存储这样的东西!Python中的range()函数也做同样的事情,它在内存中构建列表
代码的第(2)节演示了使用Python生成器对数字列表求和。生成器将创建元素并仅在需要时将它们存储在内存中。一次一个。这意味着,如果必须创建10亿个浮点数,那么只能一次将它们存储在内存中。Python中的xrange()函数使用生成器来构建列表。
也就是说,如果你想多次迭代列表并且它足够小以适应内存,那么使用for循环和range函数会更好。这是因为每次访问list值时,生成器和xrange都会重新生成它们,而range是一个静态列表,并且内存中已存在整数以便快速访问。
下面我们修改了代码,使用.iterrows()代替常规的for循环。在我上一节测试所用的同一台机器上,平均运行时间为0.005892秒,速度提高了2.28倍!
iterrows()函数极大地提高了速度,但我们还远远没有完成。请始终记住,当使用为向量操作设计的库时,可能有一种方法可以在完全没有for循环的情况下最高效地完成任务。
为我们提供此功能的Pandas功能是 .apply() 函数。apply()函数接受另一个函数作为输入,并沿着DataFrame的轴(行、列等)应用它。在传递函数的这种情况下,lambda通常可以方便地将所有内容打包在一起。
在下面的代码中,我们已经完全用.apply()和lambda函数替换了for循环,打包所需的计算。这段代码的平均运行时间是0.0020897秒,比原来的for循环快6.44倍。
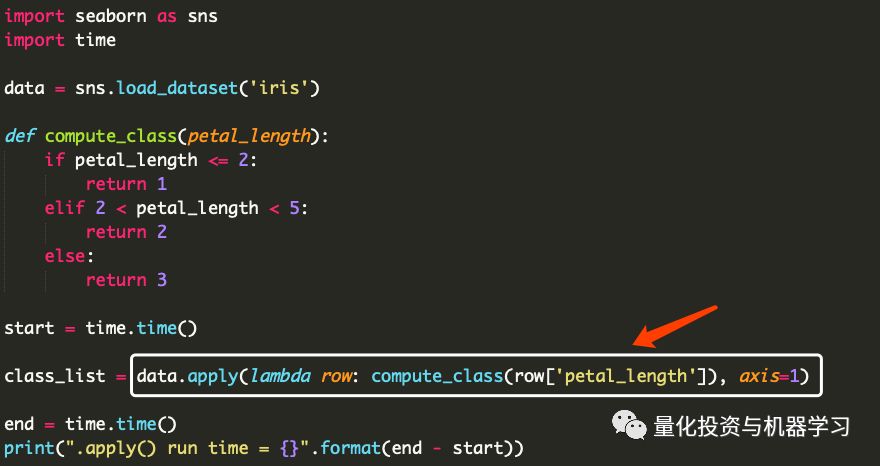
apply()之所以快得多,是因为它在内部尝试遍历Cython迭代器。如果你的函数针对Cython进行了优化,.apply()将使你的速度更快。额外的好处是,使用内置函数可以生成更干净、更可读的代码!
最后前面我们提到过,如果你正在使用一个为向量化操作设计的库,你应该总是在没有for循环的情况下寻找一种方法来进行任何计算。
类似地,以这种方式设计的许多库,包括Pandas,都将具有方便的内置函数,可以执行你正在寻找的精确计算,但速度更快。
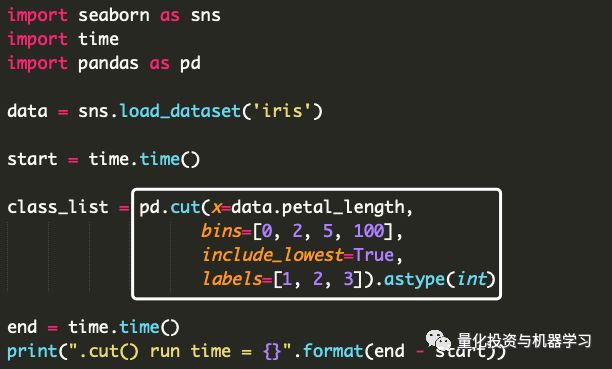
Pandas的 .cut() 函数将一组bin定义为输入,这些bin定义了If-Else的每个范围和一组标签。这与我们用 compute_class() 函数手动编写有完全相同的操作。
看下面的代码,看看.cut()是如何工作的。我们又一次得到了更干净、更可读的代码。最后,.cut()函数平均运行0.001423秒,比原来的for循环快了9.39倍!
全网进行中···
你为什么劝入/劝退Quant?
—End—
量化投资与机器学习微信公众号,是业内垂直于Quant、MFE、CST等专业的量化主流自媒体。公众号拥有来自公募、私募、券商、银行、海外等众多圈内10W+关注者。每日发布行业前沿研究成果和最新资讯。
















 933
933











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









