






一个月前更新了一本书,到第6章。然后停滞了,中间更新了一个实战文。原因很悲惨…过了将近一个月非人生活~就是在忙学位论文。终于在学术不端检测之后就要送外审了,我也松了一口气。
这一个月发生了什么呢?就不细说了,就是不停的忙着写论文,改论文这些~但是,这期间我中奖了!!!!!我中了一本书,也是Excel和python结合的书!!!中奖绝缘体的我居然中了!!!
待我这本书的笔记写完之后,我在更新那本书~~

感觉大家更喜欢笔记啊,这本书里面的Excel部分被我略过了,因为木有什么特别的东西~可能以后会更新一下Excel的内容吧~
叨叨完毕,开始更新这本书内容的第7-9章。
前面的几章内容分别是数据的获取,数据清洗,数据筛选等。属于是前中期的过程啦。第7-9章的内容是数据汇总、统计及输出,是最后的一部分。
数据汇总主要使用两个函数,一个是groupby函数和pivot_table。前者和SQL里面的内容比较类似,就是通过分类汇总达到的。后者是和Excel的数据透视表类似。
首先是分类汇总
df_inner.groupby(‘city’).count()
这个意思是通过按照city来进行分类,并统计个数
结果

但是这个是对于整个的内容进行了分类汇总,可是如果只想对于年龄进行汇总应该怎么办呢?
df_inner.groupby('city')['age'].count()
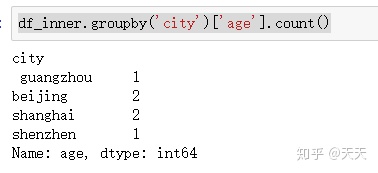
那我想根据多个来进行比较呢?在[]后面再加[]咯
常用的统计函数就是.count和.sum,当然还有比如求均值这些。
e.g.:通过city字段进行汇总并计算price的合计还有均值。
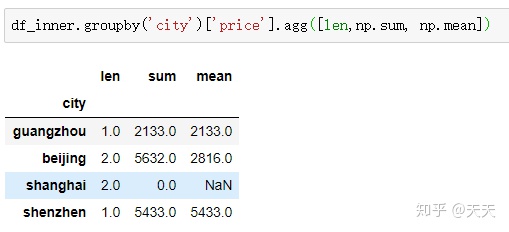
这里面上海出现了nan值。这个原因是因为源数据中有nan,这里要说明一下咯
除了这个groupby分组进行统计之外呢,还有数据透视表的功能,这里面要用到的是pandas库,pandas中的pivot_table就是用python实现数据透视表的功能了。功能更为强大,可以分别计算多个数据,并且还能按照行和列进行汇总,这就比groupby这个牛逼多了。。
借用书中的原图吧,因为anaconda里面没给表格。。。
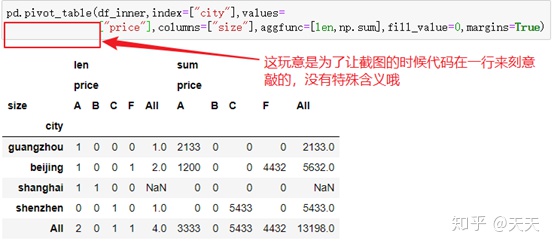
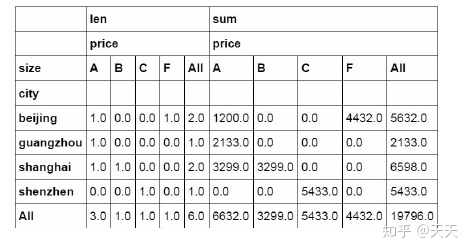
这个就是原图了,里面数据由差距,是我变动了~
说完了数据汇总之后,我们就来说说数据采样吧
最开始的前几章里,我们说了.head,.tail,.sample三个函数。分别是取前面数据,取后面数据以及随机取数据。这章我们对sample进行一些补充。比如说加个权什么的~~
sample(n = 想取的数据量,weights=权重)
手动设置权重的方法就是给weights传参咯
Weight= [0,0,0,1,0,0.5]
设置了六个数据的权重,在第四个和第六个上面权重更高
看一下效果
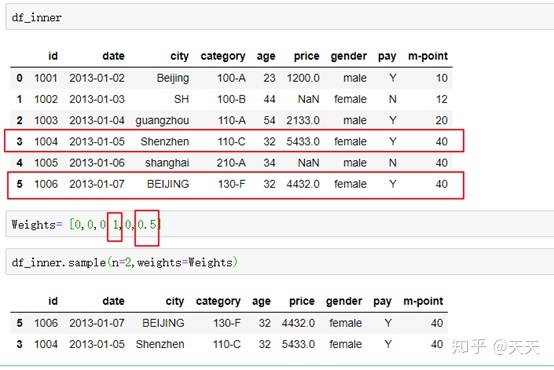
可以发现这个就是直接给权重高的截取下来了,但是我发现一问题,这个排序好像是按照权重低的先排,权重高的在下面,我来改下试试看。

谜一样的结果诶。。莫不是0.5就要在最高?
我再调一下多放一个
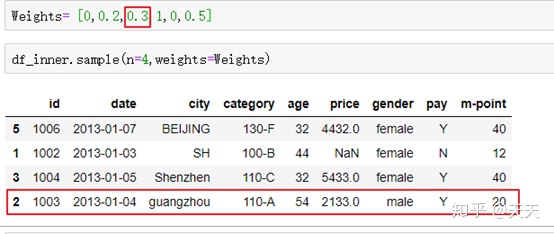
我尼玛是随机的啊。。。这个顺序就是 0.5,0.2,1,0.3了。。
看来应该就是随机的。暂且不研究了。
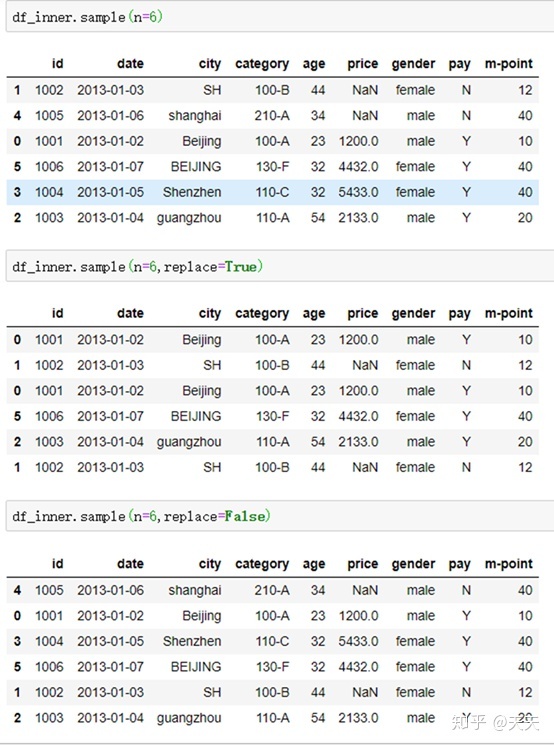
sample的参数中还有一个判断数据是否放回的。这里面我们来看看,参数是replace
这个列表一共就6个值,之前试过4个值,看不出来是什么东西,因为是随机取的。我就将所有数据都放进去了
我们看到下面如果放回是True的话,列表中可能出现重复的数据,如图0,1都分别出现两次。如果要是False的话,就不会出现重复数据。看来就这个功能了。。
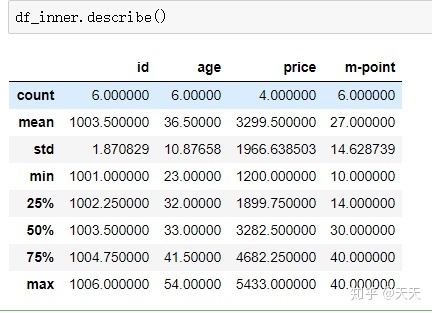
说完随机采样的sample函数之后,我们来说一下描述统计describe函数
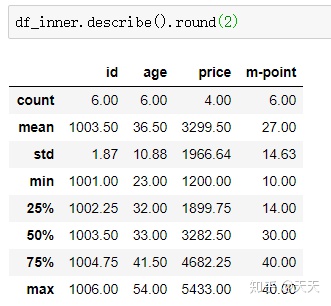
这个描述统计部分在前面也说过,就不细说了。就说一个数据结果转置
这个东西小数点后面那么多零,看起来很烦躁,缩减小数点。这里的方法是round(小数点位数)
那个括号里面是保留的位数。
转置很简单,后面加个T就可以了
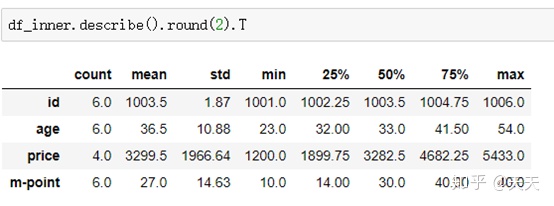
.std()标准差,.cov()可以用来求协方差。。这个就不演示咯
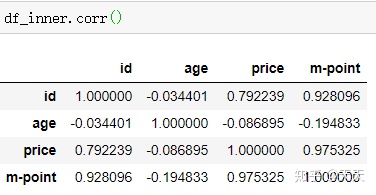
相关性分析要用corr函数来进行处理,返回值为相关系数,范围[-1,1].1是正相关,0是不相关,-1是负相关。

可以看到price和age值。。算是不相关咯
如果整个表来算的话。就是它了。
到此第八章数据统计也结束了。
最后一个数据输出就非常简单啦。主要是利用pandas进行导出。主要用Excel和csv
输出为EXCEL:to_Excel(Excel工作簿名字,sheet_name = Excel表名)
输出为CSV: to_csv('xxx.csv')
到此从EXCEL到PYTHON数据分析进阶指南这本书的理论部分就完全解决啦。最后的一部分就是一个实战。后期会按照这个思路来进行一下别的内容的分析~
到此,这本书就结束啦~~
敬请期待下一本书
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









