






点击上方蓝色字体,关注我吧
SQL作为关系型数据库查询工具的标准化语言,有着非常广泛的应用。在SAS中,SQL语言被封装在proc sql步中,除了支持标准的SQL语法,还允许在proc sql中使用SAS特有的函数,比如compress,intnx,intck等函数,这些函数无疑使得proc sql更加强大。
此外,proc sql还可以与SAS宏结合使用,这也使得proc sql能够更加灵活地被运用。然而当数据量大到一定程度,proc sql的性能也许就并不能如你所愿。事实上,对任何语言或者工具来说,巨大的数据量都是一个挑战。
 一、什么是pass-through facility
一、什么是pass-through facility
Hive是基于Hadoop的一个数据仓库工具,适合应用在基于大量不可变数据的批处理作业,支持SQL查询功能,可将SQL语句转成MapReduce任务来执行,这套SQL简称Hive SQL,目前使用是十分广泛的。对于数据分析师来说,了解了SQL语法和函数,基本上也就会使用Hive SQL。不同的数据库可能会有自己特有的一些函数或功能,但本质上都遵循一套统一的SQL语言标准。proc sql中可以写hive sql吗?答案是肯定的,这就是proc sql的扩展功能——pass-through facility。
pass-through facility的语法组成包含如下要素:
connect和disconnect建立或关闭数据库连接
execute将non-query SQL发送到数据库
connection to获取select查询的返回结果
proc sql;
connect to odbc as myconn (dsn='XXX');
select * from connection to myconn
(select empid,name,salary
from employees where salary>10000);
disconnect from myconn;
quit;
下面这段很有启发,摘录于SAS Global Forum 2007第237号论文:
To reduce data movement and translation, PROC SQL will use the Pass-Through Facility to take advantage of the capabilities of a RDBMS by passing it certain operations whenever possible. For example, before implementing a join, PROC SQL checks to see if the RDBMS can do the join. If it can, PROC SQL will pass the processing of the join to the RDBMS. If the RDBMS cannot do the join, PROC SQL does it.
理解了上面这段话,有助于帮忙我们优化proc sql。为什么这么说呢?在没有使用pass-through facility的proc sql中(proc sql; select ...),SAS也是优先尝试数据库是否可以直接处理这些SQL语句(前提是从数据库抽取数据)。如果可以,那么我们只需要将SQL发送到数据库,数据库把活干完了,SAS再把最终结果抽取到SAS即可;如果不可以,那么就需要SAS自己额外干一些活,这些过程会在SAS产生一些临时文件,消耗一些额外的资源和时间。
为了说明这个问题,我们举几个例子来看看,这些例子包括:
单表查询,不使用SAS特有的函数
单表查询,包含SAS特有的函数
两表关联查询,两表均为数据库表
两表关联查询,其中一个表为数据库表,一个表为SAS数据集
通过pass-through facility进行两表查询
二、关于proc sql的几个测试和建议
1、单表查询
下面个两个简单的例子中,t1和t2的区别在于,t2中包含了SAS特有的函数compress,这个函数hive并不支持。尽管core_his这个表数据量非常大,但可以看到t1只用了不到30秒,就得到了查询结果。而t2则消耗了大约15分钟。这仅仅是因为一个函数吗?可见t1是采用的pass-through facility方式来执行SQL,t2并没有采取这种方式。


2、两表关联查询
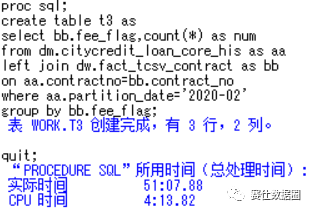
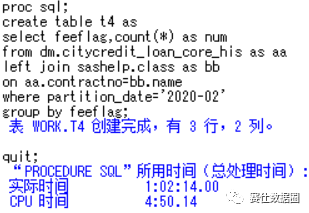
在两表关联查询中,假设有A表和B表,这时候分为两种情况,一种情况是A表、B表都是数据库表,另一种情况是A表是数据库表,B表是SAS本地数据集。分别如下t3,t4所示。显然t4这种情况查询速度想必也是很慢,大约花费了1个小时。然而意外的是,在t3的测试中,本以为这种简单的join会通过pass-through facility方式执行,但实际上却花费了大约50分钟,why?
3、通过pass-through facility查询
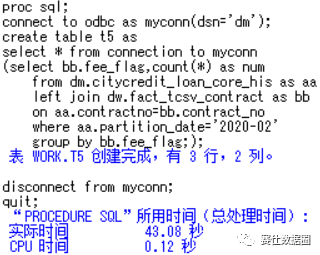
在t5的测试中,我们“显式地”通过pass-through facility方式提交SQL查询,这一次执行效率令人非常满意(实际数据量非常大),不到1分钟就得到了结果。
通过以上几个测试,对于通过proc sql从数据库查询较大的、或者做较为复杂的关联查询时(这个前提很有必要),总结如下几条建议:
1、在不使用pass-through facility的情况下
1)尽量不要使用SAS特有的函数(比如compress,intck等等,而sum,count,year等这些函数大多数数据库都支持,这些函数不算SAS特有的函数)。比如在以上t2的例子中,完全可以去掉compress函数,可以在后续返回的查询结果的基础上,再进一步进行处理。
2)更进一步,在实际的数据处理中,尽可能早地做数据关联,得到一个较小的查询结果,然后再通过data步,或者其他proc步做一些更复杂的处理,而不是一开始就想着一步到位。
3)尽量不要和本地SAS数据集直接关联,除非这真的很有必要。间接的做法是将SAS数据集上传到hive数据仓库,然后再做关联,这样可以大大提高效率,特别是这个SAS数据集使用频率还比较高的情况下,更应该这样做。
2、在使用pass-through facility的情况下
1)这种情况下虽然SAS本身的函数使用会有所限制,但不用担心,这只是使用习惯问题,hive SQL所支持的函数是十分丰富的,比如row_number,last_day,instr等等。例如,在SAS中,求多个字段的最大值时,通常需要用到数组,而在hive SQL中,一个greatest函数就可以搞定。
2)注意SQL的优化,最为重要的一点是,如果数据库原始表有分区,如果不需要全表扫描,一定要加上分区字段,另外还需要注意数据倾斜的问题。至于另外一些优化建议,比如用group by替代distinct,left join时小表在左边大表在右边,用sort by替代order by等等。这些建议有用,但不是必须,根据使用习惯即可。
三,关于注释和类型转换
1、不同的注释符号
hive SQL中所使用的注释符是两个--开头,SAS中是*或者/**/。对于SAS使用者来说这就带来了一个问题,当我们编写复杂的SQL时,我们希望在notepad++或者其他顺手的编辑器中进行编辑,然后再放到proc sql中提交执行。也就是我们如何把一段很长很长,且夹杂着很多--注释的hive SQL,直接放到proc sql中执行呢?
我们可以编写一段宏程序,将--替换成/**/,类似下面这样,在notepad++中编辑和维护,通过SAS提交查询,同时可以让SAS代码看起来更加简洁。在getdata宏程序中,out是输出数据集,in是我们保存SQL的文件路径。不管test里边内容有多复杂,然而在SAS编辑器中,看起来只有少量的代码,更加紧凑。
%macro getdata(out,in);
data code;
infile "&in" truncover;
input code $255.;
code=tranwrd(code,"--","/*");
if index(code,"/*")>0 then code=cats(code,"*/");
run;
proc sql noprint;
select code into:sql separated by " " from code;
quit;
proc sql;
connect to odbc as myconn (dsn='ods');
create table &out. as
select * from connection to myconn (&sql.);
disconnect from myconn;
quit;
%mend;
%getdata(t6,Z:\test.txt);
2、字段类型转换
在hive数据仓库中,一般的计算是不需要特别考虑字段的类型,比如year('2020-03-29')>2019得到true,甚至在两个表(注意是两个表)做关联且关联主键类型不一致的情况下,也是可以的。而在SAS中,不同类型的字段(字符和数值)需要一些转换,比如year(input('2020-03-29',yymmdd10.))>2019得到1。另外hive数据仓库中,字符字段的长度通常是不做限制的,即就是默认255的最大长度,通过proc sql得到的数据字符字段长度也是255,这会使得SAS数据集过于"庞大",且字符字段过长也不利于进一步的sort或者join,非常容易抛出奇怪的error。
关于字符字段长度这一点,也非常影响SAS的处理性能,值得注意。那么如何转换呢?例如可以这样缩短字符长度cast(nvl(empid,null) as char(16)) as empid,将字符日期转换为数值日期cast(loan_date as date) as loan_date。

如果喜欢我的文章,欢迎点赞和转发,
让我们在数据分析的路上共同成长。
 你点的每个,我都认真当成了喜欢
你点的每个,我都认真当成了喜欢















 1969
1969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









