







©PaperWeekly 原创 · 作者|孙裕道
学校|北京邮电大学博士生
研究方向|GAN图像生成、情绪对抗样本生成
引言 年龄和性别在社会交往中起着基础性的作用。随着社交平台和社交媒体的兴起,自动年龄和性别分类已经成为越来越多应用程序的相关内容。本文会盘点出近几年来关于深度年龄和性别识别的优质论文。
CVPR 2015

论文标题:Age and Gender Classification using Convolutional Neural Networks
论文来源:CVPR 2015
论文链接:https://www.sci-hub.ren/10.1109/CVPRW.2015.7301352
代码链接:https://github.com/GilLevi/AgeGenderDeepLearning
1.1 模型介绍在该论文是第一篇将深度学习引入到年龄和性别的分类任务中,作者证明通过使用深卷积神经网络的学习表示,可以显著提高年龄和性别的分类任务的性能。因此,该论文提出了一个卷积网络架构,即使在学习数据量有限的情况下也可以使用。
从社交图像库收集一个大的、带标签的图像训练集,用于年龄和性别估计,需要访问图像中出现的对象的个人信息,这些信息通常是私有的,或者手动标记既繁琐又耗时。因此,用于从真实社会图像中估计年龄和性别的数据集在大小上相对有限。当深度学习的方法应用于如此小的图像采集时,过拟合是一个常见的问题。
如下图所示,为作者提出的一个简单的 CNN 网络架构,该网络包含三个卷积层,每个卷积层后面都有一个校正的线性运算和池化层。前两层使用对参数进行正则化操作。
第一卷积层包含 96个7×7 像素的卷积核,第二个卷积层包含 256 个 5×5 像素的卷积核,第三层和最后一层包含 384 个 3×3 像素的卷积核。最后,添加两个全连接层,每个层包含 512 个神经元。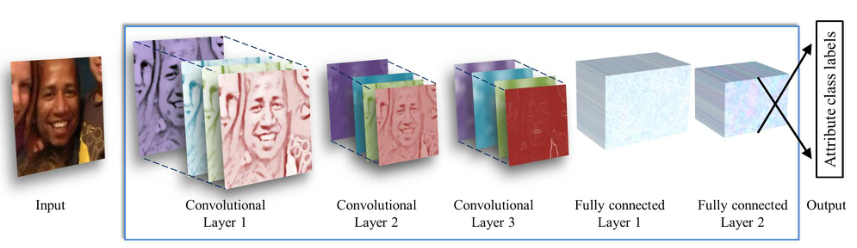
在训练网络的过程中,作者还应用了两种额外的方法来进一步限制过度拟合的风险。第一个是 dropout 学习(即随机设置网络神经元的输出值为零)。该网络包括两个 dropout 层,丢失率为 0.5(将神经元的输出值设为零的几率为 50%)。
第二个是使用数据增强技术,从 256×256 的输入图像中随机抽取 227×227 个像素,并在每个前后训练过程中随机镜像。这与使用的多种裁剪和镜像变体类似。1.2 实验结果
作者使用 Adience 数据集进行基准测试 CNN 设计的准确性,该数据集是为年龄和性别分类而设计的。Adience 集包括从智能手机设备自动上传到 Flickr 的图像。
因为这些图片是在没有事先人工过滤的情况下上传的,就像媒体网页或社交网站上的典型情况一样。整个 Adience 收藏包括 2284 个受试者的大约 26K 张图片。如下表所示列出了收集到的不同性别和年龄组的分类情况。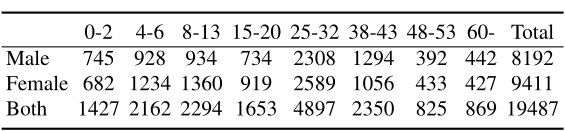

 下图为年龄错误分类。第一行:年长的被试被误认为是年轻人。最下面一行:年轻人被误认为是老年人。
下图为年龄错误分类。第一行:年长的被试被误认为是年轻人。最下面一行:年轻人被误认为是老年人。
 由上面两张图是系统所犯的许多错误都是由于某些 Adience 基准图像的观看条件极为困难所致。最值得注意的是由模糊或低分辨率和遮挡(尤其是浓妆)引起的错误。性别估计错误也经常发生在婴儿或非常年幼的儿童的图像中,因为这些图像还没有明显的性别属性。
由上面两张图是系统所犯的许多错误都是由于某些 Adience 基准图像的观看条件极为困难所致。最值得注意的是由模糊或低分辨率和遮挡(尤其是浓妆)引起的错误。性别估计错误也经常发生在婴儿或非常年幼的儿童的图像中,因为这些图像还没有明显的性别属性。

IWBF 2018

论文标题:Age and Gender Classification from Ear Images
论文来源:IWBF 2018
论文链接:https://arxiv.org/abs/1806.05742
2.1 论文贡献
该论文是一篇有趣文章,研究是从耳朵图像进行年龄和性别的分类。作者采用卷积神经网络模型 AlexNet、VGG-16、GoogLeNet 和 squezenet。在一个大规模的耳朵数据集上进行了训练,分类器通过人耳对性别和年龄进行分类。该论文的贡献分为三个部分:
- 对于几何特征,作者在耳朵上使用了 8 个标志点,并从中衍生出 16 个特征。
- 对于基于外观的方法,作者使用了一个大型 ear 数据集,利用卷积神经网络模型来对年龄和性别进行分类。
- 与之前的工作相比,作者在性别分类方面取得了优异的成绩。
2.2 模型介绍
论文使用几何特征和在这些特征上使用的分类器,以及基于外观的表示进行分类。2.2.1 几何特征
下图为人耳标志位和相关的几何特征。由于每个几何特征具有不同的取值范围,为了使其规范化,作者在训练集中计算了每个特征的均值和标准差。然后并对它们进行归一化,使它们具有零均值和单位方差。在 16 个耳朵的几何特征中选择出重要的6个。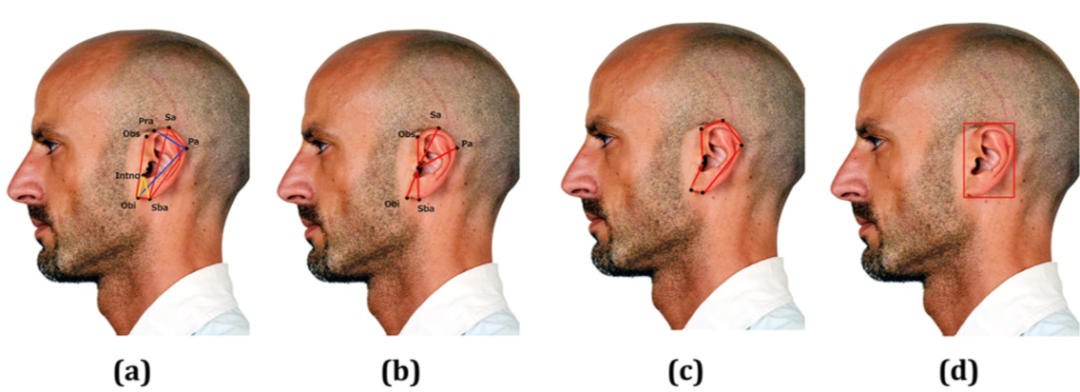
2.2.2 基于外观的表示与分类
本研究中使用的第一个深度卷积神经网络结构是 AlexNet。AlexNet 包含五个卷积层和三个全连接层。在网络训练中,为了防止过度拟合,采用了 dropout 方法。第二个深度卷积神经网络结构是 VGG-16。
VGG-16 包含 16 个卷积层,3 个全连接层和在卷积层之后的 softmax 分类器。第三个深度卷积神经网络结构是 GoogleNet,它是一个更深层次的网络,包含 22 层。它基于初始模块,主要是几个初始模块的串联。
inception 模块包含几个不同大小的卷积核。将不同的卷积核输出组合起来。最后一个 CNN 架构是 squezenet,它提出了一种减少参数数量和模型大小的新方法。使用 1×1 过滤器,而不是 3×3 过滤器。该体系结构还包含剩余连接,以提高反向传播学习的效率。此外,没有全连接层。使用平均池化层,而不是全连接层。2.3 实验结果
2.3.1 数据集介绍 论文选用的数据集包含 338 个不同对象的面部轮廓图像。这个数据集中的所有受试者都超过18岁。从下图可以看到来自数据集的样本图像。这些受试者分为五个不同的年龄组。这些年龄组分别为 18-28、29-38、39-48、49-58、59-68+。根据几何特征的变化对年龄组进行分类。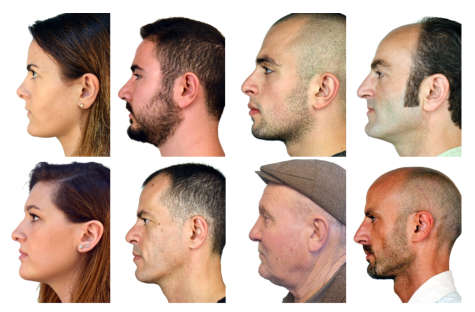
2.3.2 性别分类结果
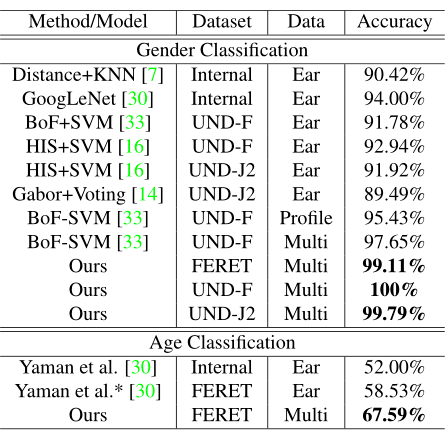
如下表所示为性别分类的结果,第一列为分类器的名称,第二列包含相应的分类精度。为了提醒读者所使用的特性,第二列的括号中包含了这些特性的类型。从表中可以看出,基于外观的方法优于基于几何特征的分类器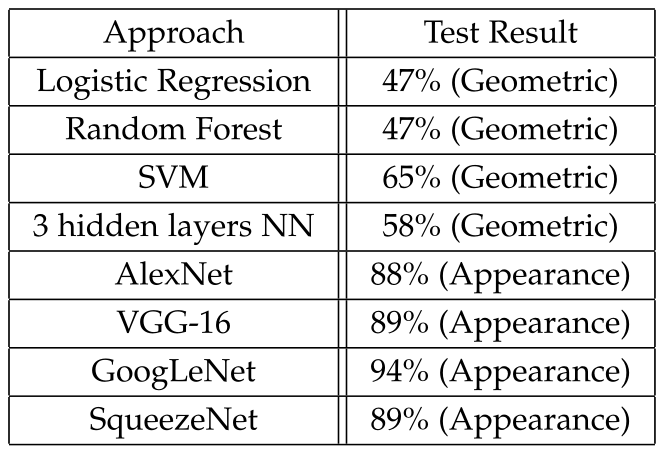
2.3.3 年龄组分类结果
如下表所示为年龄组分类的结果,同样的,第一列包含分类器的名称,第二列包含相应的分类精度。我们会发现,基于几何特征的方法和基于外观的方法之间的性能差距很小,基于外观的方法能稍微优越一点。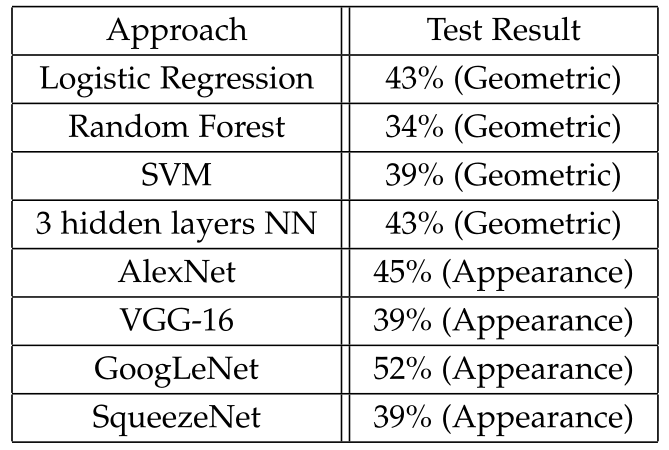

CVPR 2019

论文标题:Multimodal Age and Gender Classification Using Ear and Profile Face Images
论文来源:CVPR 2019
论文链接:https://arxiv.org/abs/1907.10081
3.1 核心思想在该论文中,作者提出一个多模态深度神经网路的年龄和性别分类框架,输入为一个侧面的脸和一个耳朵的图像。主要目标是通过进一步利用生物特征识别方法:耳朵外观,来提高从侧面人脸图像中提取软生物特征的准确性。轮廓人脸图像包含了丰富的年龄和性别分类信息源。本篇论文的贡献分为以下三个部分:
作者提出了一个多模式年龄和性别分类系统,该系统以侧面人脸和耳朵图像为输入。所提出的系统执行端到端多模式、多任务学习。
作者全面探讨了利用多模式输入进行年龄和性别分类的各种方法。并采用了三种不同的数据融合方法。
作者将中心损失和 softmax 损失结合起来训练深度神经网络模型。
3.2 模型介绍
3.2.1 CNN网络和损失函数
在本文中采用了 VGG-16 和 ResNet-50 神经网络结构。在 VGG16 中,有 13 个卷积层和3个全连接层。为防止过度拟合,采用了 dropout 方法。另一个 CNN 模型是 ResNet-50。与 VGG-16 不同,除了 ResNet-50 的输出层外,没有全连接层。在卷积部分和输出层之间存在一个全局池化层。两个网络的输入大小都是 224×224。
作者利用中心损失函数和 softmax 函数来获得更多的鉴别特征。中心损失背后的主要动机是提供更接近相应类中心的特性。测量特征到相关类中心的距离,计算出中心损失。中心损失试图为每个类中心生成更接近的特征,但它不负责提供可分离的特征,因此,softmax 损失对其进行了补充。具体的计算公式如下: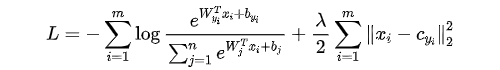 3.2.2 多模态多任务
作者研究了年龄和性别分类的性能,分别使用耳朵和侧面人脸图像,作为单峰系统,并结合作为一个多模式,多任务系统。对于多模式、多任务年龄和性别分类总损失计算,作者结合了年龄和性别预测的所有损失。具体的计算公式如下所示:
3.2.2 多模态多任务
作者研究了年龄和性别分类的性能,分别使用耳朵和侧面人脸图像,作为单峰系统,并结合作为一个多模式,多任务系统。对于多模式、多任务年龄和性别分类总损失计算,作者结合了年龄和性别预测的所有损失。具体的计算公式如下所示:
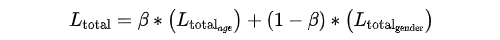
3.2.3 数据融合
为了实现数据融合,作者采用了三种不同的方法,即空间融合、强度融合和信道融合。在空间融合中,将侧面人脸和耳朵图像并排连接起来。在信道融合中,将图像沿着通道串联起来。在强度融合中,平均化轮廓面部和耳朵图像的像素强度值。具体详情如下图所示: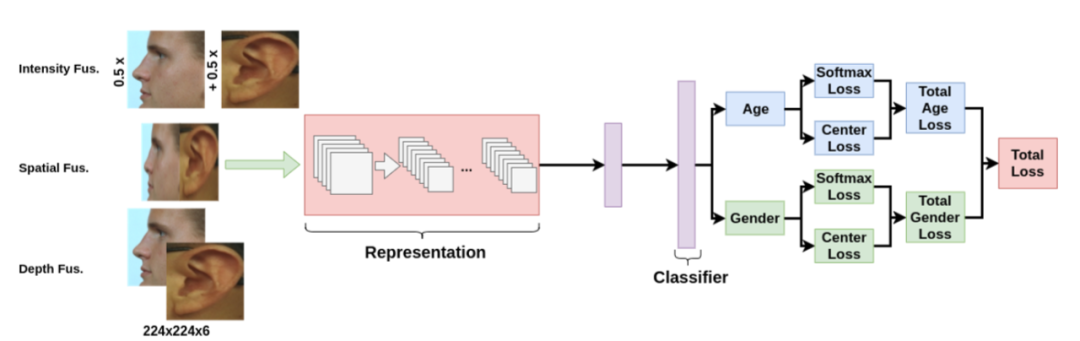
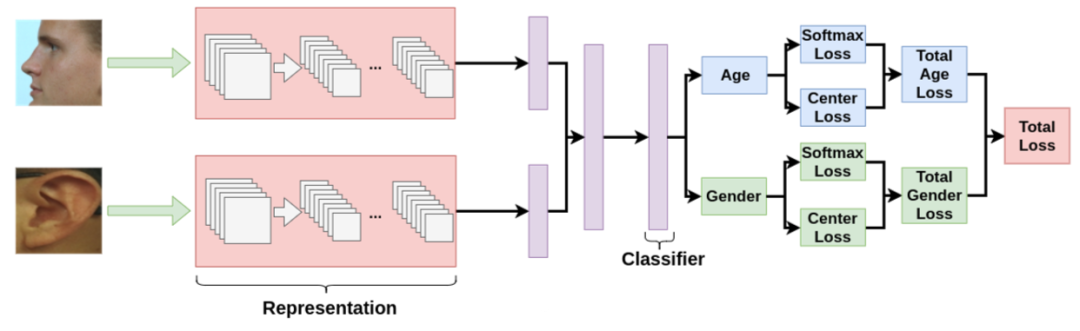
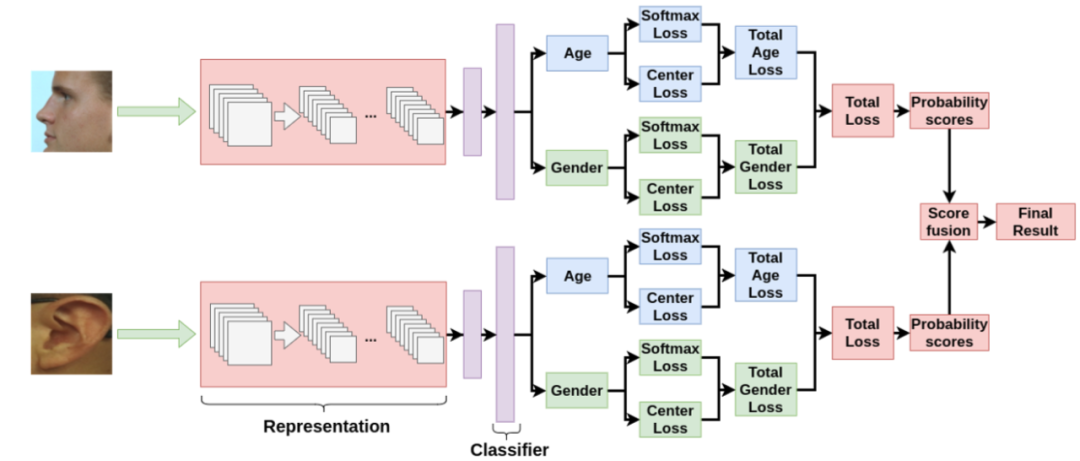
3.4 实验结果
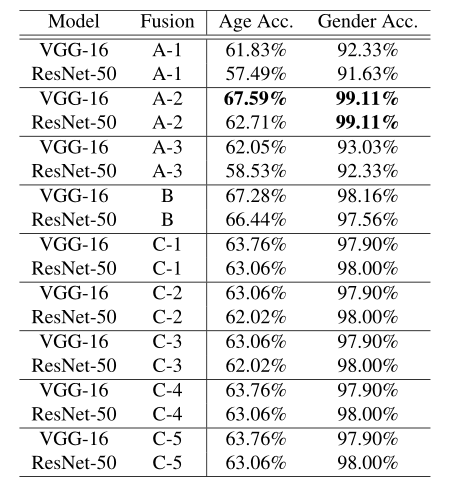
如下表所示显示了基于不同融合方法的年龄和性别分类结果。第一列分类模型。第二列为融合方法,其中 A、B 和 C 分别对应于数据、特征和分数融合方法。在方法 A 中,A-1、A-2 和 A-3 分别是信道融合、空间融合和强度融合。
在 C 中,C1、C2、C3、C4 和 C5 代表不同的置信度计算方法。实验结果表明,VGG-16 模型采用 A-2 融合方法,即空间融合,取得了最佳的年龄分类效果。
更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
? 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
?
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
















 1440
1440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









