





正则表达式 处理字符串
工具;
. : 除换行符之外的任意一个
[u4e00-u9fa5] : 匹配汉字

[abc] : 匹配 a b c 中的任意 一 个字符

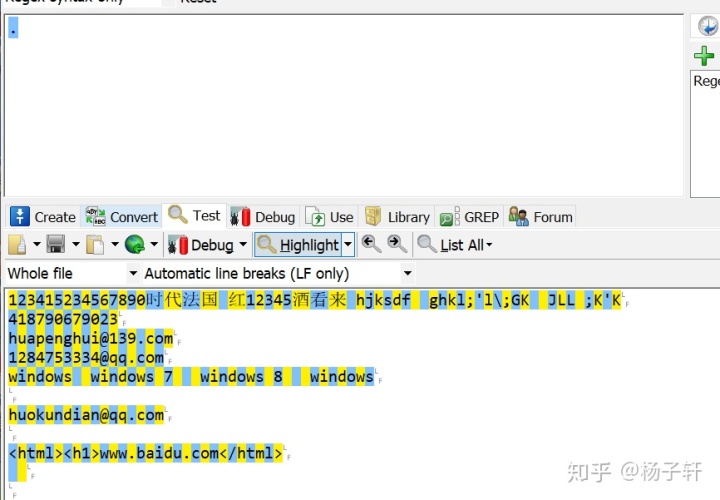
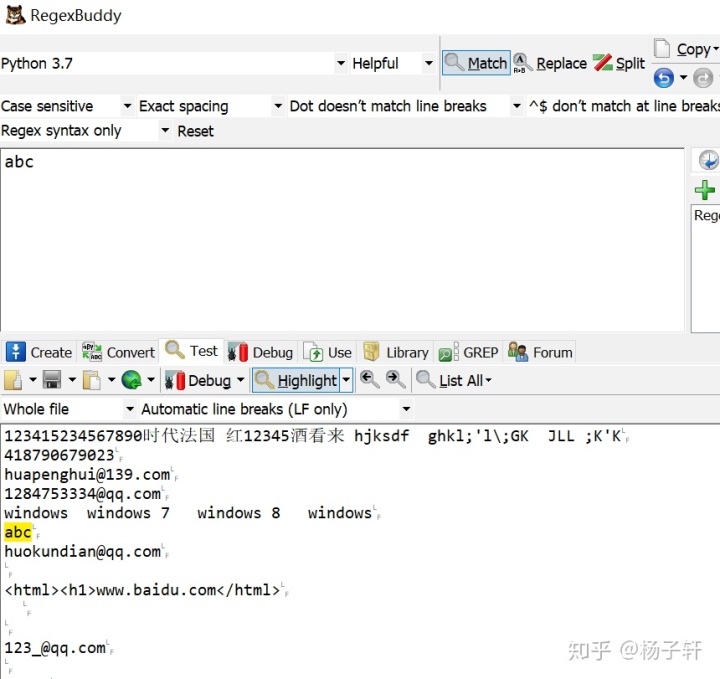
abc : 匹配abc (三个) 包含abc的字符串
匹配手机号:1[35789]d{9}

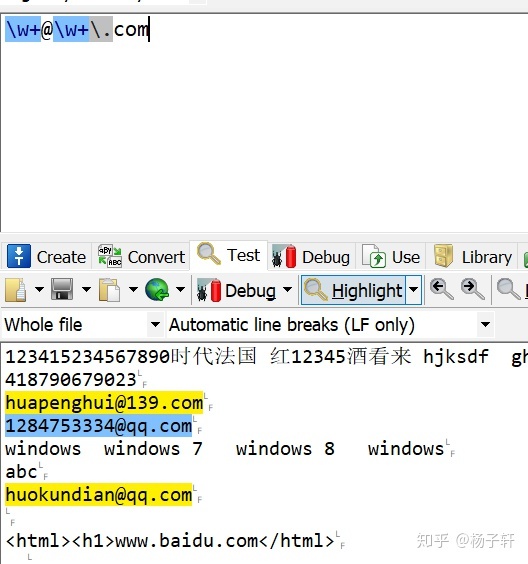
匹配邮箱:w+@w+.com
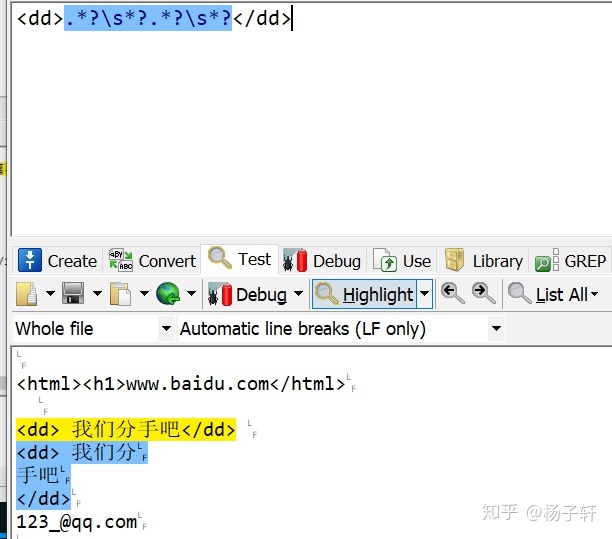
贪婪式: 匹配换行的html:<dd>(.*s*){2}</dd>

贪婪式: 匹配换行的html:<dd>(.*?s*?){2}</dd>
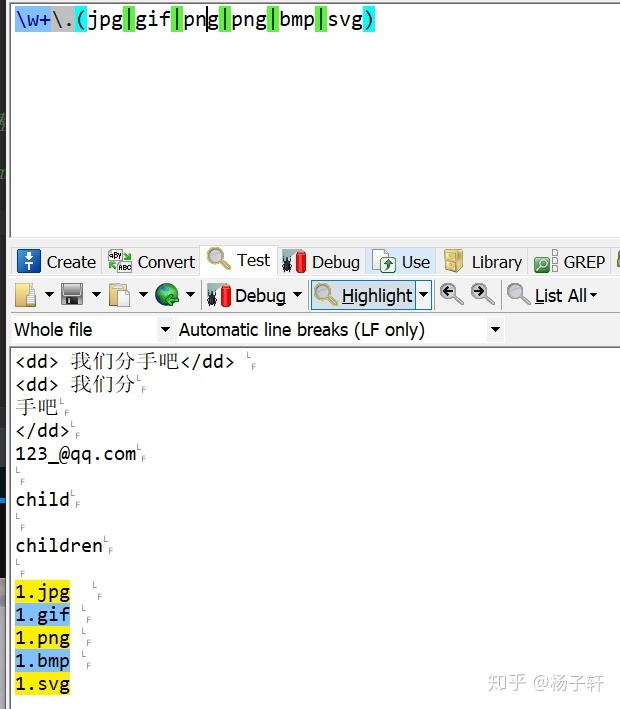
匹配图片的名字:w+.(jpg|gif|png|png|bmp|svg)
或者

"""
正则表达式的主要作用是用来处理字符串
abc : 匹配包含 abc的字符串
[abc] : 匹配a、b、c中的任意一个字符
[a-z] :匹配 a,b,c...z 中的任意一个字符
[A-Z] : 匹配 A,B,C,D....Z 中的任意一个字符
[A-Za-z]: 匹配任意一个字母
[0-9] : 匹配任意一个数字
[A-Za-z0-9]:匹配字母或数字中的任意一个字符
[^abc]: 匹配除a,b,c之外的所有字符
w : 匹配任意一个单词字母(包含字母、数字、下划线)
[a-zA-Z0-9_]
W : [^a-zA-Z0-9_]
d : [0-9]
D : [^0-9]
. : 除换行符之外的所有字符任意一个
. : 只匹配一个点
s : 匹配一个空白字符(空格、tab、换行符)
匹配多个字符的原则是 在匹配单个字符的基础上,添加如下的配置
{m, } m 代表一个数字、代表匹配的个数,代表匹配至少 m个字符
{m} m 代表一个数字、代表匹配的个数,代表匹配 m个字符
{m, n} m ,n 代表一个数字、代表匹配个数在 m-n之间,并且 n 必须 > m
贪婪式表达式: (尽可能多的去匹配能匹配到的数据)
X* : 代表X 可出现多次或0次 ===> {0, }
X+ : 代表X 至少出现一次 ====》 {1,}
X? : 代表X 出现 0-1 次 ===》 {0,1}
非贪婪式表达式:(尽可能少的去匹配能匹配到的数据)
在贪婪式表达式的基础上,添加一个特殊的符号 ?
X*? : 代表X 可出现多次或0次 ===> {0, }
X+? : 代表X 至少出现一次 ====》 {1,}
X?? : 代表X 出现 0-1 次 ===》 {0,1}
分组: 通过小括号进行操作,把某一段正则表达式作为一整体
选择: | 匹配所有的图片 jpg , gif , png , bmp , svg
.*.(jpg|gif|png|bmp|svg)
# 1、匹配手机号
1[35789]d{9}
# 2、匹配邮箱账号
# 3、匹配身份证号
# 4、匹配IP地址
限定符:
^ : 出现在正则表达式的开头,代表 以 ...开始
$ : 出现在正则表达式的结尾,代表 以...结尾
===============================================================
界定符:
?: 可以和选择 |
children , child
child(ren)?
child(?:ren)
?=pattern : 匹配和pattern一致的信息、但不包含pattern
?!
?<=
"""














 1942
1942











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









