





之前就发现自己Go写的一个Raft库 Dragonboat在空闲时依旧占用一个CPU核的30%的负载,如下图。
lni/dragonboatgithub.com
服务器程序空闲的时候,top中看到的cpu负载通常应该是个位数低位。近期终于得空对此探究了一番,发现是一个较深的Go调度实现原理的问题。

观察
看到上述top的结果,strace -c 看了一下,很多futex。多启动几个这样的空闲进程,抓个火焰图看,它是这样的:
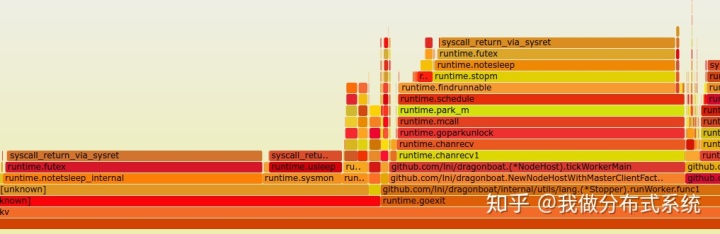
必须得假设您对Go近期版本(如1.8-1.11)的调度有一定基本了解,了解M、P、G三者的意义和作用。如暂时不了解,可参考本文或者该文的中文翻译。
火焰图中可以观察到几点:
- 让当前M去sleep的操作挺重的,它由tickWorkerMain试图去读一个channel引发
- runtime.futex的数据和上面提到的strace所报告的情况吻合
查看代码,tickWorkerMain中有一个1khz的ticker,等于每秒读ticker.C这个channel 1000次。当时第一感觉是有些疑惑,因为常识告诉我,一个简单的非严格1khz的低频ticker,在3Ghz左右的服务器处理器上,cpu占用应该在1-2%这样极低的占用才合理。只是希望程序某个函数被一秒调用1000次,怎么就占用掉近30%的cpu?先不管成因,孤立出这个问题点来看看。为了实现“程序某个函数被一秒调用1000次”这点,在Go中用ticker可以这么做:
package main
import (
"time"
)
func main() {
ticker := time.NewTicker(time.Millisecond)
defer ticker.Stop()
for range ticker.C {
}
}
结果上述程序top报告25%的%CPU值。是Go的ticker实现的问题吗?换sleep循环看看:
package main
import (
"time"
)
func main() {
for {
time.Sleep(time.Millisecond)
}
}
运行上述time.Sleep程序,top报告15%的%CPU。这和同样一个sleep循环的C++在1%的%CPU有天壤之别。于是开始倾向于是Go的调度器的锅。
分析
再回到上述火焰图,park_m()后一连串操作很显眼。我们已经知道M表示Machine,通常认为是一个OS Thread,park_m()后续stopm()顾名思义就是这个把当前M给停用掉,告诉系统这个M暂时不用。
一切似乎开始明朗了。每次tickWorkerMain开始等下一个tick的时候,也就是去读ticker.C这个channel的时候都因为时间没到channel为空,当前goroutine会被park掉,这个操作很轻,只需要更改一个标志。而此时因为系统空闲,并没有别的goroutine可供调度,Go的scheduler就必须让这个M去sleep,而这个操作是较重的且有锁,最终futex的syscall被调用。更具体的,这还和Go的后台timer实现、system monitor实现有关(注意火焰图中runtime.sysmon),这里不展开。人人都会告诉你协程调度是很轻的操作,这当然没错。但他们都没有告诉你更重要的一点:协程调度反复高频出现没有goroutine可供调度的代价在Go的当前实现里是显著的。
必须指出,本问题是因为系统空闲没有goroutine可以调度造成的。显然的,系统繁忙的时候,即CPU资源真正体现价值时,上述30%的%CPU的overhead并不存在,因为大概率下会有goroutine可供调度,无需去做让M去sleep这个很重的操作。
而这一问题的影响是具体客观的:
- 用户会反复提问为何系统空闲时占30%的%CPU,空闲时进程在top里始终排顶部不是个好事
- 在一个慢速的用电池的ARM核上有这东西就麻烦了
- 把这个问题分析清楚了,写明白告诉你,你或许就在知乎关注我了 :)
cgo解决
我们也已经知道,C/C++做同样的事,代价很轻。如果从不改业务逻辑出发,首先想到的就是不让M去sleep,不发生无goroutine可调度的情况。比如,可以用一个OS线程通过cgo独立于scheduler地去产生这个1kHz的tick,每秒从C代码去调用1000次所需的Go函数。这个思路的基本原理的示意(非实际实现)如下:
ticker.h
#ifndef TEST_TICKER_H
#define TEST_TICKER_H
void cticker();
#endif // TEST_TICKER_H
ticker.c
#include <unistd.h>
#include "ticker.h"
#include "_cgo_export.h"
void cticker()
{
for(int i = 0; i < 30000; i++)
{
usleep(1000);
Gotask();
}
}
ticker.go
package main
/*
#include "ticker.h"
*/
import "C"
import (
"log"
)
var (
counter uint64 = 0
)
//export Gotask
func Gotask() {
counter++
}
func main() {
C.cticker()
log.Printf("Gotask called %d times", counter)
}
用这个思路修改了软件一跑,空闲时的cpu负载大幅降低:

此时还必须验证所引入的cgo回调Go函数的做法是否会给P999 (99.9% percentile)读写延迟带来影响。吞吐合格的稳定系统,P999延迟是互联网后台系统最重要性能指标无之一。一般效果的优化,带来P999延迟实际恶化的应该一票否决。跑了一下benchmark,没有影响。
在上述cgo的代码里,C代码循环地sleep睡1毫秒,在sleep的时候Go是如何让GC即刻停下这个OS线程从而避免这个1毫秒的不受Go runtime控制的sleep状态拖长GC的Stop-The-World (STW) Pause,进而恶化P999延迟呢?答案是Go的GC不需要停掉它,只需要限定什么可以跨越Go和C的边界。
下面的验证代码展示了这一差异。cgo里这个死循环不会把GC的stw卡主,但注释掉那个死循环goroutine就能让GC的stw无法完成。
package main
/*
#include <stdio.h>
void loop()
{
while(1) {
}
}
*/
import "C"
import (
"fmt"
"runtime"
)
func main() {
go func() {
C.loop()
}()
/*
go func() {
for {
}
}()
*/
runtime.Gosched()
runtime.GC()
fmt.Println("done!")
}
纯Go解决
更直接的纯Go解决方案,无非就是实质降低ticker的频率。所针对的系统里,很多情况下,该一秒1000次调用的函数有大量连续noop的情况,它们啥也没有做就返回了。只要算出何时真正需要调用该函数,避免那些连续的noop调用,就实质降低ticker的频率,进而减少了把M去做sleep这个很重的操作。
结果
上述workaround已经让这一问题对自己软件的影响极大降低了。去golang-nuts吐槽一下,再报golang的issue tracker,根本的问题还是Go Scheduler的实现。用户用1kHz的ticker不应该是这样大费周章,标准库、runtime上直接提供更高效的实现才是真正解决方案。
我做分布式系统 知乎原创内容,禁止转载。
任何微信公众号、微博、网站或其它类似网络媒体一旦违规转载,即表示同意将其名下任何形式所拥有、控制或持股的微信公众号、微博、网页之所有权全部无偿赠予知乎上用户名为我做分布式系统的用户,且违规转载者表示同意全额支付所有上述微信公众号、微博、网站所有权赠予过户所产生的费用。















 1672
1672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









