





在上一篇文章(http://www.cnblogs.com/fangtaoa/p/8321449.html)中,我们实现了12306爬虫的登录功能,接下来,我们就来实现查票的功能.
其实实现查票的功能很简单,简单概括一下我们在浏览器中完成查票时的主要步骤:
1.从哪一站出发
2.终点站是哪里
3.然后选定乘车日期
既然我们已经知道是这个步骤了,那我们应该怎样通过程序的形式来实现这个步骤呢?
最主要的问题:
1.在程序中我们如何获取站点.不妨想一下,选择的站点是全都保存到一个文件中,还是分开的?
2.乘车日期是不是不能小于当前系统时间而且也不能大于铁路局规定的预售期(一般是30天左右)
好了,到目前为止,我们主要的问题是如何解决上面两个问题!
首先我们要明白一点:车票信息是通过异步加载的方式得到的
我们先看一下查票的URL:
出发日期:2018-02-22, 出发地:深圳,目的地:北京
https://kyfw.12306.cn/otn/leftTicket/queryZ?
leftTicketDTO.train_date=2018-02-22&
leftTicketDTO.from_station=SZQ&
leftTicketDTO.to_station=BJP&
purpose_codes=ADULT
我们重点关注2个字段:
1.from_station=SZQ
2.to_station=BJP
问题来了:我们明明选择了出发地是:深圳,目的地:北京,那么在from_station中为什么是SZQ,to_station中是BJP?
from_station和to_station的值好像不是深圳和北京被加密后的值,而是和他们的汉语拼音首字母有点联系
那我们做一个大胆的猜测:12306网站那边应该是把每个站点都与一个唯一的站点代码建立起了关联!
通过以上分析,我们就有更加明确的目标去进行抓包(抓包这次使用Chrome中的工具)!
我们填好所有必要信息时,点击查询按钮,得到的结果如下:
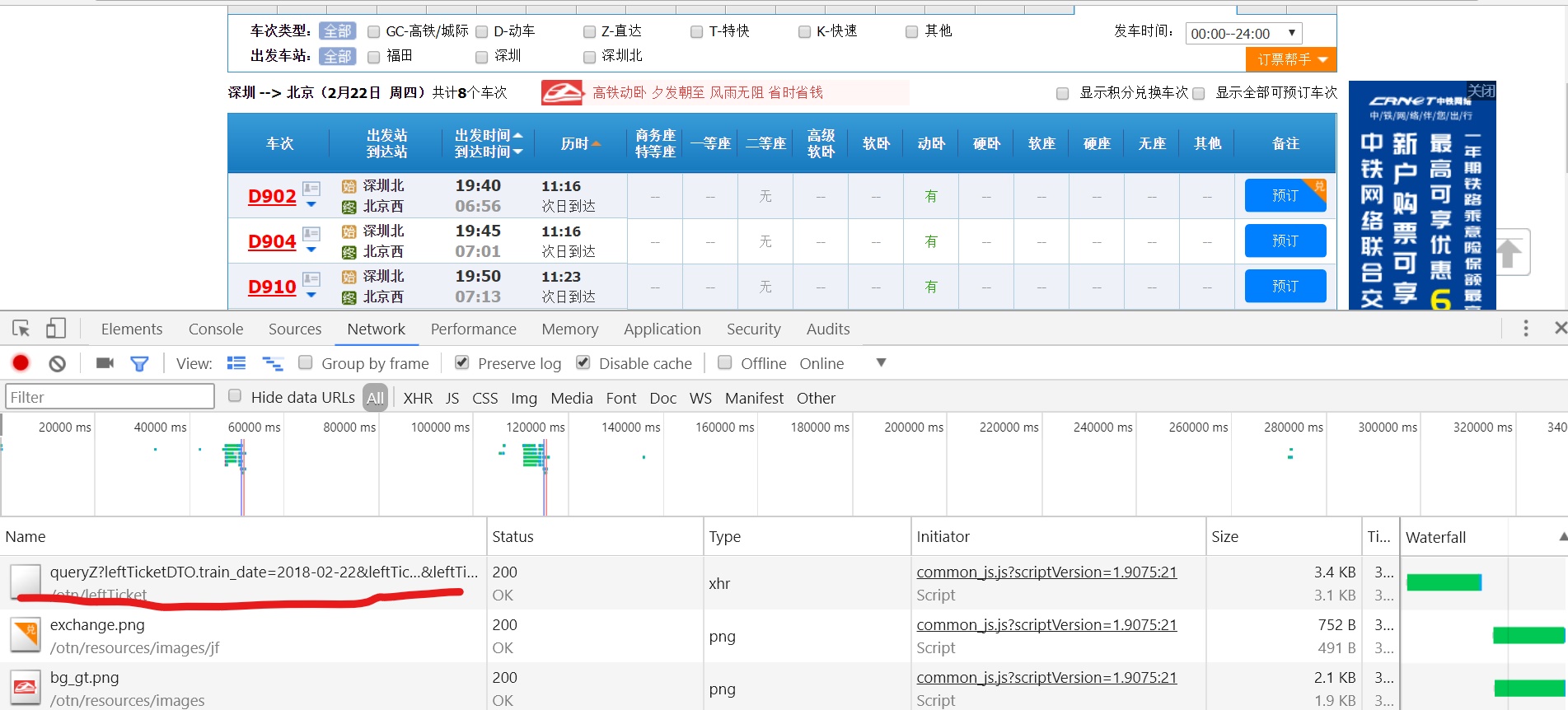
在所有结果中我们只看到了3条信息,最主要的还是第一条,我们看看里面的结果是什么
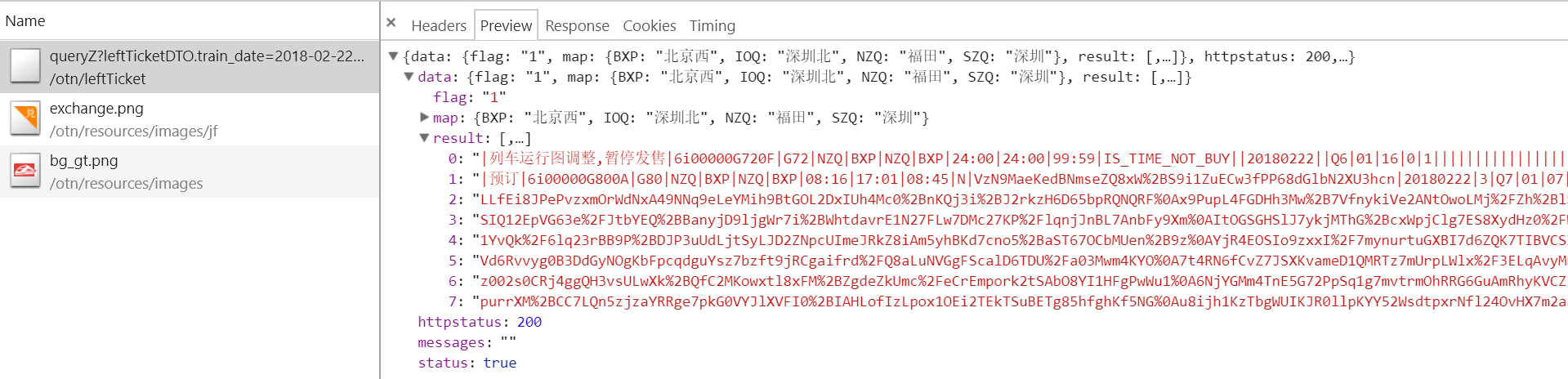
很明显我们得到从深圳到北京的所有车次信息了!
其他两个结果都是图片,不可能是站点啊,找不到站点信息,这可怎么办?
┓( ´-` )┏
那我们点击刷新按钮来看看会出现什么结果
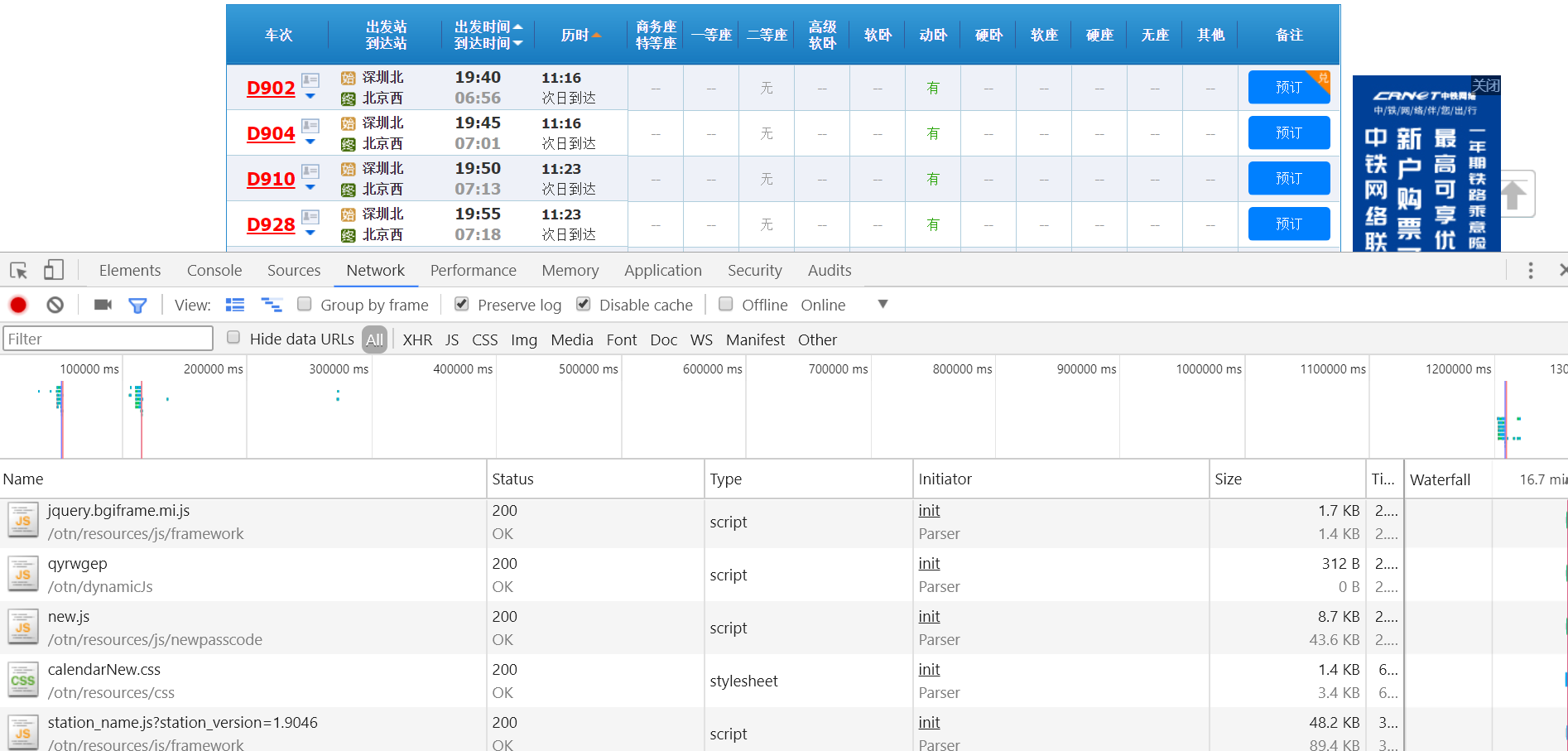
这次好像有好多东西出来了,那我们运气会不会好一点,能找到一些站点信息呢?
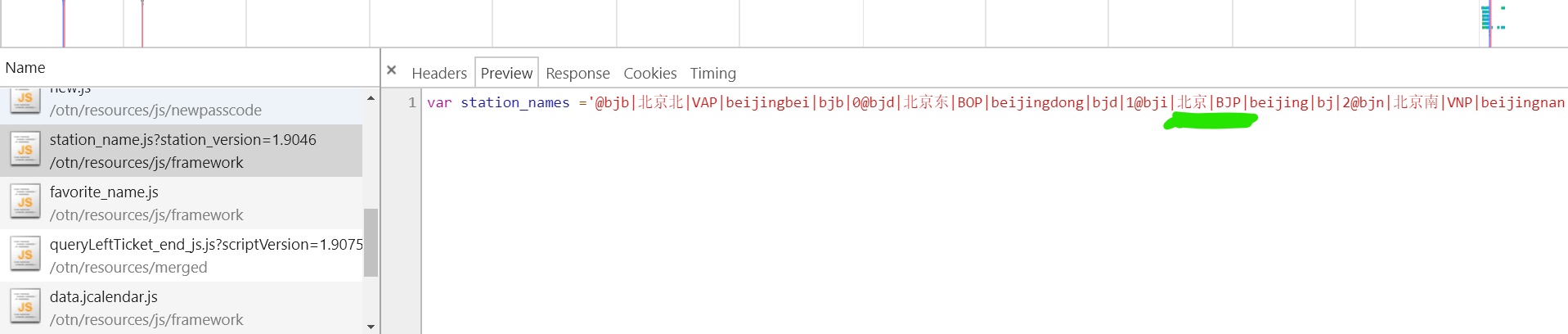
哦,好像我们发现了什么东西!!!!!!
在station_name.js中我们看到了熟悉的字段:BJP,那就让我们的这里面探索探索吧!!!
那么目前为止我们的工作就只剩下代码的事情了
我们只要两个请求就好了:
1.用GET请求把station_name.js中的数据全都获取到,并保存到文件中,我们需要用到,而且最好是以字典的格式保存
2.同样用GET请求去获取查票的URL,看看有出发地到目的地有哪些车次信息.
项目结构:
完整的代码如下:
1 from login importLogin2 importos3 importjson4 importtime5 from collections importdeque, OrderedDict6
7 classStation:8 """查询车票信息"""
9
10 def __init__(self):11 #使用登录时候的session,这样好一些!
12 self.session =Login.session13 self.headers =Login.headers14
15
16 defstation_name_code(self):17 """
18 功能:获取每个站点的名字和对应的代码,并保存到本地19 :return: 无20 """
21 filename = 'station_name.txt'
22
23 url = 'https://kyfw.12306.cn/otn/resources/js/framework/station_name.js'
24 resp = self.session.get(url, headers=self.headers)25 if resp.status_code == 200:26 print('station_name_code():获取站点信息成功!')27 with open(filename, 'w') as f:28 for each in resp.text.split('=')[1].split('@'):29 if each != "'":30 f.write(each)31 f.write('\n')32 else:33 print('station_name_code() error! status_code:{}, url: {}'
34 .format(resp.status_code, resp.url))35
36 defsave_station_code(self, filename):37 """
38 功能:从站点文件中提取站点与其对应的代码,并保存到文件中39 :return:40 """
41
42 if notos.path.exists(filename):43 print('save_station_code():',filename,'不存在,正在下载!')44 self.station_name_code()45
46 file = 'name_code.json'
47 name_code_dict ={}48 with open(filename, 'r') as f:49 for line inf:50 #对读取的行都进行split操作,然后提取站点名和其代码
51 name = line.split('|')[1] #站点名字
52 code = line.split('|')[2] #每个站点对应的代码
53 #每个站点肯定都是唯一的
54 name_code_dict[name] =code55
56 #把name,code保存到本地文件中,方便以后使用
57 with open(file, 'w') as f:58 #不以ascii码编码的方式保存
59 json.dump(name_code_dict, f, ensure_ascii=False)60
61
62 defquery_ticket(self):63 """
64 功能:查票操作65 :return: 返回查询到的所有车次信息66 """
67
68 data =self._query_prompt()69 if notdata:70 print('query_ticket() error: {}'.format(data))71 _, from_station, to_station =data.keys()72 train_date = data.get('train_date')73 from_station_code =data.get(from_station)74 to_station_code =data.get(to_station)75
76 query_param = 'leftTicketDTO.train_date={}&'\77 'leftTicketDTO.from_station={}&'\78 'leftTicketDTO.to_station={}&'\79 'purpose_codes=ADULT'\80 .format(train_date, from_station_code, to_station_code)81
82 url = 'https://kyfw.12306.cn/otn/leftTicket/queryZ?'
83
84 full_url = url +query_param85 resp = self.session.get(full_url, headers=self.headers)86 if resp.status_code == 200 and resp.url ==full_url:87 print('query_ticket() 成功!然后进行车票清理工作!')88 self._get_train_info(resp.json(), from_station, to_station)89
90 else:91 print('query_ticket() error! status_code:{}, url:{}\norigin_url:{}'
92 .format(resp.status_code, resp.url, full_url))93
94 def_get_train_info(self, text, from_station, to_station):95 """
96 功能:提取出查询到的列车信息97 :param text: 包含所有从起点站到终点站的车次信息98 :return: 返回所有车次信息99 """
100 if nottext:101 print('_query_train_info() error: text为:', text)102 #把json文件转变成字典形式
103 result =dict(text)104 #判断有无车次的标志
105 if result.get('data').get('map'):106 train_info = result.get('data').get('result')107 train_list =deque()108 for item intrain_info:109 split_item = item.split('|')110 item_dict={}111 for index, item inenumerate(split_item,0):112 print('{}:\t{}'.format(index, item))113 if split_item[11] == 'Y': #已经开始卖票了
114 item_dict['train_name'] = split_item[3] #车次名
115 item_dict['depart_time'] = split_item[8] #出发时间
116 item_dict['arrive_time'] = split_item[9] #到站时间
117 item_dict['spend_time'] = split_item[10] #经历时长
118 item_dict['wz'] = split_item[29] #无座
119 item_dict['yz'] = split_item[28] #硬座
120 item_dict['yw'] = split_item[26] #硬卧
121 item_dict['rw'] = split_item[23] #软卧
122 item_dict['td'] = split_item[32] #特等座
123 item_dict['yd'] = split_item[31] #一等座
124 item_dict['ed'] = split_item[30] #二等座
125 item_dict['dw'] = split_item[33] #动卧
126 train_list.append(item_dict)127 #无法买票的车次,有可能是已卖光,也有可能是还不开卖
128 elif split_item[0] == '':129 print('_query_train_info():车次{}的票暂时不能购买!'
130 .format(split_item[3]))131 else:132 print('_query_train_info():车次{}还未开始卖票,起售时间为:{}'
133 .format(split_item[3], split_item[1]))134 #调用方法来打印列车结果
135 self._print_train(train_list, from_station, to_station)136 else:137 print('_get_train_info() error: 从{}站到{}站有没列车!'
138 .format(from_station, to_station))139
140 def_print_train(self, train_info, from_station, to_station):141 """
142 功能:打印查询到的车次信息143 :param train_info: 提取出来的车次信息144 :return:145 """
146
147 if nottrain_info:148 print('_print_train() error: train_info是None!')149 return
150
151 print('从{}到{}还有余票的列车有:'.format(from_station, to_station))152 for item intrain_info:153 if 'G' in item['train_name']: #高铁
154 self._print_high_train_info(item)155 elif 'D' in item['train_name']: #动车
156 self._print_dong_train_info(item)157 else:158 self._print_train_info(item)159
160 def_print_high_train_info(self, item):161 """
162 功能:打印高铁车次信息163 :param item: 所有高铁车次164 :return:165 """
166 print('车次:{:4s}\t起始时间:{:4s}\t到站时间:{:4s}\t'
167 '经历时长:{:4s}\t特等座:{:4s}\t一等座:{:4s}\t二等座:{:4s}'
168 .format(item['train_name'], item['depart_time'],item['arrive_time'],169 item['spend_time'],item['td'], item['yd'], item['ed']))170
171 def_print_dong_train_info(self, item):172 """
173 功能:打印动车的车票信息174 :param item: 所有动车车次175 :return:176 """
177 print('车次:{:4s}\t起始时间:{:4s}\t到站时间:{:4s}\t'
178 '经历时长:{:4s}\t一等座:{:4s}\t二等座:{:4s}\t软卧:{:4s}\t动卧:{:4s}'
179 .format(item['train_name'], item['depart_time'], item['arrive_time'],180 item['spend_time'],item['yd'],item['ed'], item['rw'], item['dw']))181 def_print_train_info(self,item):182 """
183 功能:打印普通列出的车次信息184 :param item: 所有普通车次185 :return:186 """
187 print('车次:{:4s}\t起始时间:{:4s}\t到站时间:{:4s}\t经历时长:{:4s}\t'
188 '软卧:{:4s}\t硬卧:{:4s}\t硬座:{:4s}\t无座:{:4s}'
189 .format(item['train_name'], item['depart_time'], item['arrive_time'],190 item['spend_time'],item['rw'], item['yw'], item['yz'], item['wz']))191 def_query_prompt(self):192 """
193 功能: 与用户交互,让用户输入:出发日期,起始站和终点站并判断其正确性194 :return: 返回正确的日期,起始站和终点站195 """
196
197 time_flag, train_date =self._check_date()198 if nottime_flag:199 print('_query_prompt() error:', '乘车日期不合理,请检查!!')200 return
201 #创建有序字典,方便取值
202 query_data =OrderedDict()203 from_station = input('请输入起始站:')204 to_station = input('请输入终点站:')205
206 station_flag =True207 filename = 'name_code.json'
208 with open(filename, 'r') as f:209 data =dict(json.load(f))210 stations =data.keys()211 if from_station not in stations or to_station not instations:212 station_flag =False213 print('query_prompt() error: {}或{}不在站点列表中!!'
214 .format(from_station, to_station))215 #获取起始站和终点站的代码
216 from_station_code =data.get(from_station)217 to_station_code =data.get(to_station)218 query_data['train_date'] =train_date219 query_data[from_station] =from_station_code220 query_data[to_station] =to_station_code221
222 if time_flag andstation_flag:223 returnquery_data224 else:225 print('query_prompt() error! time_flag:{}, station_flag:{}'
226 .format(time_flag, station_flag))227
228
229
230 def_check_date(self):231 """
232 功能:检测乘车日期的正确性233 :return: 返回时间是否为标准的形式的标志234 """
235
236 #获取当前时间的时间戳
237 local_time =time.localtime()238 local_date = '{}-{}-{}'.\239 format(local_time.tm_year, local_time.tm_mon, local_time.tm_mday)240 curr_time_array = time.strptime(local_date, '%Y-%m-%d')241 curr_time_stamp =time.mktime(curr_time_array)242 #获取当前时间
243 curr_time = time.strftime('%Y-%m-%d', time.localtime(curr_time_stamp))244
245 #计算出预售时长的时间戳
246 delta_time_stamp = '2505600'
247 #算出预售票的截止日期时间戳
248 dead_time_stamp = int(curr_time_stamp) +int(delta_time_stamp)249 dead_time = time.strftime('%Y-%m-%d', time.localtime(dead_time_stamp))250 print('合理的乘车日期范围是:({})~({})'.format(curr_time, dead_time))251
252 train_date = input('请输入乘坐日期(year-month-day):')253 #把乘车日期转换成时间戳来比较
254 #先生成一个时间数组
255 time_array = time.strptime(train_date, '%Y-%m-%d')256 #把时间数组转化成时间戳
257 train_date_stamp =time.mktime(time_array)258 #获取标准的乘车日期
259 train_date_time = time.strftime('%Y-%m-%d', time.localtime(train_date_stamp))260 #做上面几步主要是把用户输入的时间格式转变成标准的格式
261 #如用户输入:2018-2-22,那么形成的查票URL就不是正确的
262 #只有是: 2018-02-22,组合的URL才是正确的!
263 #通过时间戳来比较时间的正确性
264 if int(train_date_stamp) >= int(curr_time_stamp) and\265 int(train_date_stamp) <=dead_time_stamp:266 returnTrue, train_date_time267 else:268 print('_check_date() error: 乘车日期:{}, 当前系统时间:{}, 预售时长为:{}'
269 .format(train_date_time, curr_time, dead_time))270 returnFalse, None271
272
273
274 defmain():275 filename = 'station_name.txt'
276 station =Station()277 station.station_name_code()278 station.save_station_code(filename)279 station.query_ticket()280
281 if __name__ == '__main__':282 main()
小结:在查票功能中,其实没有太多复杂的东西,不想前面登录时需要发送多个请求,在这个功能中只要发送两个请求就可以了,主要复杂的地方在于对数据的清理工作!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









