






第四章主要介绍数据的序列化和反序列化,以及迭代升级过程中如何保证兼容性。
分布式系统滚动升级的过程中,新旧数据与代码是同时并存的。如果出现异常,可能还需要回退程序。因此,升级过程中需要保证:
- 向后兼容(Backward compatibility):新代码要能正确读取旧数据。
- 向前兼容(Forward compatibility):旧代码要能正确读取新数据。
数据在内存中的时候是一个个“对象”(objects)。
保存到外存或通过网络传输时,得先将这个内存中的对象转换成字节流——这个过程称之为序列化(Serialization)。
反之,将字节流转换成与之对应的“对象”,这个过程叫做反序列化(Deserialization)。
常见的支持序列化和反序列化的标准或实现有:
- 文本编码:JSON、XML 等。
- 二进制编码:Protocol Buffers、Apache Thrift、Apache Avro 等。
文本编码
JSON 和 XML 的优点是,序列化的结果是可读的(human-readable)。
但是缺点也很明显,比如:
- JSON 和 XML 的字段都不支持二进制字符串。如果你需要传送一个二进制字符串,得先将其转换成 Base64。
- JSON 无法支持完成的 uint64。
- 文本编码的序列化结果体积较大。
- 文本编码的序列化和反序列化一般都比二进制编码差。
在与浏览器相关的交互中,因为 JavaScript 的原生支持,JSON 占据了绝对的优势。
而在应用后台内部,JSON 和 XML 都不是一个好选择。
二进制编码
Protobuf 和 Thrift
Protobuf 和 Thrift 的设计原理、编码规则、使用方式都非常接近。只要理解了其中一种,另外一种也就手到擒来了。
Protobuf 和 Thrift 的基本使用流程如下:
- 通过 Protobuf/Thrift 的 interface definition language(IDL)描述数据的 schema。
- 通过 Protobuf/Thrift 的代码生成工具生成相应程序设计语言的源代码。
- 在应用代码里调用这些生成的代码。
具体可以参考官方文档,这里就不多讲:
- Apache Thrift
- Protocol Buffers
实践中,Protobuf 的性能是优于 Thrift 的,具体可以参考:
- Apache Thrift vs Protocol Buffers vs Fast Buffers
- The best serialization strategy for Event Sourcing
书中举了一个简单的例子:
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}上面这个例子,JSON 序列化后长度为 66 字节,Thrift 最少需要 34 字节,Protobuf 则需要 33 字节,Avro 只需要 32 字节(不过理论上 Avro 还需要付出 schema 或 schema 版本信息的开销)。
上面的例子对应到 Protobuf 的 schema 如下:
message Person {
required string user_name = 1;
optional int64 favorite_number = 2;
repeated string interests = 3;
}对应的 Protobuf 对象序列化后如下:
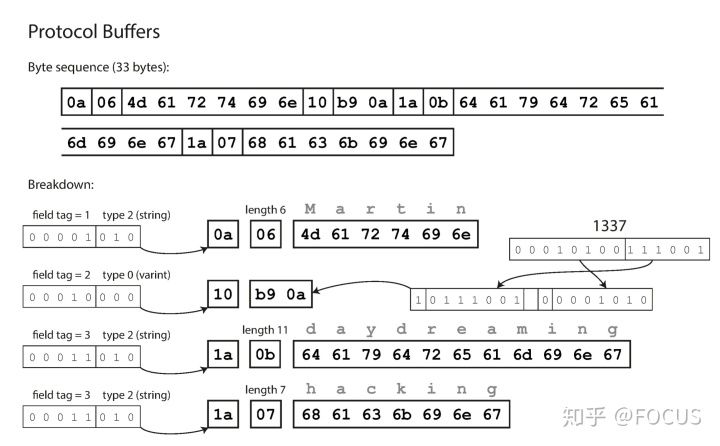
从上面的序列化结果可以看出:
- 序列化结果中没有标识
required、optional的信息,也没有必要标识。因为required是运行时的信息,只需要运行的时候根据当前的 schema 进行检查即可。实际上,required关键字在 proto3 已经被废弃了(optional关键字其实也被废弃了,所有 field 默认都是optional)。 - 每一个 field 都与一个 tag number 关联,但没有保存 field name。因此修改 field name 不影响数据的序列化和反序列化。
- 每一个 field 都有一个与之对应的类型,修改类型的时候要小心注意其兼容性。
- 只要 tag number 正确对应,field 之间的位置可以随便调整。
- 反序列化不依赖 schema。
关于 Protobuf 序列化编码的详细信息可以参考Protobuf 编码官方文档。
Avro
还是上看那个例子,对应到 Avro 的 IDL schema 为:
record Person {
string userName;
union { null, long } favoriteNumber = null;
array<string> interests;
}Avro 的 schema 还可用用 JSON 描述:
{
"type": "record",
"name": "Person",
"fields": [
{"name": "userName", "type": "string"},
{"name": "favoriteNumber", "type": ["null", "long"], "default": null},
{"name": "interests", "type": {"type": "array", "items": "string"}}
]
}IDL 描述一般用于人工编写,JSON 描述一般用于自动生成。
序列化结果如下:
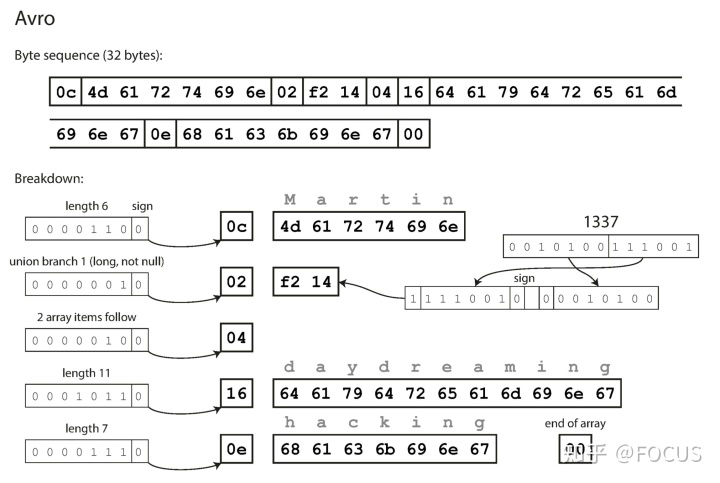
Avro 的序列化结果和 Protobuf/Thrift 的最大不同是:Avro 的序列化结果中没有保存 tag number、field name 和数据类型。因此 Avro 的反序列化依赖序列化时的 schema —— 当 avro 将序列化结果写入文件的时候,schema 或 schema 的版本也会一起保存。
关于 Avro 的更多信息,可以参考Avro 官网。
小结
- JSON 占据了浏览器数据交互的天下。
- 分布式系统内部的 RPC 交互是 Protobuf/Thrift 的主战场。实践中,建议优先考虑 Protobuf。
- Avro 我没有用过,其设计应该主要用于与 Hadoop 生态的大数据传输。
- 在我接触的范围内,XML 除了一些旧系统,已经很少使用了。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









