





本文精心挑选了许多优秀的Unicode小技巧、软件包和资源。

译者 | 弯月,责编 | 郭芮
出品 | CSDN(ID:CSDNnews)
以下为译文:
Unicode非常了不起!在Unicode出现之前,国际交流是一团糟——每个人都在ASCII码表的后半部分区域(称为“代码页”)定义了自己的扩展和字符集,从而导致各种冲突。想想就知道,德国人要与韩国人只使用127个字符组成的代码页进行交流会有多么困难。
——幸亏有了Unicode标准和统一的交流规范。
Unicode 8.0根据129多种书写体系,标准化了超过120,000个字符,其中包括现代字符、古代字符,甚至还包括人类尚未解密的文字。Unicode能处理从左到右和从右到左两种书写方式,支持组合标记,还支持多种文化、政治、宗教方面的字符,甚至还有表情符号。
Unicode太了不起了,我们对它的崇拜犹如滔滔江水绵绵不绝。

Unicode的背景
Unicode标准支持什么字符?
Unicode标准定义了今日所有主流的书写语言中用到的字符。Unicode支持的书写体系包括欧洲的语系、中东的从右至左书写的语系,以及亚洲的多种语系。
Unicode标准还包含了标点符号、声调符号、数学符号、科技符号、箭头、各种图形符号、表情符号,等等。Unicode为声调符号(用来改变其他字符的符号,如波浪线~)单独提供了代码,这些代码可以与基础字符组合使用,来表示有声调的字符(如ñ)。Unicode标准9.0版总共提供了128,172个字符的代码,其中包括了全世界的字符、图形和符号。
绝大部分的常用字符都能映射到最前面的64K个代码点上,这一区域叫做基本多文种平面(basic multilingual plane,简称为BMP)。还有十六个补充平面用来编码其他字符,目前尚有850,000个未使用的代码点。人们还在考虑在以后的版本中添加更多的字符。
Unicode标准还保留了一些代码点供私人使用。供应商或最终用户可以在内部利用这些代码点表示他们自己的字符和符号,或者通过特殊的字体来使用。BMP上有6,400个私有代码点,如果不够的话,补充平面上还有131,068个私有代码点可供使用。
Unicode字符编码
字符编码标准不仅定义了每个字符的唯一标识(即字符的数字值,或者叫做代码点),也定义了怎样用比特来表示这个值。
Unicode标准定义了三种编码形式,允许同一个数据以一字节、两字节或四字节的格式来传输(即每个代码单元可以是8比特、16比特或32比特)。同一个字符集可以使用所有三种编码形式,它们之间可以互相转换,而不会丢失数据。Unicode联盟建议根据实际需要,选择任何一种方便的编码方式来实现Unicode标准。
UTF-8在HTML和类似协议上非常常用。UTF-8使用变长编码。它的优点是,对应于ASCII字符集的那些Unicode字符的字节值与它们在ASCII中的值完全相同,因此使用UTF-8编码的Unicode字符可以在绝大多数已有软件上使用,无需对软件做出任何修改。
UTF-16在许多需要平衡性能和存储效率的环境中非常常用。它足够紧凑,所有常用的字符都可以用一个16比特的代码单元来表示,其他字符可以使用一对16比特代码单元来表示。
UTF-32在无需顾虑内存空间的情况下使用,它是定长编码,每个字符只有一个代码单元。每个Unicode字符编码成一个32比特代码单元。
在所有三种编码中,每个字符最多需要4个字节(32比特)表示。
数字问题
Unicode字符集被分成17个核心段,称为“平面”,每个平面又被分成若干区块。每个平面的空间足够容纳65,536(216)个代码点,因此总共有1,114,112个代码点。还有两个“私有区域”平面(#16和#17),可以按照使用者的意愿定义。这两个私有平面共包含131,072个代码点。
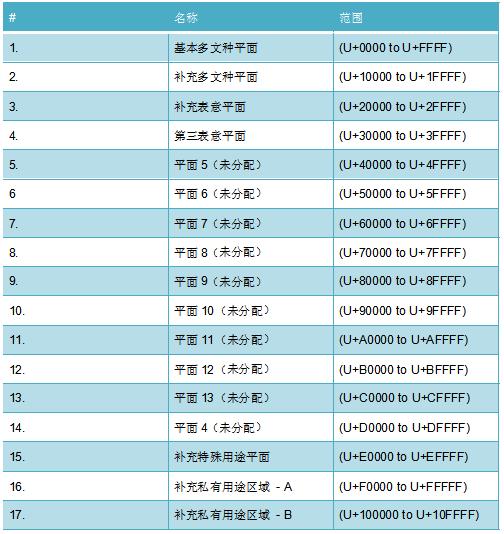
第一个平面叫做“基本多文种平面”,或者称为BMP。它包含代码点U+0000到U+FFFF,这个范围内包含了绝大部分常用字符。另外16个平面(U+010000到U+10FFFF)称为补充平面。
UTF-16代理对
“BMP之外的字符,例如U+1D306 tetragram for centre (),在UTF-16编码中只能编码成两个16比特代码单元:0xD834 0xDF06。这种情况称为代理对(surrogate pair)。注意代理对只表示一个字符。
“代理对的第一个字符永远在0xD800到0xDBFF的范围内,称为高位代理,或者叫起始字节代理。代理对的第二个代码单元永远在0xDC00到0xDFFF的范围内,称为低位代理,或者叫末端代理。”
——Mathias Bynens
“代理对:一种表示方式,用于表示由两个16比特代码单元组成的单个抽象字符,其中第一个值称为高位代理代码单元,第二个值称为低位代理单位。代理对仅在UTF-16中使用。”
——Unicode 8.0 第3.9章,代理对(参见Unicode编码)
计算代理对
代理字符 Pile of Poo (U+1F4A9) 在UTF-16中必须编码成代理对,即两个代理。要将代码点转换成代理对,可以使用以下算法(用JavaScript编写)。注意我们使用的是十六进制表示。
var High_Surrogate = function(Code_Point){ return Math.floor((Code_Point - 0x10000) / 0x400) + 0xD800 };
var Low_Surrogate = function(Code_Point){ return (Code_Point - 0x10000) % 0x400 + 0xDC00 };
// Reverses The Conversion
var Code_Point = function(High_Surrogate, Low_Surrogate){
return (High_Surrogate - 0xD800) * 0x400 + Low_Surrogate - 0xDC00 + 0x10000;
}; > var codepoint = 0x1F4A9; // 0x1F4A9 == 128169
> High_Surrogate(codepoint).toString(16)
"d83d" // 0xD83D == 55357
> Low_Surrogate(codepoint).toString(16)
"dca9" // 0xDCA9 == 56489
> String.fromCharCode( High_Surrogate(codepoint) , Low_Surrogate(codepoint) );
""
> String.fromCodePoint(0x1F4A9)
""
> '��'
""组合和解组合
Unicode包括了一种修改字符形状的机制,大幅扩展了Unicode支持的字符量。使用声调符号进行组合就是其中一种方式。声调符号写在主字符的后面。多个声调符号可以叠在同一个字符上。对于绝大部分常用的字母声调组合,Unicode还包括了预先组合好的版本。
特定的字符序列也可以用单个字符表示,称为“预组合字符”(或者叫组合字符,可以解组合的字符)。例如,字符“ü”可以编码成单个代码单元U+00FC “ü”,也可以编码成基本字符U+0075 “u”后接无空白字符U+0308 “¨”。Unicode标准中设置的预组合字符是为了兼容Latin 1等标准,后者包含了许多预组合字符,如“ü”和“ñ”。
预组合字符可以进行接组合,以保持一致性,或用于分析。例如,需要将一组名称转换为英文字母时,可以将字符“ü”解组合为“u”后接非空白字符“¨”。解组合后的结果很容易处理,因为该组合字符可以处理成“u”后接一个修饰字符。这样很容易进行按字母顺序排序等,因为修饰字符不会影响字母顺序。Unicode标准为所有预组合字符定义了解组合方式(https://unicode.org/versions/Unicode8.0.0/ch03.pdf#page=44)。它还定义了正规化的方式,以便为字符提供唯一的表示方法。
Unicode之谜
来自Mark Davis的《Unicode之谜》幻灯片(https://macchiato.com/slides/UnicodeMyths.pdf)。
Unicode只不过是16比特编码。一些人误认为Unicode只不过是16比特编码,每个字符占用16比特,因此一共有65,536个可能的字符。实际上这是不正确的。这样是关于Unicode的最大误解,所以也难怪一些人会这么想。
任何未分配的代码点都可以用于内部用途?错。最终,那些未分配的地方都会被某个字符使用。你应该使用私有用途代码点,或非字符代码点。
每个Unicode代码点都表示一个字符?错。有许多非字符代码点(FFFE,FFFF,1FFFE,……)还有许多代理代码点、私有代码点和未分配的代码点,还有控制和格式“字符(RLM,ZWNJ,……)
字符映射是一对一的?错。映射关系也可能是:
一对多:(ß → SS )
上下文相关:(…Σ ↔ …ς 和 …ΣΤ… ↔ …στ… )
语言相关:( I ↔ ı 和 İ ↔ i )
实用Unicode编码手册
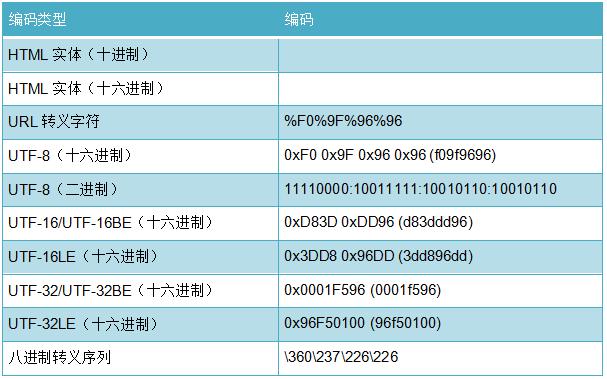
编码类型编码
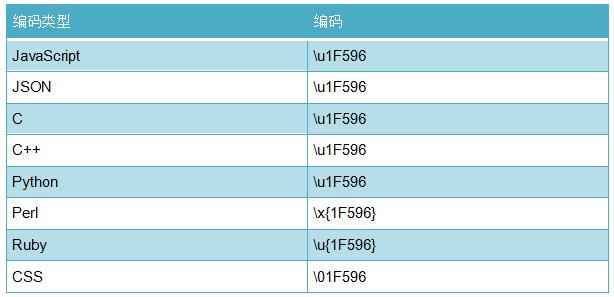

神奇的字符列表

特殊字符
详情可以参照Unicode联盟发布的《通用标点符号表》(https://www.unicode.org/charts/PDF/U2000.pdf)。
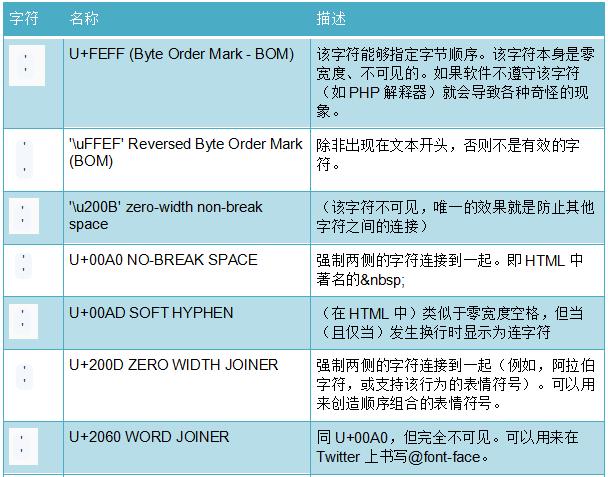
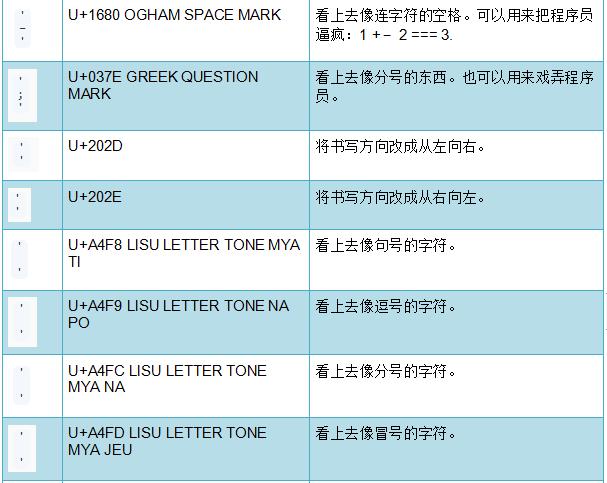
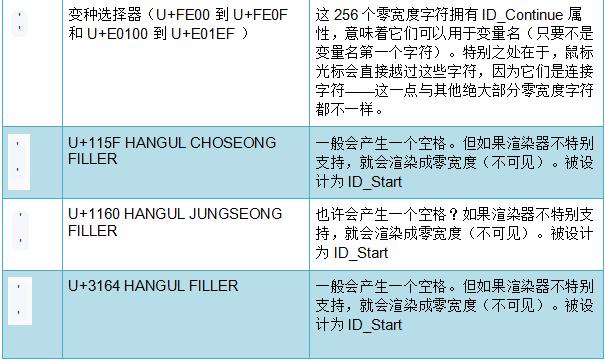
等等,你说什么?
变量标识符可以包含空白!
U+3164 HANGUL FILLER 字符显示为占据空间的空白字符。如果渲染器不支持,则会渲染成完全不可见(也不会占据任何空间,即“零宽度”)。这就是说,永远不会看到丑陋的字符替代符号。
我不知道为什么U+3164被设计成这种行为。有意思的是,U+3164是在Unicode 1.1版本(1993年)加入的,所以联盟一定是花了很多时间思考它。下面是几个例子:
> var ᅟ = 'foo';
undefined
> ᅟ
'foo'
> var ㅤ= alert;
undefined
> var foo = 'bar'
undefined
> if ( foo ===ㅤ`baz` ){} // alert
undefined
> var varㅤfooㅤu{A60C}ㅤπ = 'bar';
undefined
> varㅤfooㅤꘌㅤπ
'bar'
注意:我在Ubuntu和OSX下测试了下述程序的渲染结果:Node,PHP,Ruby,Python3.5,Scala,Vim,Cat,Chrome+GitHub gist。Atom是唯一无法正确渲染,将其显示成空方块的程序。我还没有测试Emacs和Sublime。据我的理解,Unicode联盟不会改变或重命名字符或代码点,但有可能会改变字符属性,如ID_Start或ID_Continue等。
修饰符
零宽度连接符(ZWJ)是个不可打印字符,用于某些复杂语系的计算机排版系统中,如阿拉伯语系、印度语系等。将ZWJ放在两个本来不会连接的字符之间,将会导致它们以连接的形式打印。
零宽度不连接符(ZWNJ)是个不可打印字符,那些使用连接的书写系统的计算机化。将ZWNJ放在两个本来会连接在一起的字符之间,会导致它们以本来的形式打印。空格字符也有同样的效果,但ZWNJ的作用是它能保证输出的两个字符尽可能靠近,或者连接一个词及其语素。
> 'a'
"a"
> 'au{0308}'
"ä"
> 'au{20DE}u{0308}'
"a⃞̈"
> 'au{20DE}u{0308}u{20DD}'
"a⃞̈⃝"
// Modifying Invisible Characters
> 'u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}'
" "
> 'u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}u{200E}'.length
10大写变换冲突
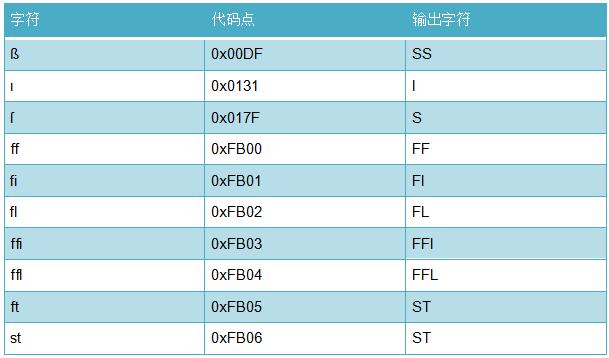
小写变换冲突

奇怪现象和排查方法
字符串长度通常由统计代码点的个数来计算。这就是说,代理对会被统计成两个字符。多个声调符号会叠放在同一个字符上,例如a + ̈ == ̈a,从而增加长度,但它们只会产生一个字符。
类似地,字符串翻转通常非常困难。同样,代理对和带有声调符号的字符必须作为整体进行翻转。ES Reverser提供了一个非常好的解决方法。
字符映射是一对一的?错。映射关系也可能是:
一对多:(ß → SS )
上下文相关:(…Σ ↔ …ς 和 …ΣΤ… ↔ …στ… )
语言相关:( I ↔ ı 和 İ ↔ i )
一对多映射
绝大多数字符,在大写的时候表示一对多关系;另一些字符小写的时候表示一对多关系。

优秀的软件包和库
PhantomScript::ghost: :flashlight: 不可见的JavaScript代码执行和社会工程工具。
ESReverser:用JavaScript编写的支持Unicode的字符串翻转。
mimic:Unicode的恶作剧。
python-ftfy:输入Unicode文本,输出更一致、更不容易出现显示错误的表现形式。
vim-troll-stopper:防止Unicode的捣乱字符搞乱你的代码。

表情符号
Unicode联盟的表情符号表(https://www.unicode.org/emoji/charts/full-emoji-list.html)
Emojipedia(https://emojipedia.org/):关于特定表情符号的信息,新闻博客。
World Translation Foundation(https://www.emojifoundation.com/):宣传、探索,还可以将文本翻译成用表情符号表示的形式。
Can I Emoji? (https://caniemoji.com/android-2/):显示当前iOS、Android和Windows对于表情符号的原生支持情况。
怎样注册一个表情符号URL(https://www.name.com/blog/how-tos/2015/12/want-an-emoji-url-this-is-how-you-register-one/)
多样性
Unicode联盟在支持人类的多样性和多元文化方面做出了很多努力。这里是联盟提供的多样性报告(https://unicode.org/reports/tr51/#Diversity)。
现在表情符号已经支持混合型别,比如同性家庭、握手、接吻等。真正轰动的是表情符号组合序列。基本上来说:
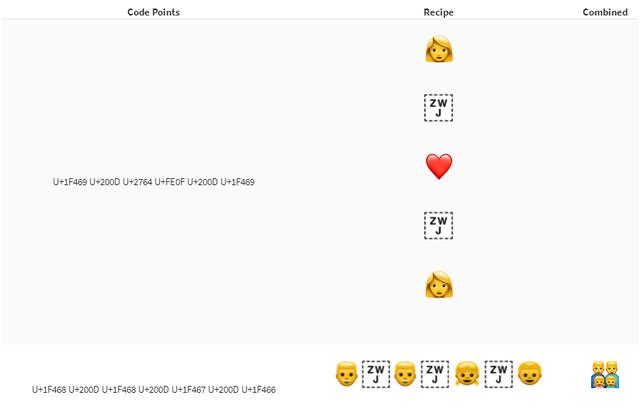
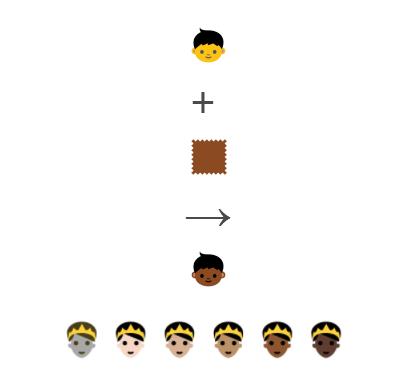
此外,表情符号现在还支持肤色修饰字符了。
“有五个符号修饰字符可以为Unicode 8.0版(2015年中期)中发布的人类的表情符号提供一系列的肤色。这些字符基于Fitzpatrick度量(皮肤学上的著名标准,网上也有许多例子,比如FitzpatrickSkinType.pdf)定义的六种肤色。不同的实现的精确颜色可能不同。”
——Unicode联盟的多样性报告
只需要在所需的表情符号后面接上肤色修饰字符 u{1F466}u{1F3FE} 即可。

有创意的变量名和方法名
示例采用JavaScript(ES6)编写。
一般而言,带有ID_START属性的字符可以用在变量名开头,而带有ID_CONTINUE属性的字符可以用在变量名中除了首字符之外的其他位置。
function rand(μ,σ){ ... };
String.prototype.reverseⵑ = function{..};
Number.prototype.isTrueɁ = function{..};
var WhatDoesThisDoɁɁɁɁ = 42
下面是Mathias Bynes(https://mathiasbynens.be/notes/javascript-identifiers#examples)提供的一些极富创意的变量名:
// How convenient!
var π = Math.PI;
// Sometimes, you just have to use the Bad Parts of JavaScript:
var ಠ_ಠ = eval;
// Code, Y U NO WORK?!
var ლ_ಠ益ಠ_ლ = 42;
// How about a JavaScript library for functional programming?
var λ = function {};
// Obfuscate boring variable names for great justice
var lolwa = 'heh';
// …or just make up random ones
var Ꙭൽↈⴱ = 'huh';
// While perfectly valid, this doesn’t work in most browsers:
var foobar = 42;
// This is *not* a bitwise left shift (`<var 〱〱 = 2;
// This is, though:
〱〱 << 〱〱; // 8
// Give yourself a discount:
var price_9̶9̶_89 = 'cheap';
// Fun with Roman numerals
var Ⅳ = 4;
var Ⅴ = 5;
Ⅳ + Ⅴ; // 9
// Cthulhu was here
var Hͫ̆̒̐ͣ̊̄ͯ͗͏̵̗̻̰̠̬͝ͅE̴̷̬͎̱̘͇͍̾ͦ͊͒͊̓̓̐_̫̠̱̩̭̤͈̑̎̋ͮͩ̒͑̾͋͘Ç̳͕̯̭̱̲̣̠̜͋̍O̴̦̗̯̹̼ͭ̐ͨ̊̈͘͠M̶̝̠̭̭̤̻͓͑̓̊ͣͤ̎͟͠E̢̞̮̹͍̞̳̣ͣͪ͐̈T̡̯̳̭̜̠͕͌̈́̽̿ͤ̿̅̑Ḧ̱̱̺̰̳̹̘̰́̏ͪ̂̽͂̀͠ = 'Zalgo';
下面是David Walsh提供的一些Unicode CSS类名(https://davidwalsh.name/unicode-css-classes):
You do not have access to this page.
Your changes have been saved successfully!
.ಠ_ಠ {
border: 1px solid #f00;
}
.❤ {
background: lightgreen;
}
递归的HTML标签重命名脚本
如果你想把所有HTML标签重命名,使之看上去像什么都没有,那么可以使用以下的脚本。
但要注意,HTML并不会支持所有的Unicode字符。
// U+1160 HANGUL JUNGSEONG FILLER
transformAllTags('ᅠ');
// An actual HTML element node designed to look like a comment node, using the U+01C3 LATIN LETTER RETROFLEX CLICK
// ǃ-->
transformAllTags('ǃ--');
// or even transformAllTags('u{1160}u{20dd}');
// and for a bonus, all existing tag names will have each character ensquared. h⃞t⃞m⃞l⃞
transformAllTags;
function transformAllTags(newName){
// querySelectorAll doesn't actually return an array.
Array.from(document.querySelectorAll('*'))
.forEach(function(x){
transformTag(x, newName);
});
}
functionwonky(str){
return str.split('').join('u{20de}') + 'u{20de}';
}
functiontransformTag(tagIdOrElem, tagType){
var elem = (tagIdOrElem instanceof HTMLElement) ? tagIdOrElem : document.getElementById(tagIdOrElem);
if(!elem || !(elem instanceof HTMLElement))return;
var children = elem.childNodes;
var parent = elem.parentNode;
var newNode = document.createElement(tagType||wonky(elem.tagName));
for(var a=0;anewNode.setAttribute(elem.attributes[a].nodeName, elem.attributes[a].value);
}
for(var i= 0,clen=children.length;inewNode.appendChild(children[0]); //0...always point to the first non-moved element
}
newNode.style.cssText = elem.style.cssText;
parent.replaceChild(newNode,elem);
}下面是确定能够支持的字符:
function testBegin(str){
try{
eval(`document.createElement( '${str}' );`)
return true;
}
catch(e){ return false; }
}
function testContinue(str){
try{
eval(`document.createElement( 'a${str}' );`)
return true;
}
catch(e){ return false; }
}下面是一些基本的结果:
// Test if dashes can start an HTML Tag
> testBegin('-')
< false
> testContinue('-')
< true
> testBegin('ᅠ-') // Prepend dash with U+1160 HANGUL JUNGSEONG FILLER
< true

Unicode字体
单一的TrueType / OpenType 字体格式无法支持所有UTF-8字符,因为字体文件有最大65535个字形的限制。UTF-8的字形超过了110万,因此你需要一个font-family才能覆盖所有字体。
https://en.wikipedia.org/wiki/Unicode_font#List_of_Unicode_fonts
https://www.unifont.org/fontguide/

Unicode标准的原则
Unicode标准设定了下述基本原则:
通用原则——曾经出现过的一切书写系统都应该在标准中体现。
逻辑顺序——在双向文本中,字符以逻辑顺序存储,而不是表现顺序存储。
效率——文档必须是高效的、完整的。
统一——不同文化或语言使用同一个字符时,应该仅存储一次。
记录字符而不是字形——应当对字符进行编码,而不是字形。字形就是字符的实际图形表示。
动态组合——新的字符可以与已有的标准化后的字符进行组合。例如,字符“Ä”可以用字符“A”和分音符“¨”组合而成。
语义——包含的字符必须有明确定义,必须与其他字符有明确的区别。
稳定——字符一旦被定义,就永远不能被移除,其代码点也不能被挪作他用。如果出错,则应该将代码点标记为弃用。
纯文本——标准中的字符应当是纯文本,永远不应该包含标记或元字符。
可转换——每一种编码都应该可以用Unicode编码表示。
原文:https://wisdom.engineering/awesome-unicode/
本文为 CSDN 翻译,转载请注明来源出处。
【End】
Python系列学习成长课来了!15年经验专家、CSDN特级讲师亲自授课,还等什么?立即扫码报名学习:















 3135
3135











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









