





点击 3D Daily,关注3D最新科研动态。
翻看公众号历史记录,查看每日 arXiv 论文更新。
3D方向10篇,图模型1篇。
题目为机器翻译,仅供参考。
[1] Unsupervised Cross-Modal Alignment for Multi-Person 3D Pose Estimation
- 用于多人3D姿势估计的无监督跨模态对准[ ECCV2020]
- Indian Institute of Science: Jogendra Nath Kundu, Ambareesh Revanur, et al.
- https://arxiv.org/pdf/2008.01388.pdf
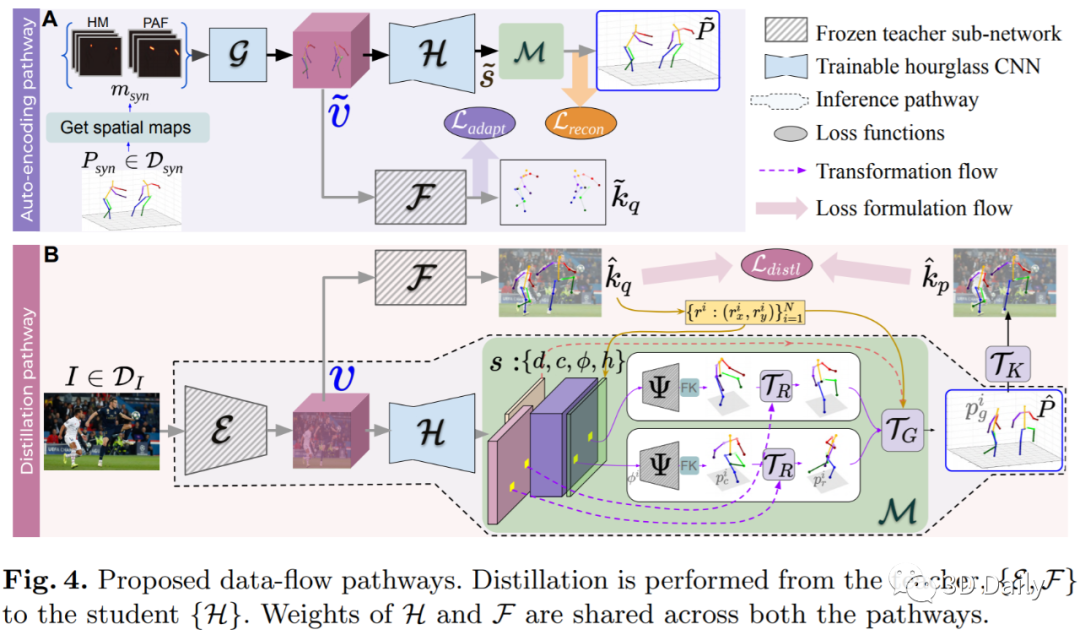
We present a deployment friendly, fast bottom-up framework for multi-person 3D human pose estimation. We adopt a novel neural representation of multi-person 3D pose which unifies the position of person instances with their corresponding 3D pose representation. This is realized by learning a generative pose embedding which not only ensures plausible 3D pose predictions, but also eliminates the usual keypoint grouping operation as employed in prior bottom-up approaches. Further, we propose a practical deployment paradigm where paired 2D or 3D pose annotations are unavailable. In the absence of any paired supervision, we leverage a frozen network, as a teacher model, which is trained on an auxiliary task of multi-person 2D pose estimation. We cast the learning as a cross-modal alignment problem and propose training objectives to realize a shared latent space between two diverse modalities. We aim to enhance the model's ability to perform beyond the limiting teacher network by enriching the latent-to-3D pose mapping using artificially synthesized multi-person 3D scene samples. Our approach not only generalizes to in-the-wild images, but also yields a superior trade-off between speed and performance, compared to prior top-down approaches. Our approach also yields state-of-the-art multi-person 3D pose estimation performance among the bottom-up approaches under consistent supervision levels.
[2] Recognition and 3D Localization of Pedestrian Actions from Monocular Video
- 单眼视频对行人动作的识别和3D定位[IEEE(ITSC)2020]
- Honda Research Institute: Jun Hayakawa, Behzad Dariush.
- https://arxiv.org/pdf/2008.01162.pdf
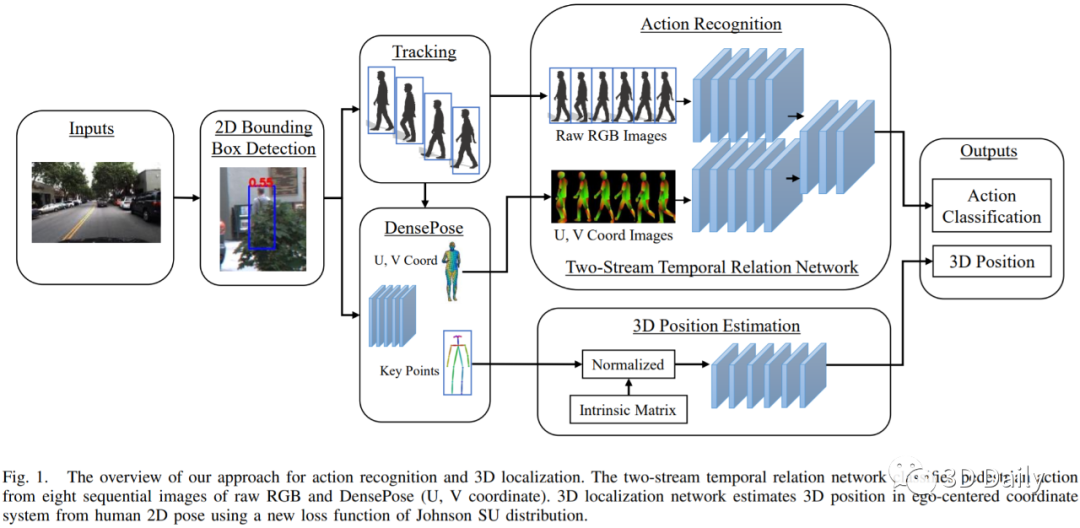
Understanding and predicting pedestrian behavior is an important and challenging area of research for realizing safe and effective navigation strategies in automated and advanced driver assistance technologies in urban scenes. This paper focuses on monocular pedestrian action recognition and 3D localization from an egocentric view for the purpose of predicting intention and forecasting future trajectory. A challenge in addressing this problem in urban traffic scenes is attributed to the unpredictable behavior of pedestrians, whereby actions and intentions are constantly in flux and depend on the pedestrians pose, their 3D spatial relations, and their interaction with other agents as well as with the environment. To partially address these challenges, we consider the importance of pose toward recognition and 3D localization of pedestrian actions. In particular, we propose an action recognition framework using a two-stream temporal relation network with inputs corresponding to the raw RGB image sequence of the tracked pedestrian as well as the pedestrian pose. The proposed method outperforms methods using a single-stream temporal relation network based on evaluations using the JAAD public dataset. The estimated pose and associated body key-points are also used as input to a network that estimates the 3D location of the pedestrian using a unique loss function. The evaluation of our 3D localization method on the KITTI dataset indicates the improvement of the average localization error as compared to existing state-of-the-art methods. Finally, we conduct qualitative tests of action recognition and 3D localization on HRI's H3D driving dataset.
[3] Tracking Emerges by Looking Around Static Scenes, with Neural 3D Mapping
- 通过神经3D映射通过环顾静态场景来跟踪出现
- Carnegie Mellon University: Adam W, et al.
- https://arxiv.org/pdf/2008.01295.pdf
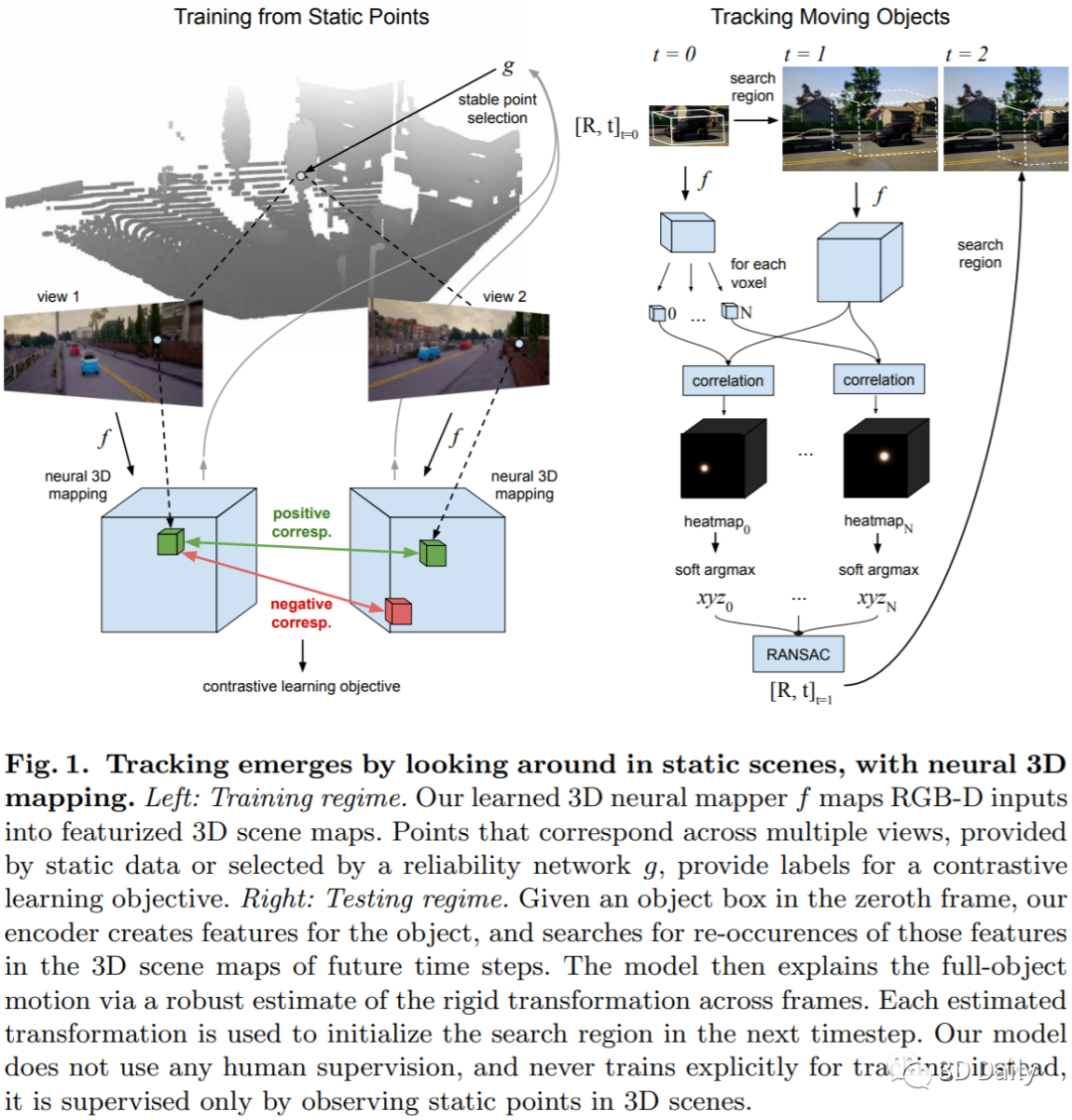
We hypothesize that an agent that can look around in static scenes can learn rich visual representations applicable to 3D object tracking in complex dynamic scenes. We are motivated in this pursuit by the fact that the physical world itself is mostly static, and multiview correspondence labels are relatively cheap to collect in static scenes, e.g., by triangulation. We propose to leverage multiview data of \textit{static points} in arbitrary scenes (static or dynamic), to learn a neural 3D mapping module which produces features that are correspondable across time. The neural 3D mapper consumes RGB-D data as input, and produces a 3D voxel grid of deep features as output. We train the voxel features to be correspondable across viewpoints, using a contrastive loss, and correspondability across time emerges automatically. At test time, given an RGB-D video with approximate camera poses, and given the 3D box of an object to track, we track the target object by generating a map of each timestep and locating the object's features within each map. In contrast to models that represent video streams in 2D or 2.5D, our model's 3D scene representation is disentangled from projection artifacts, is stable under camera motion, and is robust to partial occlusions. We test the proposed architectures in challenging simulated and real data, and show that our unsupervised 3D object trackers outperform prior unsupervised 2D and 2.5D trackers, and approach the accuracy of supervised trackers. This work demonstrates that 3D object trackers can emerge without tracking labels, through multiview self-supervision on static data.
[4] Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition
- 具有BERT的3D CNN架构中的后期时间建模以进行动作识别
- Middle East Technical University: M. Esat Kalfaoglu, et al.
- https://arxiv.org/pdf/2008.01232.pdf
- https://github.com/artest08/LateTemporalModeling3DCNN[Codes]
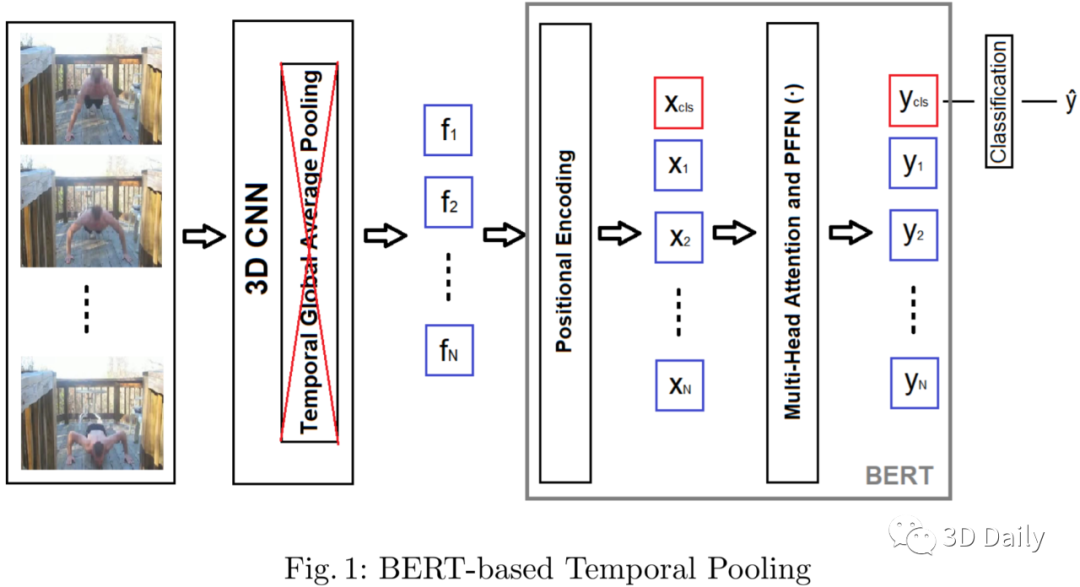
In this work, we combine 3D convolution with late temporal modeling for action recognition. For this aim, we replace the conventional Temporal Global Average Pooling (TGAP) layer at the end of 3D convolutional architecture with the Bidirectional Encoder Representations from Transformers (BERT) layer in order to better utilize the temporal information with BERT's attention mechanism. We show that this replacement improves the performances of many popular 3D convolution architectures for action recognition, including ResNeXt, I3D, SlowFast and R(2+1)D. Moreover, we provide the-state-of-the-art results on both HMDB51 and UCF101 datasets with 83.99% and 98.65% top-1 accuracy, respectively.
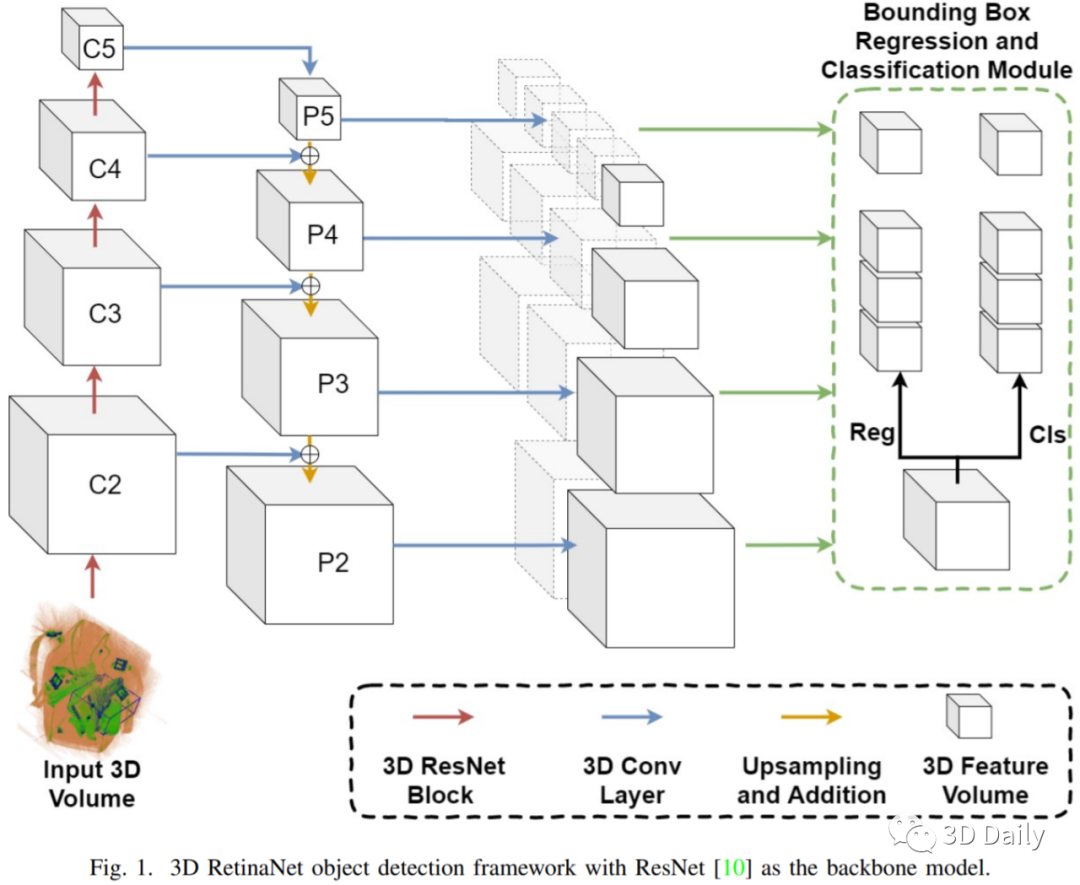
[5] Multi-Class 3D Object Detection Within Volumetric 3D Computed Tomography Baggage Security Screening Imagery
- 基于交叉和自模态的图注意力网络联合用于基于查询的矩定位
- Department of Computer Science Durham University: Qian Wang, et al.
- https://arxiv.org/pdf/2008.01403.pdf
Automatic detection of prohibited objects within passenger baggage is important for aviation security. X-ray Computed Tomography (CT) based 3D imaging is widely used in airports for aviation security screening whilst prior work on automatic prohibited item detection focus primarily on 2D X-ray imagery. These works have proven the possibility of extending deep convolutional neural networks (CNN) based automatic prohibited item detection from 2D X-ray imagery to volumetric 3D CT baggage security screening imagery. However, previous work on 3D object detection in baggage security screening imagery focused on the detection of one specific type of objects (e.g., either {\it bottles} or {\it handguns}). As a result, multiple models are needed if more than one type of prohibited item is required to be detected in practice. In this paper, we consider the detection of multiple object categories of interest using one unified framework. To this end, we formulate a more challenging multi-class 3D object detection problem within 3D CT imagery and propose a viable solution (3D RetinaNet) to tackle this problem. To enhance the performance of detection we investigate a variety of strategies including data augmentation and varying backbone networks. Experimentation carried out to provide both quantitative and qualitative evaluations of the proposed approach to multi-class 3D object detection within 3D CT baggage security screening imagery. Experimental results demonstrate the combination of the 3D RetinaNet and a series of favorable strategies can achieve a mean Average Precision (mAP) of 65.3% over five object classes (i.e. {\it bottles, handguns, binoculars, glock frames, iPods}). The overall performance is affected by the poor performance on {\it glock frames} and {\it iPods} due to the lack of data and their resemblance with the baggage clutter.
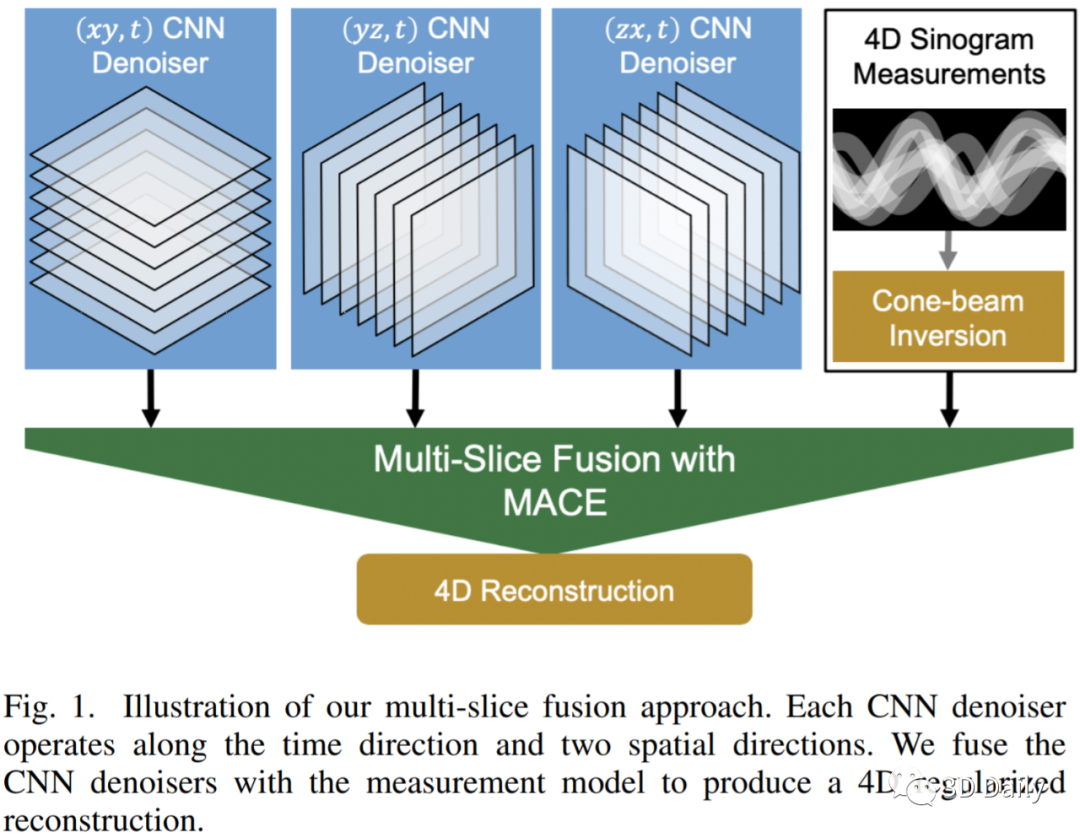
[6] Multi-Slice Fusion for Sparse-View and Limited-Angle 4D CT Reconstruction
- 用于稀疏视图和有限角度4D CT重建的多层融合
- Purdue University: Soumendu Majee, et al.
- https://arxiv.org/pdf/2008.01567.pdf
nverse problems spanning four or more dimensions such as space, time and other independent parameters have become increasingly important. State-of-the-art 4D reconstruction methods use model based iterative reconstruction (MBIR), but depend critically on the quality of the prior modeling. Recently, plug-and-play (PnP) methods have been shown to be an effective way to incorporate advanced prior models using state-of-the-art denoising algorithms. However, state-of-the-art denoisers such as BM4D and deep convolutional neural networks (CNNs) are primarily available for 2D or 3D images and extending them to higher dimensions is difficult due to algorithmic complexity and the increased difficulty of effective training. In this paper, we present multi-slice fusion, a novel algorithm for 4D reconstruction, based on the fusion of multiple low-dimensional denoisers. Our approach uses multi-agent consensus equilibrium (MACE), an extension of plug-and-play, as a framework for integrating the multiple lower-dimensional models. We apply our method to 4D cone-beam X-ray CT reconstruction for non destructive evaluation (NDE) of samples that are dynamically moving during acquisition. We implement multi-slice fusion on distributed, heterogeneous clusters in order to reconstruct large 4D volumes in reasonable time and demonstrate the inherent parallelizable nature of the algorithm. We present simulated and real experimental results on sparse-view and limited-angle CT data to demonstrate that multi-slice fusion can substantially improve the quality of reconstructions relative to traditional methods, while also being practical to implement and train.
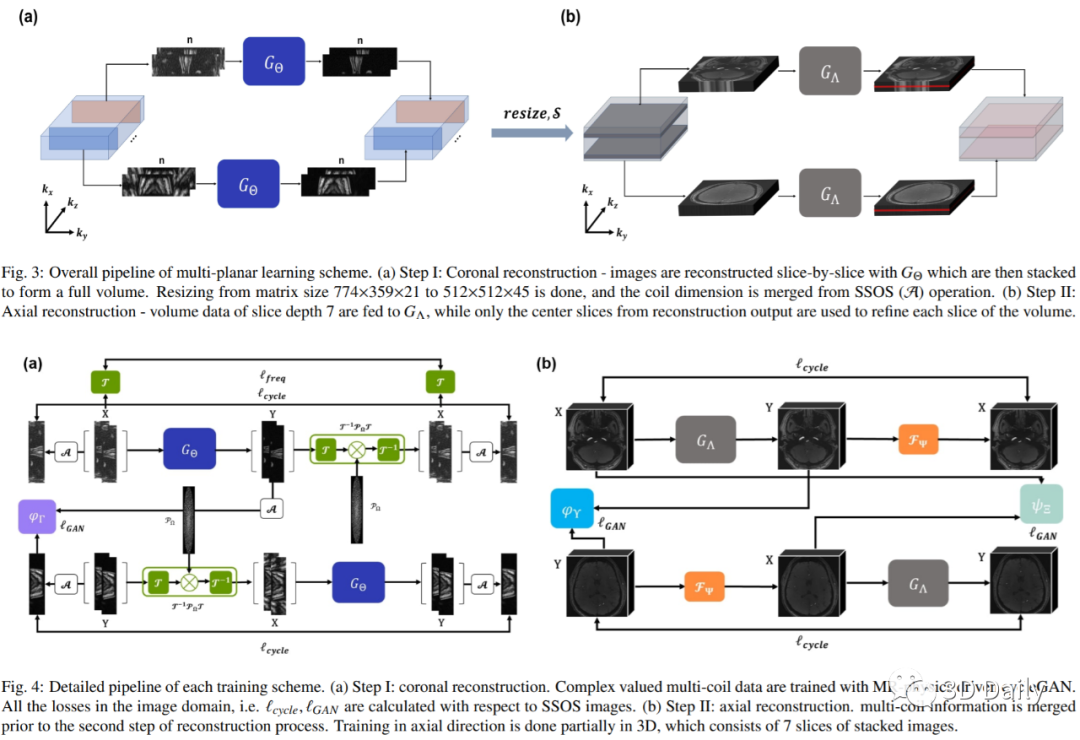
[7] Two-Stage Deep Learning for Accelerated 3D Time-of-Flight MRA without Matched Training Data
- 两阶段深度学习,无需匹配训练数据即可加速3D飞行时间MRA
- Korea Advanced Institute of Science and Technology: Hyungjin Chung, Eunju Cha, et al.
- https://arxiv.org/pdf/2008.01362.pdf
Time-of-flight magnetic resonance angiography (TOF-MRA) is one of the most widely used non-contrast MR imaging methods to visualize blood vessels, but due to the 3-D volume acquisition highly accelerated acquisition is necessary. Accordingly, high quality reconstruction from undersampled TOF-MRA is an important research topic for deep learning. However, most existing deep learning works require matched reference data for supervised training, which are often difficult to obtain. By extending the recent theoretical understanding of cycleGAN from the optimal transport theory, here we propose a novel two-stage unsupervised deep learning approach, which is composed of the multi-coil reconstruction network along the coronal plane followed by a multi-planar refinement network along the axial plane. Specifically, the first network is trained in the square-root of sum of squares (SSoS) domain to achieve high quality parallel image reconstruction, whereas the second refinement network is designed to efficiently learn the characteristics of highly-activated blood flow using double-headed max-pool discriminator. Extensive experiments demonstrate that the proposed learning process without matched reference exceeds performance of state-of-the-art compressed sensing (CS)-based method and provides comparable or even better results than supervised learning approaches.
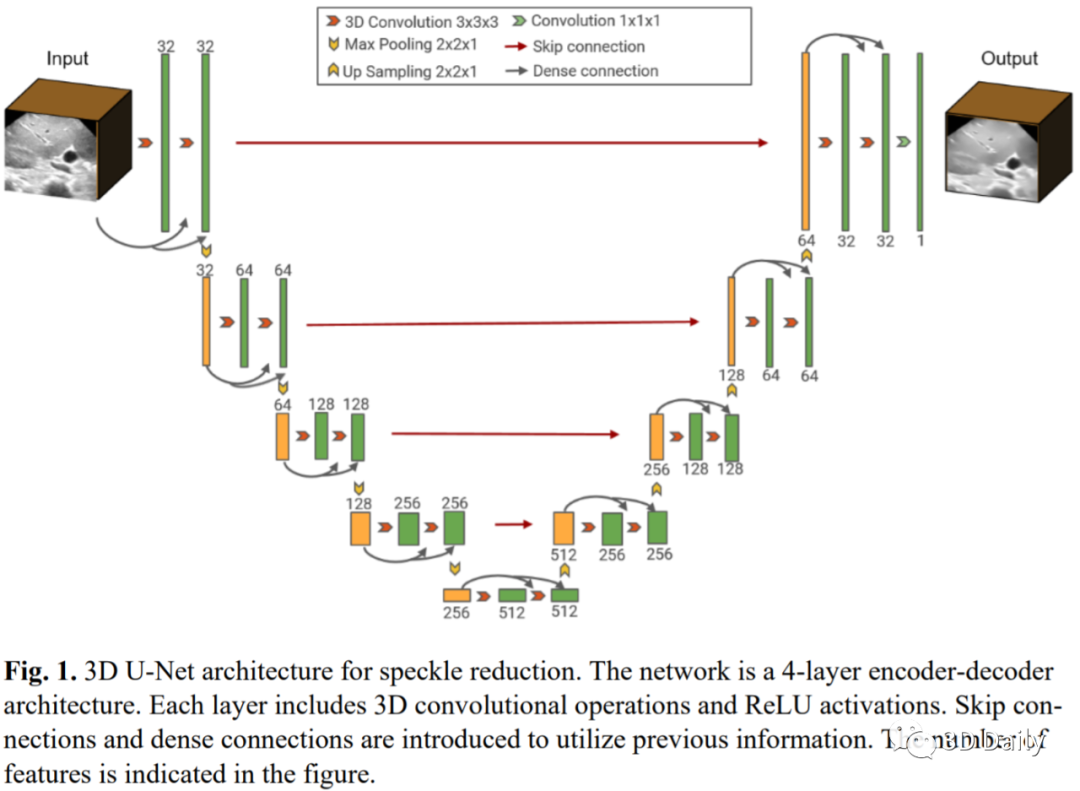
[8] 3D B-mode ultrasound speckle reduction using deep learning for 3D registration applications
- 使用深度学习进行3D注册应用的3D B模式超声斑点减少
- MedICAL laboratory: Hongliang Li, et al.
- https://arxiv.org/ftp/arxiv/papers/2008/2008.01147.pdf
Ultrasound (US) speckles are granular patterns which can impede image post-processing tasks, such as image segmentation and registration. Conventional filtering approaches are commonly used to remove US speckles, while their main drawback is long run-time in a 3D scenario. Although a few studies were conducted to remove 2D US speckles using deep learning, to our knowledge, there is no study to perform speckle reduction of 3D B-mode US using deep learning. In this study, we propose a 3D dense U-Net model to process 3D US B-mode data from a clinical US system. The model's results were applied to 3D registration. We show that our deep learning framework can obtain similar suppression and mean preservation index (1.066) on speckle reduction when compared to conventional filtering approaches (0.978), while reducing the runtime by two orders of magnitude. Moreover, it is found that the speckle reduction using our deep learning model contributes to improving the 3D registration performance. The mean square error of 3D registration on 3D data using 3D U-Net speckle reduction is reduced by half compared to that with speckles.
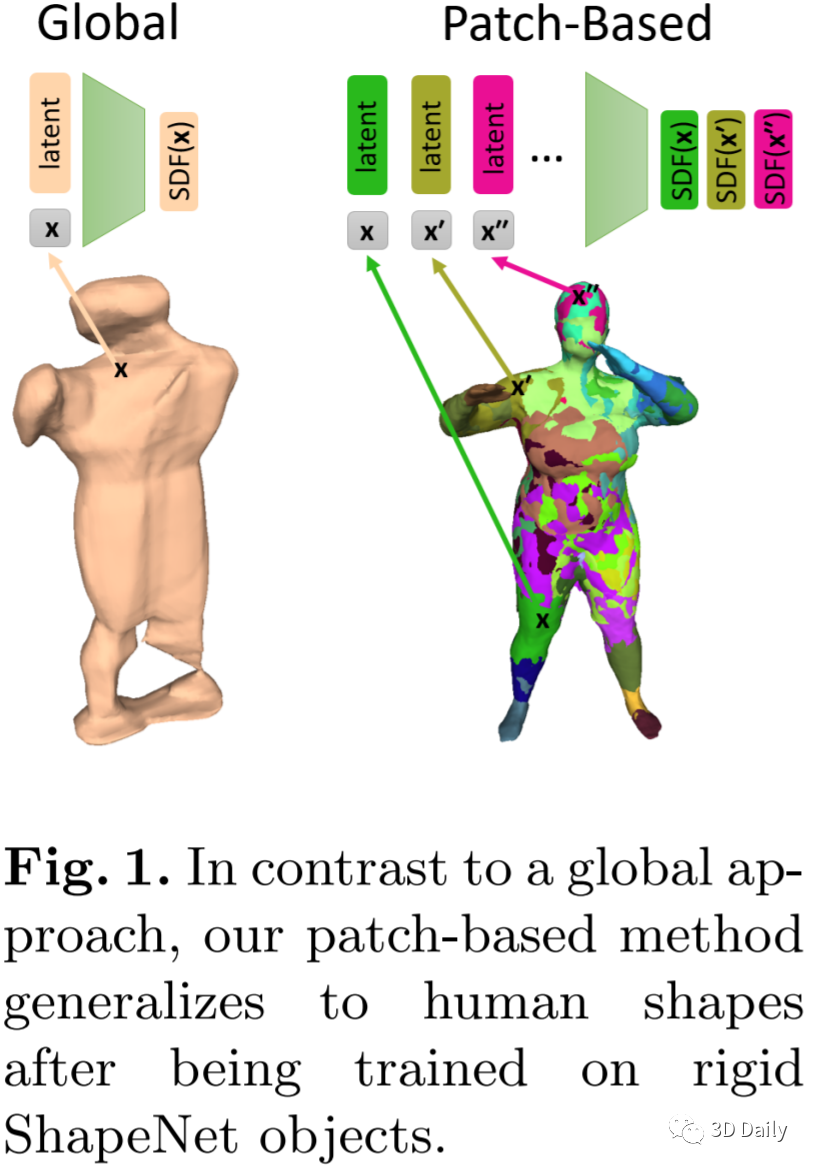
[9] PatchNets: Patch-Based Generalizable Deep Implicit 3D Shape Representations
- PatchNets:基于补丁的通用化深度隐式3D形状表示
- Max Planck Institute for Informatics: Edgar Tretschk, et al.
- https://arxiv.org/pdf/2008.01639.pdf
Implicit surface representations, such as signed-distance functions, combined with deep learning have led to impressive models which can represent detailed shapes of objects with arbitrary topology. Since a continuous function is learned, the reconstructions can also be extracted at any arbitrary resolution. However, large datasets such as ShapeNet are required to train such models. In this paper, we present a new mid-level patch-based surface representation. At the level of patches, objects across different categories share similarities, which leads to more generalizable models. We then introduce a novel method to learn this patch-based representation in a canonical space, such that it is as object-agnostic as possible. We show that our representation trained on one category of objects from ShapeNet can also well represent detailed shapes from any other category. In addition, it can be trained using much fewer shapes, compared to existing approaches. We show several applications of our new representation, including shape interpolation and partial point cloud completion. Due to explicit control over positions, orientations and scales of patches, our representation is also more controllable compared to object-level representations, which enables us to deform encoded shapes non-rigidly.
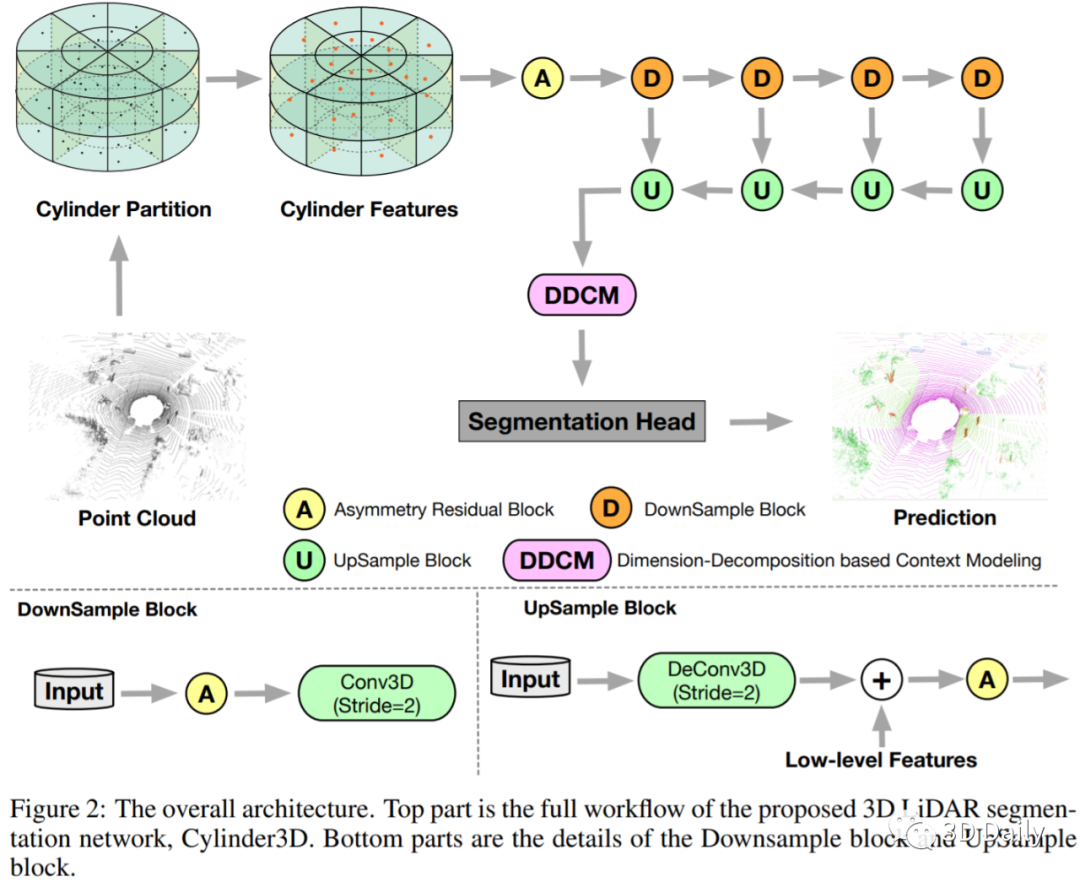
[10] Cylinder3D: An Effective 3D Framework for Driving-scene LiDAR Semantic Segmentation
- Cylinder3D:有效的3D框架,用于驾驶场景LiDAR语义分割
- The Chinese University of Hong Kong: Hui Zhou, Xinge Zhu, et al.
- https://arxiv.org/pdf/2008.01550.pdf
- https://github.com/xinge008/Cylinder3D[Codes]
State-of-the-art methods for large-scale driving-scene LiDAR semantic segmentation often project and process the point clouds in the 2D space. The projection methods includes spherical projection, bird-eye view projection, etc. Although this process makes the point cloud suitable for the 2D CNN-based networks, it inevitably alters and abandons the 3D topology and geometric relations. A straightforward solution to tackle the issue of 3D-to-2D projection is to keep the 3D representation and process the points in the 3D space. In this work, we first perform an in-depth analysis for different representations and backbones in 2D and 3D spaces, and reveal the effectiveness of 3D representations and networks on LiDAR segmentation. Then, we develop a 3D cylinder partition and a 3D cylinder convolution based framework, termed as Cylinder3D, which exploits the 3D topology relations and structures of driving-scene point clouds. Moreover, a dimension-decomposition based context modeling module is introduced to explore the high-rank context information in point clouds in a progressive manner. We evaluate the proposed model on a large-scale driving-scene dataset, i.e. SematicKITTI. Our method achieves state-of-the-art performance and outperforms existing methods by 6% in terms of mIoU.
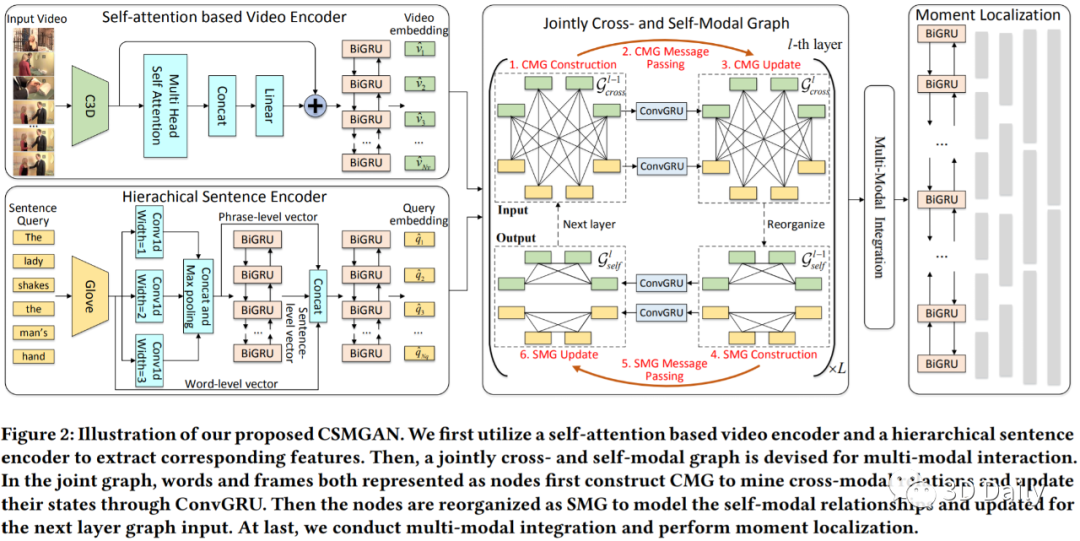
[11] Jointly Cross- and Self-Modal Graph Attention Network for Query-Based Moment Localization
- 基于交叉和自模态的图注意力网络联合用于基于查询的矩定位[ACM MM 2020]
- School of Electronic Information and Communication: Daizong Liu, Xiaoye Qu, et al.
- https://arxiv.org/pdf/2008.01403.pdf
Query-based moment localization is a new task that localizes the best matched segment in an untrimmed video according to a given sentence query. In this localization task, one should pay more attention to thoroughly mine visual and linguistic information. To this end, we propose a novel Cross- and Self-Modal Graph Attention Network (CSMGAN) that recasts this task as a process of iterative messages passing over a joint graph. Specifically, the joint graph consists of Cross-Modal interaction Graph (CMG) and Self-Modal relation Graph (SMG), where frames and words are represented as nodes, and the relations between cross- and self-modal node pairs are described by an attention mechanism. Through parametric message passing, CMG highlights relevant instances across video and sentence, and then SMG models the pairwise relation inside each modality for frame (word) correlating. With multiple layers of such a joint graph, our CSMGAN is able to effectively capture high-order interactions between two modalities, thus enabling a further precise localization. Besides, to better comprehend the contextual details in the query, we develop a hierarchical sentence encoder to enhance the query understanding. Extensive experiments on four public datasets demonstrate the effectiveness of our proposed model, and GCSMAN significantly outperforms the state-of-the-arts.
往期推荐:
- 5月下半月3D、图模型论文汇总
- 5月上半月3D、图模型论文汇总
- CVPR20 最新70+篇3D方向论文大汇总
- CVPR20 最新16篇3D分类分割论文
- CVPR20 最新11篇3D姿态估计论文
- CVPR20 最新11篇3D生成重建论文
- CVPR20 最新11篇3D人脸、图结构等论文
- CVPR20 最新10篇点云配准、3D纹理、3D数据集论文
- CVPR20 最新8篇关键点、3D布局、深度、3D表面论文
关注 3D Daily,共同创造 3D 最前沿的科技。
如果您有任何疑问、建议等,欢迎您关注公众号向我们留言,我们将第一时间答复。
每天点亮在看,打卡正在进步的一天。















 657
657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









