






北京大学 胡琳
编者按
GPU作为一种硬件,相比较于CPU来说,有更多的并行度和更高的带宽,在图像处理领域取得了非常好的应用效果。越来越多的研究也正试图将GPU也应用到图计算领域中,然而GPU适合进行规则运算,但是图是一种不规则的数据表示形式,想要使用GPU高效处理图算法,需要更谨慎的策略。本文介绍一种在最近的文献中经常出现的图处理方式:动态任务分配—图上的计算任务并不是固定分配给GPU上的一个或若干个线程,而是使用动态的方式进行任务分配,最终使得不同线程得到的任务量更加均衡,从而实现更好的性能。本文将介绍三篇论文,它们进行的是不同的图算法,但是本质上都是采用动态任务分配提高性能。
背景介绍
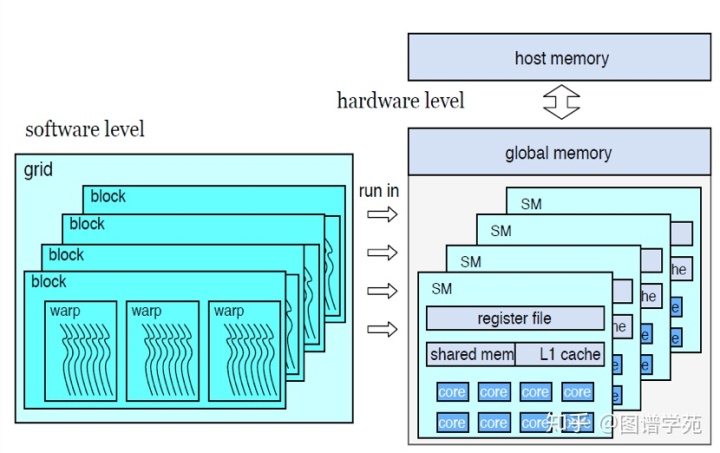
上图是一个GPU上的图架构的简单表示。硬件层来说GPU上的全局内存与主机内存相通,可以进行数据传输;GPU上有许多流多处理器(SM),每个流多处理器上有自己若干个核和自己的片上缓存,是相对独立的单元。软件层次上,程序员启动核函数(grid),其中包括多个block,每个block上又有若干warp。Block是依赖于流多处理器的,每个block只会运行于一个流多处理器。值得一提的是,每个warp中包含32个线程,这32个线程是按照严格单指令多线程的形式运行的,是严格的同步关系,因而warp内部线程在运行代码遇到分支或者循环结构时的线程发散会导致warp内部分线程的空闲,并且warp内线程执行的任务量的不均衡会导致很严重的线程发散,因为所有线程都在等待运行时间最长的线程结束。
线程发散是我们试图寻找更好的任务分配方式的初衷,更好的任务分配方式能够保证更少的线程发散,从而提升整体性能。

上图是GPU上的存储访问示意图,图(a)中,相邻的线程访问的是相邻并且对齐的地址,这样多个线程所需要的数据可以在较少的访存请求中一起取回来,而(b)图中线程访问的地址是随机的,无序的,就需要更多的访存次数。我们称(a)图中的模式是合并访存模式,是一种更加高效的访存方式。
例子:
首先我们会以三角形计数为例子,讲解什么是更好的任务分配方式。
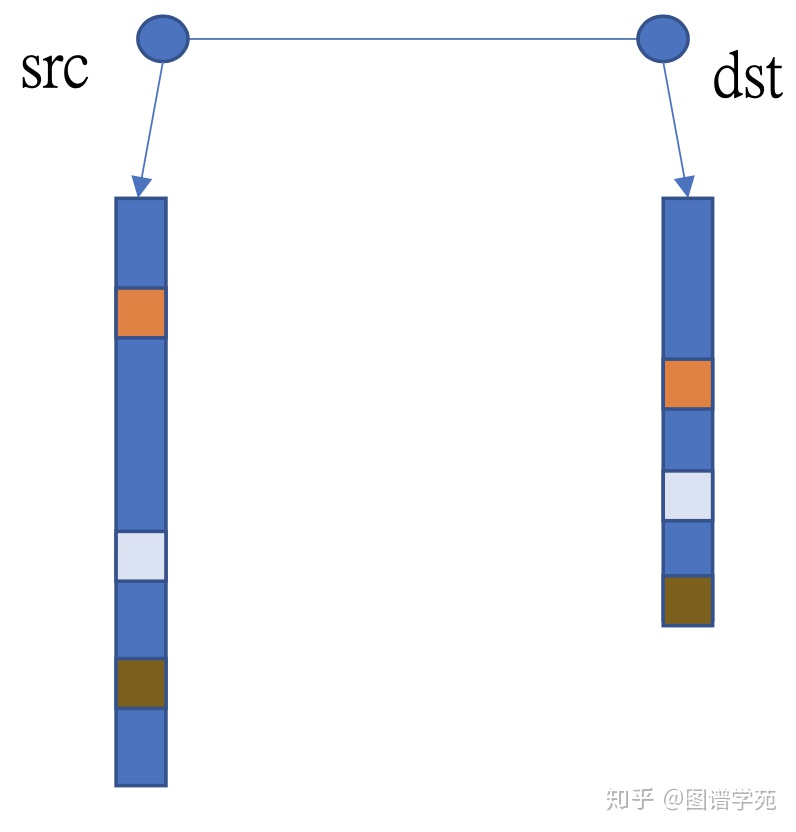
在图(graph)表示中,三个彼此相邻的节点我们称作一个三角形,三角形计数算法是求解一个图中所有三角形数目。通常三角形计数的方式如上图所示:对于一条边,对这条边的起点(src)和终点(dst)的邻接表取交集,交集的大小就是这条边所在的三角形的数目。很自然的,在三角形计数算法移植到GPU上的时候,我们可以以边作为任务分配的单位,一个线程负责处理一条边,计算这条边所在的三角形的个数。这种分配方式看起来很直观,但是会导致任务分配不均衡的情况,因为在常见的power-law图中邻接表的大小区别很大,线程的工作量也就会有很大区别,从而导致线程发散。
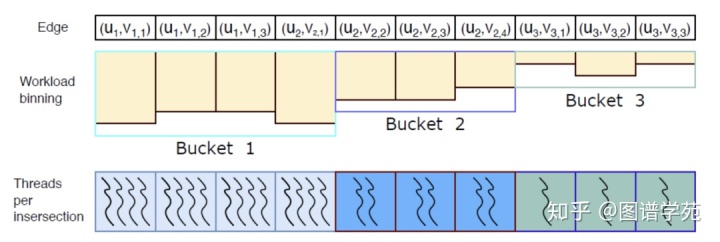
上图中介绍了一种优化了的任务分配方式,首先对于所有边的任务进行估计,然后把边按照任务量的大小分成不同的组。对于任务量很大的边所在的组,每个边分配多一些线程去处理,任务量少的边就分配较少的线程。这个方式利用事先对任务量的估计,根据任务量分配计算资源,在一定程度上缓和了线程工作量负载不均衡的问题,比前面介绍的根据边分组相比,有更好的效果。
论文1: GPU-based Graph Traversal on Compressed Graphs, SIGMOD 2019
本文设计了一个GCGT的图处理系统,针对的是大规模图中的并行算法,并且算法中包含“扩张—过滤—压缩”的过程。
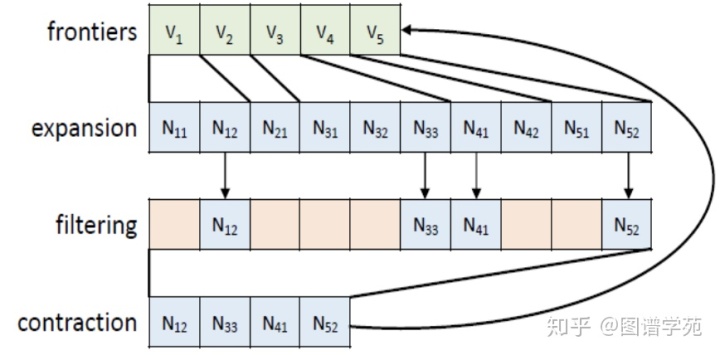
上图以BFS为例,展示了在BFS的每一轮扩展的前沿(frontier)生成过程中,“扩张—过滤—压缩”的具体过程。这里“扩张”的依据是邻接关系,“过滤”是取出未访问节点,“压缩”是生成新的前沿节点。这种计算模式在BC (Betweeness Centrality), CC(Connected Component)等算法中也有很多的应用。由于是大规模图,本文中首先采用已有的方式进行图的压缩表示,如下图所示。
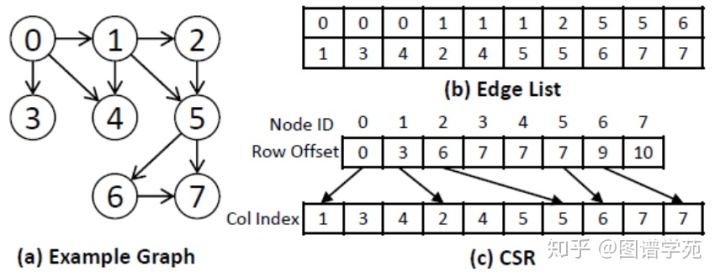

上图表示了图中邻接表的压缩过程,邻接表中连续的元素成为一个interval,只记录其首个元素和大小,不连续的元素成为residual,单独列在后面。Interval和residual记录的都是和前一个元素的差,这样可以减小存储空间。同时文章又采用了VLC 编码的方式,压缩字符的存储位数,进一步减少存储空间。这里我们只讨论图遍历算法,即给出一个前沿向外扩展,并如此迭代进行的过程。

上图算法一中给出了一个直观的算法,每个线程负责处理一个点的邻接表,直接扩展这个邻接表中的所有节点。跟例子中介绍的直观三角形计数算法影响,由于图的power-law的性质,线程之间会存在比较明显的工作量负载不均衡的情况。

算法二中给出了GCGT的实现:所有的线程会先处理intervals然后处理residual,并且一个warp中的所有线程会同时进入处理residuals的阶段。并且处理interval也是分成两步,先处理长度大于32(一个warp的大小)的interval,再处理小于32的。
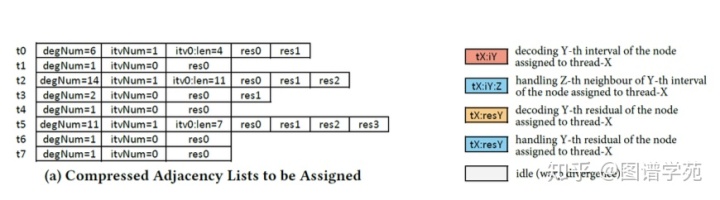
上图中给出了一个图表示,图中共有8个节点。同时,图例中是线程处理residual和interval的图例。在这个算法中,每个线程起初仍然先获得一个邻接表,只不过后面warp中的32个线程协同处理获得的32个邻接表。
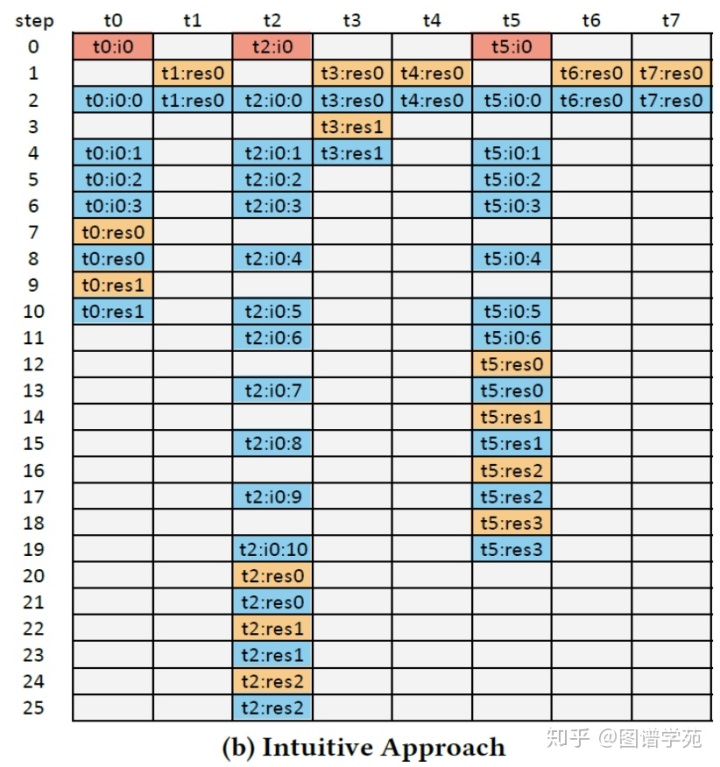
上图中是直观实现中,示例图的处理流程图。每个线程面对一个邻接表,都要先解码,然后处理interval和residual。考虑到warp内线程的lock-step执行特性,decoding、处理interval、处理residual是不能同时进行的。所以图中会有大量idle的存在,并且整个warp的运行时间是由运行时间最长的线程决定的。
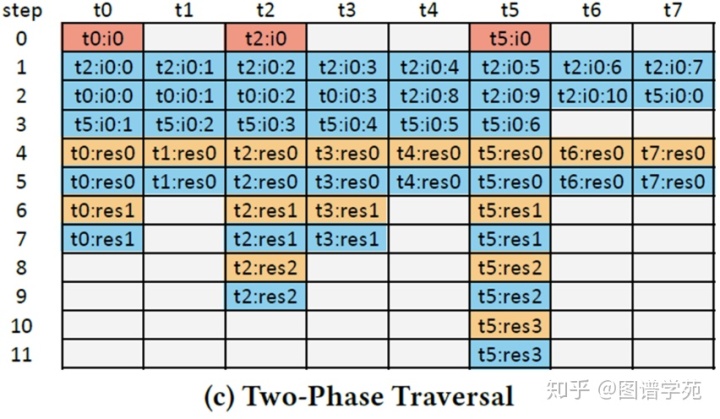
上图中表示的是GCGT框架下的处理流程图。这里主要是针对interval做了改进。所有的线程先协同处理最长的interval(图中t2获得的邻接表),剩下的Interval拼接起来,也由全部的线程协作完成。这里整体的处理周期由25缩减成11,有了非常明显的提高。对于residual部分,也有一些改进,如下图所示。
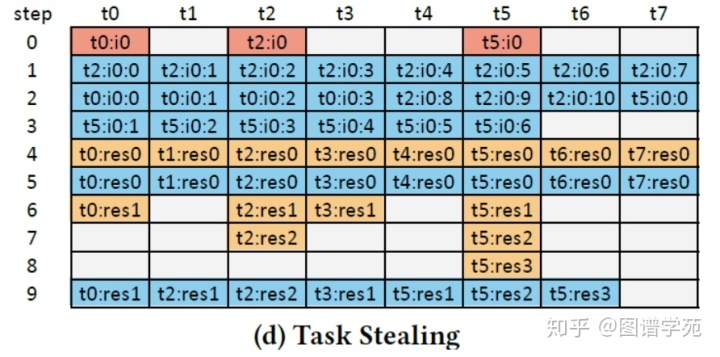
对于residual的处理也包括了解码和访存两部分,这里采用的优化是所有的线程先完成自己任务中residual的解码,然后把任务拼接起来所有线程共同完成访存。可以看到整体周期进一步缩减成9。每个线程要独自完成解码的原因是由编码的方式导致的,解码需要用到前一个元素的真实值。
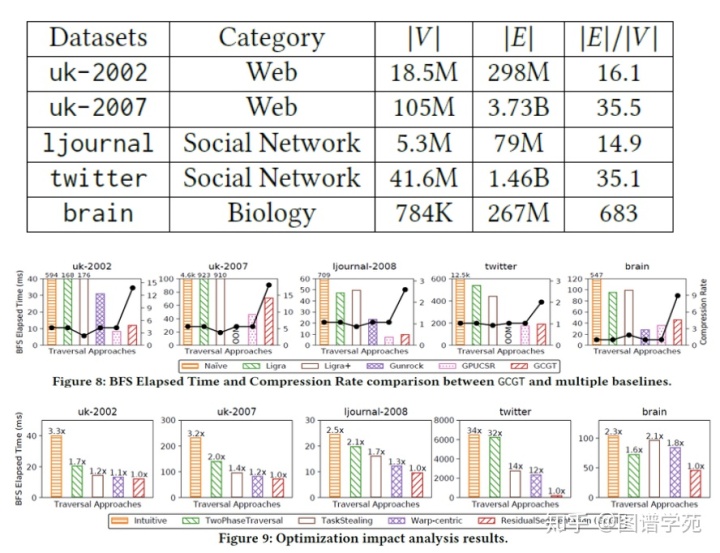
最后从实验结果来看,横向比较中GCGT比其他框架都有性能优势,只比GPU上的CSR表示略差,但是提供了一定的压缩比;纵向来看,每一步策略都取得了一定的优化效果。
论文2: High Performance and Scalable GPU Graph Traversal,TOPC 2015
本文中使用到任务动态分配的部分,也仅仅是从邻接表中收集邻居的部分。详细来说,对于一个BFS过程,这个算法仅仅从一系列邻接表中读进来所有的邻居,并且加载进本地存储或寄存器中。
接下来我们比较几种实现。
1. 顺序读取
每个线程获取一个邻接表的起始和终止范围,然后负责记载这个邻接表中的所有元素。很显然,这是一个非常naïve的想法,线程的负载均衡会很差。
2. 粗粒度的,warp协同的方法
下图算法5中展示了warp协同的方法,warp中的线程竞争warp的控制权,竞争的胜利者将自己的任务广播给warp中所有的线程,大家一起完成该任务,然后重复“竞争-广播-协作”的过程。
此方法中,warp内每个线程的工作都是由整个warp内所有的线程协同完成的,比较好地均衡分配了任务。

3. 细粒度的,基于scan的方法
下图展示了基于scan的方法的算法流程。这个方法中,将一个block中所有的线程获得的邻接表都拼接到一起,然后所有block中的线程协作处理这个拼接完成后的表。这个算法比上一个算法更好的地方在于协调了整个block内线程的工作负载,但是也有额外的拼接代价。

4. Scan+warp 协调+block协调的方式。
1) 邻接表长度非常大的线程首先竞争整个block的控制权,整个block的运算资源都一起处理这个邻接表。
2) 剩下的线程中,邻接表长度适中的,线程竞争warp控制权,整个warp协作处理。
3) 最后剩下工作量比较小的线程,所有的任务拼接到一起,由整个block协作完成。
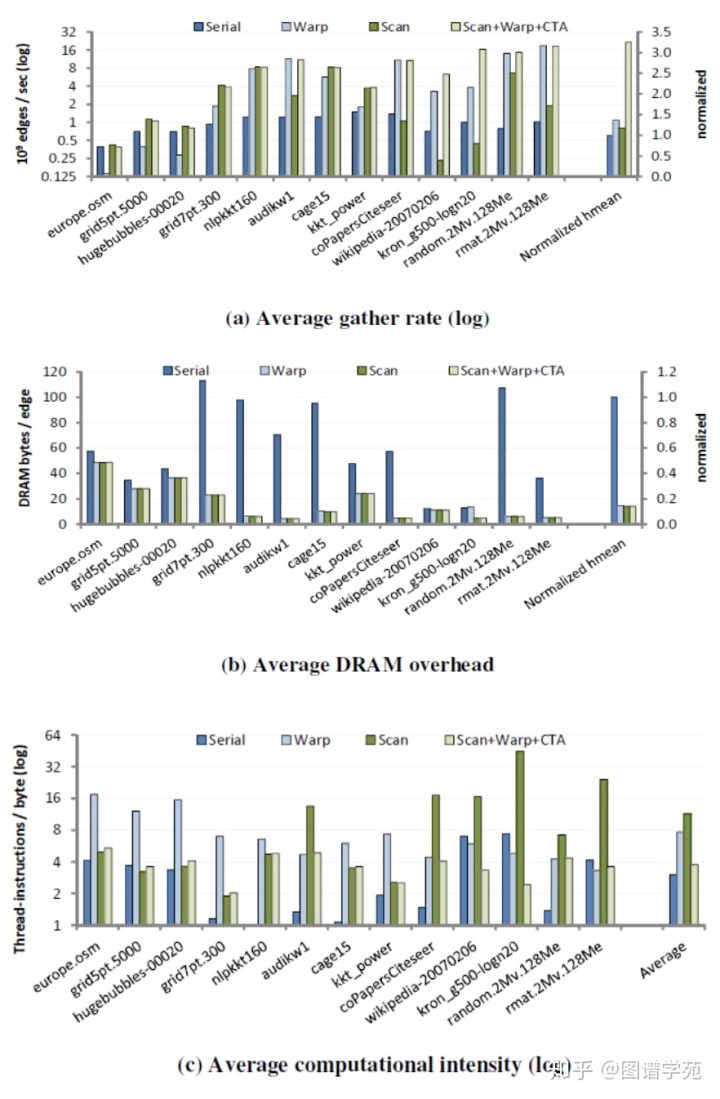
这个算法很好地协调了整个block内的工作负载的均衡性,又减少了大量拼接的代价,是最优的解决方案。从下面的三个性能指标中也能看出来,上面几种算法的性能,以及跟最优性能之间的差异。
论文3:Update on Triangle Counting on GPU ,HPEC 2019
这篇文章研究的是GPU上的三角形计数算法,其中naïve的三角形计数的任务分配在前面已经介绍过了,使用一个线程处理一条边。下面的算法1就是这种实现的伪代码。

上文中我们还介绍了优化的三角形计数的任务分配,即根据任务量的预先估计,给每个边分配合适的线程,使得线程的任务大致相当。但是这种算法也有它的局限性:预先估计需要消耗额外的时间;并且同一组中的边获得相同数目的线程,但是实际上它们的任务量也有区别。
本文中提出了动态分配的三角形计数算法,算法伪码如下算法2所示

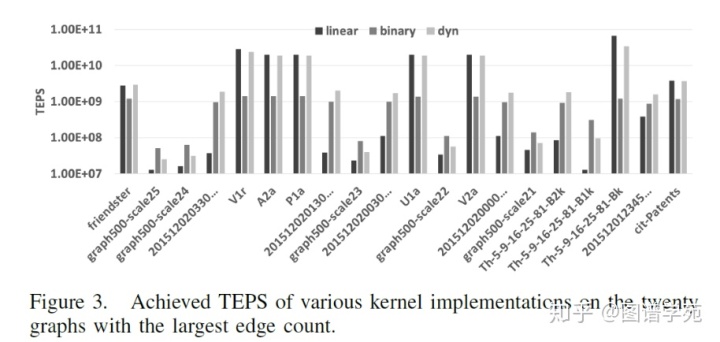
这里采用的方法跟前面的两种论文中的思想有些类似,一个线程获得整个warp的控制权,向所有线程广播自己的任务,然后大家协同完成这组任务,这样warp内线程的工作是非常均衡的。实验效果如下图所示
总结
动态任务分配是GPU上进行图计算任务中一种比较好的任务分配方式,可以使线程之间的工作量更加均衡,很好解决图的不规则形带来的问题,并且能够减少线程的发散,实际上也有更好的合并访存效果。这种方法也不是完美的,动态计算需要额外的计算开销,以便得到线程各自的任务。当然这种负面影响完全可以被所带来的性能提升抵消。综合而言,这种方法还是非常值得我们学习和借鉴。
参考文献
[1] J. Fox, O. Green, K. Gabert, X. An, and D. A. Bader. Fast and adaptive list intersections on the gpu. In 2018 IEEE High Performance extreme Computing Conference (HPEC), pages 1–7. IEEE, 2018. [2] O. Green, J. Fox, A. Watkins, A. Tripathy, K. Gabert, E. Kim, X. An, K. Aatish, and D. A. Bader. Logarithmic radix binning and vectorized triangle counting. In 2018 IEEE High Performance extreme Computing Conference (HPEC), pages 1–7. IEEE, 2018.[3] Sha M, Li Y, Tan K, et al. GPU-based Graph Traversal on Compressed Graphs[C]. international conference on management of data, 2019: 775-792.[4] Duane Merrill, Michael Garland, and Andrew Grimshaw. 2015. High-Performance and Scalable GPU Graph Traversal. ACM Trans. Parallel Comput. 1, 2, Article 14 (January 2015), 30 pages.[5] C. Pearson et al., "Update on Triangle Counting on GPU," 2019 IEEE High Performance Extreme Computing Conference (HPEC), Waltham, MA, USA, 2019, pp. 1-7, doi: 10.1109/HPEC.2019.8916547.
















 1421
1421











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









