






Why DuckDB系列:
- Why DuckDB
- Python单机查询1.5亿行数据秒出
- DuckDB批量转CSV为Parquet
- DuckDB FDW 来了(敬请期待)
昨天介绍了Why DuckDB,今天就用它来体验在Python下1.5亿行数据的查询。
数据
最早知道 AirOnTime87to12 是学Sparklyr的时候看到一篇文章,使用Sparklyr导入30GB数据[1],具体文章内容,有兴趣的自己看,这里就不展开了。
AirOnTime87to12是一份航线准点率( On-time performance,OTP)的压缩包:
- 303 个CSV,大小30G
- 148617414 行数据,29个变量
- Zip压缩包4.2G
- 2013年8月由http://transtats.bts.gov提供下载
- 转为snappy压缩的parquet 2.4G
硬件环境
- OS:MacOS 10.15.6 (19G2021)
- CPU:2.8 GHz Quad-Core Intel Core i7
- MEM:16 GB 1600 MHz DDR3
- HD:1T SSD
Python
- Python 3.7
- Jupyter-Lab
- DuckDB GitHub Master
$ git clone https://github.com/cwida/duckdb
$ cd duckdb
$ BUILD_PYTHON=1 make注:通过pip install duckdb 或者conda install python-duckdb 安装的版本暂时不支持通配符。
体验
- 创建duckdb链接,本例使用内存数据库
%load_ext autotime
import duckdb
db = duckdb.connect(":memory:")
duck_cursor = db.cursor()
def fetchdf(sql):
return duck_cursor.execute(sql).fetchdf();
- 创建airontime视图
sql = """create or replace view airontime as
select *
from parquet_scan('/data/AirOnTime/*.parquet');
"""
fetchdf(sql)- 先看看多少行
fetchdf("select count(*) from airontime")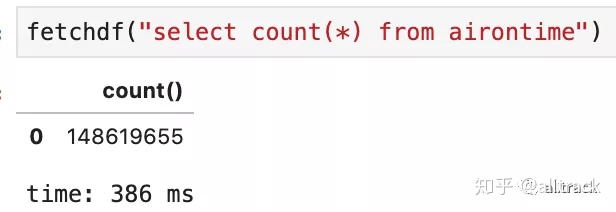
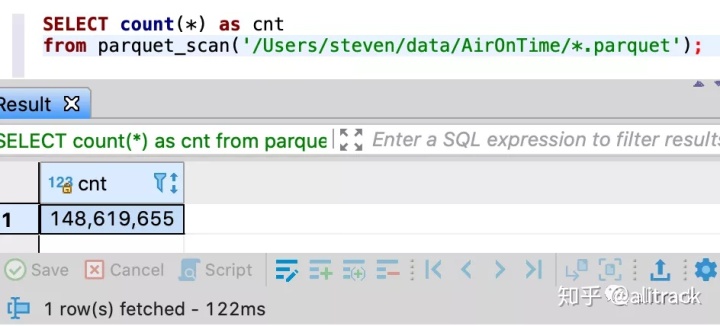
- 对比下PySpark 3.0(500多ms)

- 体验下聚合查询(如果没有oder by, 在2s以内)
sql ='''
select "YEAR" , count(*)
from airontime ap
group by 1
order by 1;
'''
fetchdf(sql)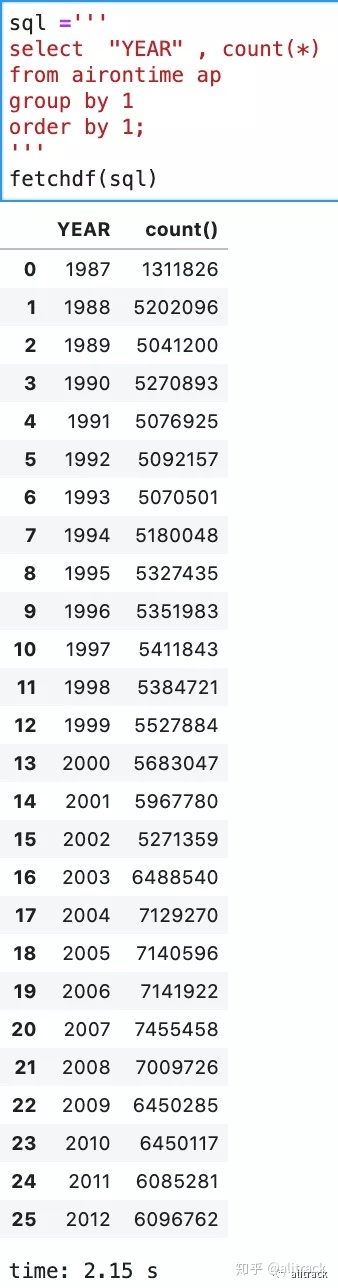
- 读取csv
支持csv和csv.gz, UTF8编码,分隔符,换行符,是否有header,以及变量数据类型都可以尝试让duckdb自己来判断
sql ="""
select * f
rom read_csv_auto('/Users/steven/data/iris.csv')
"""
iris=fetchdf(sql)
type(iris) # pandas.core.frame.DataFrame
iris.dtypes
- 通过SQL语句访问Pandas DataFrame
#把DataFrame iris 映射为虚拟表iris,然后使用SQL来查询
duckdb.query(iris,'iris',
"select * from iris limit 5").fetch_df()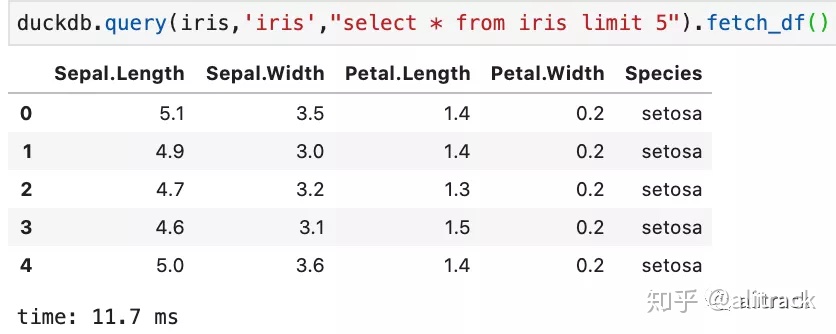
- 查询结果 导出为Parquet 或者csv
duckdb.query(iris,'iris',
"""copy(select * from iris limit 5)
to 'iris_5.parquet' (format 'parquet')""").fetch_df()
duckdb.query(iris,'iris',
"""copy(select * from iris limit 5)
to 'iris_5.csv' (format 'csv')""").fetch_df()
- 关闭连接
duck_cursor.close()
db.close()其它更多惊艳功能等待你来挖掘,有兴趣的可以安装DuckDB体验起来。
参考
- https://www.brodrigues.co/blog/2018-02-16-importing_30gb_of_data/
- https://docs.microsoft.com/en-us/machine-learning-server/r-reference/revoscaler/airontime87to12
- https://github.com/cwida/duckdb















 859
859











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









