






使用pmml和springboot部署算法模型
1. 前言
现在算法的门槛越来越低,框架封装越来越遍历,倒是算法工程化一直是老大难的问题。虽然python做模型训练是个不错的选择,但是线上环境首先就否定了python,除非是访问量不是那么大的内部调用情况,python的性能是最大的问题。工业界多年的探索的一个折中办法就是用pmml来描述模型原理,以解决模型在不同语言不同平台的移植和部署问题。虽然这是个不错的办法,因为PMML格式的通用性,所以会丧失特殊模型的特殊优化,以及特定编程语言的的某些编程技巧。例如上线XGBoost模型,也可以使用XGBoost4J,该包会链接一个本地环境编译的 .so 文件,C++实现的核心代码效率很高。不过PMML格式通用,在效率要求不高的场景可以发挥很大作用。
最近一直在探索如何使用java或go等高性能语言部署模型的问题,前不久了解了一些go,虽然go在基础设施和中间件上使用较多,性能不错,硬件消耗也小,前不久一篇文章说到知乎推荐系统的实践及重构之路,就是用go作为服务层。但是我找了一圈,也只有一个goscore库是go解析pmml文件,资料真的不多啊,难道要我用go重新实现一遍算法?知乎的推荐架构应该是go和es、redis等其他组件配合,go只是作为服务层来提高系统对外服务的能力,具体的算法结构有了解情况的同学请告诉我。
对于java来说,有比较成熟的jpmml库来,配合sklearn可以很方便将python训练好的模型以及lightGBM等模型直接转换成java版本,美中不足的是,java是在耗内存,代码相对go和python真是啰嗦。
这里我们使用springboot框架部署模型提供服务。
2. 训练一个sklearn模型
这里我们训练一个很简单的skean模型,需要说明的是,数据预处理以及模型建模,如果是sklearn内建支持是都很方面导出为pmml,但是自定义的数据处理方法和模型就不行了,具体支持哪些模型呢,看这里.
# import package
import pandas as pd
from sklearn.datasets import load_iris
from sklearn2pmml.pipeline import PMMLPipeline
from sklearn2pmml import sklearn2pmml
from sklearn.linear_model import LogisticRegression
# generate dataset
data = load_iris()
x = pd.DataFrame(data.data, columns=['slength','swidth','plength','pwidth'])
y = pd.DataFrame(data.target, columns=['y'])
# create pipeline and train
lr = LogisticRegression()
pipeline = PMMLPipeline([ ('lr', lr) ])
pipeline.fit(X=x, y=y)
pipeline.verify(x.sample(n = 15))
# export to pmml file
sklearn2pmml(pipeline, r'E:code_javatestpmml.pmml', with_repr=True)3. maven项目
接下来我们新建一个maven项目,到springboot官网下载一个springboot项目,springboot版本选择2.1.1,group写pmmldemo,Artifact写pmml,然后点击generate project下载。
将下载的zip解压后导入到intellij IDEA,如果已经配置好maven的话会自动下载相关依赖jar,很方便,如果需要添加其他依赖,只需要在在项目目录的pom.xml中添加即可。
由于我们这里只是一个demo,为方便,这里将所有的java类放放在pmmlsrcmainjavapmmldemopmml下面,不再区分domain、service、controller这些概念,在实际项目中根据代码结构区分即可。
4. pmml解析预测类
在pom.xml中添加如下依赖,jpmml是java解析pmml的类库,fastjson是阿里巴巴开源的解析json是类库,org.glassfish.jaxb是jpmml依赖的一个类库,以前是标准类库,后来被移除了,要求手动添加。
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator</artifactId>
<version>1.4.5</version>
</dependency>
<dependency>
<groupId>org.jpmml</groupId>
<artifactId>pmml-evaluator-extension</artifactId>
<version>1.4.5</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.54</version>
</dependency>
<dependency>
<groupId>org.glassfish.jaxb</groupId>
<artifactId>jaxb-runtime</artifactId>
<version>2.3.0</version>
</dependency>新建一个PmmlPredict.java类,要做的只有两件事,1是在springboot启动时加载pmml并初始化模型,2是定义一个预测函数,方便http调用,然后返回预测值。
package pmmldemo.pmml;
import com.alibaba.fastjson.JSONObject;
import org.dmg.pmml.FieldName;
import org.jpmml.evaluator.*;
import org.xml.sax.SAXException;
import javax.xml.bind.JAXBException;
import java.io.File;
import java.io.IOException;
import java.util.Arrays;
import java.util.LinkedHashMap;
import java.util.List;
import java.util.Map;
public class PmmlPredict {
//将模型定义为全局变量,springboot启动时加载pmml并初始化
public static Evaluator evaluator;
//模型初始化方法,springboot启动时执行该方法,然后初始化上面的Evaluator
public static void initModel() throws IOException, SAXException, JAXBException {
File file = new File("E:/code_java/testpmml.pmml");
evaluator = new LoadingModelEvaluatorBuilder()
.load(file)
.build();
evaluator.verify();
}
//定义一个实用函数,就是python中的print函数,没别的意思
public static void print(Object... args){
Arrays.stream(args).forEach(System.out::print);
System.out.println("");
}
// 定义预测函数,htt请求该函数,然后返回预测值
// 传入的参数是一个json,字段要求和模型的字段保持一致
public static Integer predict(JSONObject feature){
// 获取模型定义的特征
List<? extends InputField> inputFields = evaluator.getInputFields();
print("模型的特征是:", inputFields);
// 获取模型定义的目标名称
List<? extends TargetField> targetFields = evaluator.getTargetFields();
print("目标字段是:",targetFields);
// 示例传进来的json数据
// String json = "{"slength": 1.0, "swidth": 1.0, "plength": 1.0, "pwidth": 1.0}";
// JSONObject feature = JSONObject.parseObject(json);
// 好,下面将json转成evaluator要求的map格式,其实就是对key和value再做一层包装而已
Map<FieldName, FieldValue> arguments = new LinkedHashMap<>();
for(InputField inputField: inputFields){
FieldName inputName = inputField.getName();
String name = inputName.getValue();
Object rawValue = feature.getDoubleValue(name);
FieldValue inputValue = inputField.prepare(rawValue);
arguments.put(inputName, inputValue);
}
// 得到特征数据后就是预测了
Map<FieldName, ?> results = evaluator.evaluate(arguments);
Map<String, ?> resultRecord = EvaluatorUtil.decode(results);
Integer y = (Integer) resultRecord.get("y");
// 打印结果会更加了解其中的封装过程
print("预测结果:");
print(results);
print(resultRecord);
print(y);
return y;
}
}5. 初始化模型的类
上面说了,要在springboot启动的时候初始化模型,所以需要另外写一个初始化的类,新建InitializingModel.java类,内容如下:
package pmmldemo.pmml;
import com.alibaba.fastjson.JSONObject;
import org.springframework.web.bind.annotation.*;
@RestController
public class Controller {
// 定义index页,也是为了测试网络是否通畅
@RequestMapping("/")
public String index(){
return "hello spring for test";
}
// 定义一个接口,从http中接受RequestBody中的字符串,这是一个json的字符串,用fastjson解析成json后
// 直接调用预测函数PmmlPredict.predict进行预测额
@RequestMapping(value= "/predict", method = RequestMethod.POST, produces = "application/json;charset=UTF-8")
public @ResponseBody String getModel(@RequestBody String feature){
// 将字符串解析成json
JSONObject json = JSONObject.parseObject(feature);
// 预测
double y = PmmlPredict.predict(json);
// 返回
return String.valueOf(y);
}
}发现不能识别RestController,是因为缺少依赖,在pom中添加如下依赖即可。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>6. 启动
经过前面的准备,下面我们启动web服务,然后测试下是否可行。在IDEA中运行pmmldemo.pmml.PmmlApplication.java,这是整个springboot的入口,启动情况如下,默认监听端口是8080.
. ____ _ __ _ _
/ / ___'_ __ _ _(_)_ __ __ _
( ( )___ | '_ | '_| | '_ / _` |
/ ___)| |_)| | | | | || (_| | ) ) ) )
' |____| .__|_| |_|_| |___, | / / / /
=========|_|==============|___/=/_/_/_/
:: Spring Boot :: (v2.1.1.RELEASE)
2018-12-31 15:40:14.591 INFO 2744 --- [ main] pmmldemo.pmml.PmmlApplication : Starting PmmlApplication on suzhenyu-ai with PID 2744 (E:code_javapmmltargetclasses started by suzhenyu-ai in E:banggood_javapmml)
2018-12-31 15:40:14.591 INFO 2744 --- [ main] pmmldemo.pmml.PmmlApplication : No active profile set, falling back to default profiles: default
2018-12-31 15:40:16.890 INFO 2744 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat initialized with port(s): 8080 (http)
2018-12-31 15:40:16.906 INFO 2744 --- [ main] o.apache.catalina.core.StandardService : Starting service [Tomcat]
2018-12-31 15:40:16.906 INFO 2744 --- [ main] org.apache.catalina.core.StandardEngine : Starting Servlet Engine: Apache Tomcat/9.0.13
2018-12-31 15:40:16.922 INFO 2744 --- [ main] o.a.catalina.core.AprLifecycleListener : The APR based Apache Tomcat Native library which allows optimal performance in production environments was not found on the java.library.path: [C:Javajdk-11.0.1bin;C:WindowsSunJavabin;C:Windowssystem32;C:Windows;C:Windowssystem32;C:Windows;C:WindowsSystem32Wbem;C:WindowsSystem32WindowsPowerShellv1.0;C:WindowsSystem32OpenSSH;C:Gobin;C:scalabin;C:Userssuzhenyu-aiAppDataLocalMicrosoftWindowsApps;D:Anaconda3;D:Anaconda3Scripts;C:Userssuzhenyu-aiAppDataLocalProgramsMicrosoft VS Codebin;C:Userssuzhenyu-aigobin;C:Userssuzhenyu-aiAppDataLocalAtlassianSourceTreegit_local;C:Javajdk-11.0.1bin;;.]
2018-12-31 15:40:17.103 INFO 2744 --- [ main] o.a.c.c.C.[Tomcat].[localhost].[/] : Initializing Spring embedded WebApplicationContext
2018-12-31 15:40:17.103 INFO 2744 --- [ main] o.s.web.context.ContextLoader : Root WebApplicationContext: initialization completed in 2308 ms
2018-12-31 15:40:17.352 INFO 2744 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2018-12-31 15:40:17.581 INFO 2744 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path ''
2018-12-31 15:40:17.581 INFO 2744 --- [ main] pmmldemo.pmml.PmmlApplication : Started PmmlApplication in 3.571 seconds (JVM running for 4.316)
模型初始化成功...使用postman测试。先测试主页:
http://127.0.0.1:8080,返回hello spring for test,说明程序正常启动了。
测试预测:
http://127.0.0.1:8080/predict, 发送json数据{"slength": 1.0, "swidth": 1.0,"plength": 1.0, "pwidth": 1.0}, 返回结果:2
以下是python代码
import requests
url = 'http://127.0.0.1:8080/predict'
data = {"slength": 1.0, "swidth": 1.0,"plength": 1.0, "pwidth": 1.0}
haders = { 'Connection': 'close'}
r = requests.post(url, json=data)
print(r.text)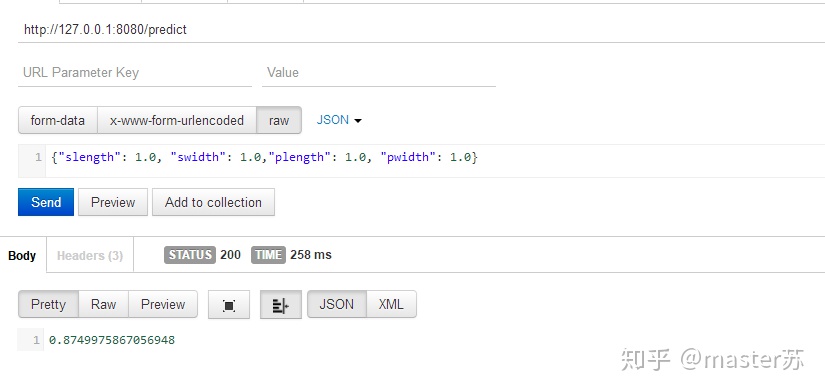
至此,整个流程就基本完成了。
7. 进一步分析PMML
查看预测函数的打印输出,如下所示,可以看到,对于分类模型,会输出各个类别的预测概率,然后返回概率最大的一个类作为预测的概率。
{"slength": 1.0, "swidth": 1.0,"plength": 1.0, "pwidth": 1.0}
模型的特征是:[
InputField{name=pwidth, displayName=null, dataType=double, opType=continuous},
InputField{name=slength, displayName=null, dataType=double, opType=continuous},
InputField{name=swidth, displayName=null, dataType=double, opType=continuous},
InputField{name=plength, displayName=null, dataType=double, opType=continuous}]
目标字段是:[TargetField{name=y, displayName=null, dataType=integer, opType=categorical}]
预测结果:
{y=ProbabilityDistribution{result=2,
probability_entries=[0=0.20617333796640616, 1=0.2465126514843382, 2=0.5473140105492555]},
probability(0)=0.20617333796640616,
probability(1)=0.2465126514843382,
probability(2)=0.5473140105492555}
{y=2, probability(0)=0.20617333796640616,
probability(1)=0.2465126514843382,
probability(2) =0.5473140105492555}8. 并发测试
下面我们来测试下并发的性能,首先将之前的print函数都注释掉,然后用python编写如下协程高并发代码:
import asyncio
from aiohttp import ClientSession
import time
async def hello():
url = 'http://127.0.0.1:8080/predict'
data = {"slength": 1.0, "swidth": 1.0,"plength": 1.0, "pwidth": 1.0}
async with ClientSession() as session:
async with session.post(url=url, json=data) as response:
response = await response.read()
# print(response)
# return None
# 设置并发数量
tasks = [asyncio.ensure_future(hello()) for _ in range(1000)]
start = time.clock()
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
end = time.clock()
print('全部请求耗时:%.4f 秒'%(end-start))并发1000耗时1.7334秒,当我尝试加大并发数量的时候,就报错aiohttp.client_exceptions.ClientConnectorError: Cannot connect to host 127.0.0.1:8080 ssl:None [Too many open files],然后尝试在linux虚拟机中测试,还是这个问题,暂时就认为这样吧。要是放到服务器上应该还能增加吧。
9. 参考
- jpmml-sklearn
- jpmml-evaluator
- PMML模型文件在机器学习的实践经验
- PMML模型文件在机器学习的实践经验
- SPRING INITIALIZR
- 构建微服务:Springboot入门篇
- alibaba/fastjson
- springboot接收json入参
- Springboot之接收json字符串的两种方式
- springboot系列文章之启动时初始化数据
- 知乎推荐系统的实践及重构之路
- Python-aiohttp百万并发
欢迎大家关注点赞















 5272
5272











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









