





Kubemetes 从 1.2 版本开始支持批处理类型 的应用,我们可以通过 Kubemetes Job 资源对象来定义井启动一个批处理任务。 批处理任务通常并行( 或者串行)启动多个计算进程去处理一批工作项( work item ),处理完成后 , 整个批处理任务结束。按照批处理任务实现方式的不同 ,批处理任务可以分为如图 2.5 所示的几种模式。
- Job Template Expansion模式 :一个 Job 对象对应一个待处理的 Work item ,有几个 Work item 就产生几个独立的 Job , 通常适合 Work item 数量少 、每个 Work item 要处理的数据量比较大的场景, 比如有一个 1OOGB 的文件作为一个 Work item , 总共 10 个文件需要处理。
- Queue with Pod Per Work Item 模式: 采用一个任务队列存放 Work item ,一个 Job 对象作为消费者去完成这些 Work item , 在这种模式下 , Job 会启动 N 个 Pod ,每个 Pod 对应一个 Work item 。
- Queue with Variable Pod Count 模式:也是采用一个任务队列存放 Work item ,一个 Job对象作为消费者去完成这些 Work item , 但与上面的模式不同 ,Job 启动 的 Pod 数量是可变的。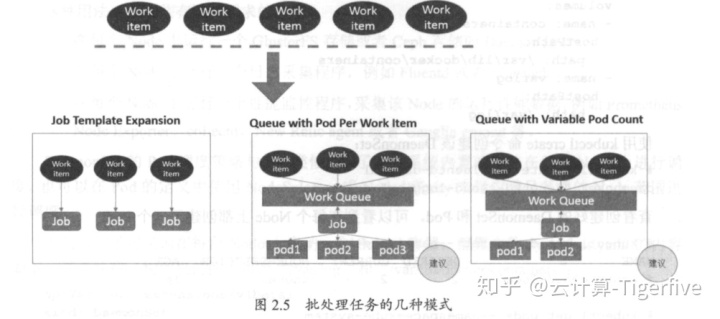
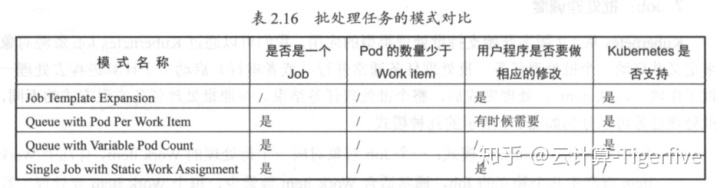
还有一种被称为 Single Job with Static Work Assignment 的模式,也是一个 Job 产生多个 Pod的模式,但它采用程序静态方式分配任务项,而不是采用队列模式进行动态分配 。 如表 2.16 所示是这几种模式的一个对比 。
考虑到批处理的并行问题, Kubemetes 将 Job 分以下三种类型。
1) Non-parallel Jobs 通常一个 Job 只启动一个 Pod ,则除非 Pod 异常,才会重启 该 Pod ,一旦此 Pod 正常结束 ,Job 将结束 。 2) Parallel Jobs with a fixed completion count 并行 Job 会启动多个 Pod ,此时需要设定 Job 的.spec.completions 参数为一个正数, 当正常结束的 Pod 数量达至此参数设定的值后, Job 结束。 此外, Job 的. spec. parallelism 参数用来控制并行度,即同时启动几个 Job 来处理 Work Item 。
3) Parallel Jobs with a work queue
任务队列方式的并行 Job 需要一个独立的 Queue, Work item 都在一个 Queue 中存放,不能 设置 Job 的 .spec.completions 参数,此时 Job 有以下特性。 。 每个 Pod 能独立判断和决定是否还有任务项需要处理。 。 如果某个 Pod 正常结束,则 Job 不会再启动新的 Pod 。 。 如果一个 Pod 成功结束,则此时应该不存在其他 Pod 还在干活的情况,它们应该都处 于即将结束、退出的状态。 。 如果所有 Pod 都结束了,且至少有一个 Pod 成功结束,则整个 Job 算是成功结束。
下面我们分别说说常见的三种批处理模型在 Kubemetes 中的例子。 首先是 Job Template Expansion 模式,由于这种模式下每个 Work item 对应一个 Job 实例,所以这种模式首先定义一个 Job 模板,模板里主要的参数是 Work item 的标识,因为每个 Job处理不同的 Work item 。如下所示的 Job 模板(文件名为 job.yaml.txt )中的$ITEM 可以作为任务项的标识:
apiVersion: batch/v1
kind: Job
metadata:
name: process-item-$ITEM
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo Processing item $ITEM && sleep 5"]
restartPolicy: Never
通过模板文件创建三个对应的Job定义文件并创建Job:
# mkdir job
# for i in tiger five six
> do
> cat job.yaml.txt | sed "s/$ITEM/$i/" > ./jon/job-$i.yaml
> done
# ls job
job-five.yaml job-six.yaml job-tiger.yaml
# # kubectl apply -f job/
job.batch/process-item-five created
job.batch/process-item-six created
job.batch/process-item-tiger created
查看运行状态
# kubectl get job -l jobgroup=jobexample
NAME COMPLETIONS DURATION AGE
process-item-five 1/1 14s 49s
process-item-six 1/1 22s 49s
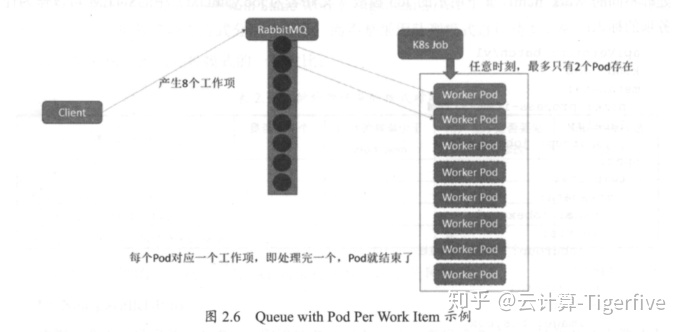
process-item-tiger 1/1 14s 49s其次,我们看看Queue with Pod Per Work Item 模式,在这种模式下需要一个任务队列存放Work Item, 比如RabbitMQ,客户端程序先把要处理的任务变成 Work item 放入到任务队列,然后编写 Worker 程序并打包镜像并定义 Job 中的Work Pod,Woker 程序的实现逻辑是从任务队列中拉取一个 Work Item并处理,处理完成后即结束进程,图2.6 给出了并行度为 2 的一个Demo示意图
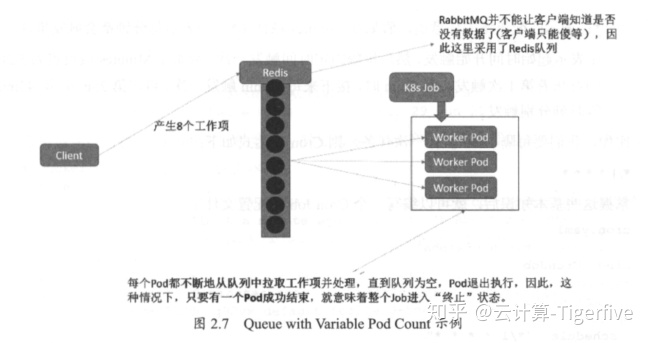
最后,我们再看看 Queue with Variable Pod Count 模式,如图所示。 由于这种模式下, Worker程序需要知道队列中是否还有等待处理的 Work item,如果有就取出来处理,否则就认为所有的工作完成并结束进程, 所以任务队列通常采用 Redis或者数据库来实现















 147
147











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









