





实现自动化办公是许多同学学习Python的初衷,但对于有选择困难症而且基础相对薄弱的同学来讲,面对众多的教程,Python库,往往无从下手,本篇从实际应用的角度,给出一条能快速上手的学习及实操路线,以让初学者少走弯路,尽快上车。
现有Excel自动化处理方式及对比
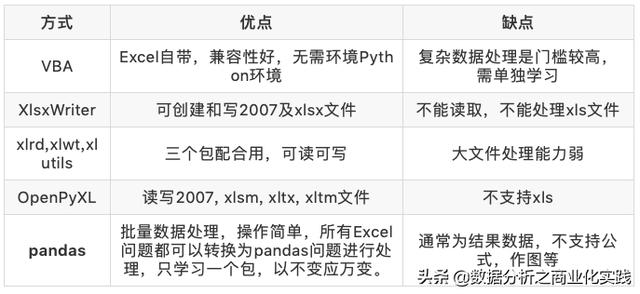
本文主要讲如何运用pandas处理Excel:
- 学习pandas使用(已经了解的同学忽略)。
- 学习read_excel和to_excel参数含义。将Excel转化为DataFrame,用pandas进行处理及输出。
pands库学习
Python数据科学,有几个包时必须掌握的,numpy处理数组矩阵计算,pandas相当于numpy的升级版,处理结构化数据,这两个包时学习其他数据处理的前提,学习资源有:廖雪峰官网,《Python数据科学》等,此处不进行过多,后面我会针对这两部分做专项讲解,同学们可后续关注更新情况。
“read_excel”参数介绍
pd.read_excel(io, sheetname=0,header=0,skiprows=None,index_col=None,names=None,arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_float=True,has_index_names=None,converters=None,dtype=None,true_values=None,false_values=None,engine=None,squeeze=False,**kwds)大家知道,每个Python库通常参数都特别多,但大家只需知道常用的就好,下面我把常用的参数给大家做了翻译:
pd.read_excel(io="路径", sheetname="工作表名",header="指定作为列名的行",skiprows="跳过头部指定行数的数据",ski_footer="跳过尾部指定行数的数据",index_col="指定索引列",names="传入列名list", usecols="要读取的列", arse_cols=None,date_parser=None,na_values=None,thousands=None, convert_float=True,has_index_names=None,converters=None,dtype=None, true_values=None,false_values=None,engine=None,squeeze=False,**kwds)示例
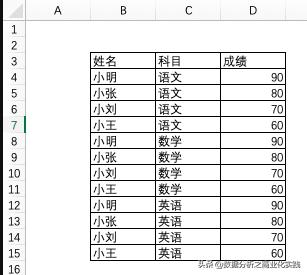
假如我们Excel中有两个工作表,表1:“科目”,表2:“等级”,现在要把等级根据成绩匹配值表1.

1.读取数据
读取数据时要指定好工作表名称,表头位置,否则会导致数据读取不准确。比如仅指定工作表名:
import pandas as pddata_kemu = pd.read_excel('Test.xlsx',sheet_name="科目" ,header=2,usecols=['姓名','科目','成绩'])data_kemu结果如下,因为表内数据并非顶格开始的,所以需要加入更多参数。
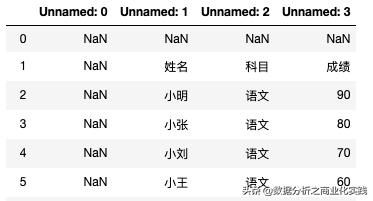
data_kemu = pd.read_excel('Test.xlsx',sheet_name="科目" ,header=2,usecols=['姓名','科目','成绩'])data_kemu输出结果正常,所以在Excel文件读取时,通常要指定出工作表名,起始行,所需列等信息:
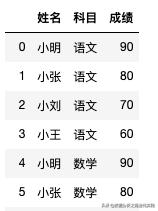
2.数据匹配merge
data_kemu = pd.read_excel('/Users/liuhongxing/Desktop/Test.xlsx',sheet_name="科目",header=2,usecols=['姓名','科目','成绩'])data_dengji = pd.read_excel('/Users/liuhongxing/Desktop/Test.xlsx',sheet_name="等级",header=2,usecols=['等级','成绩'])data = pd.merge(data_kemu,data_dengji,how='left',on='成绩')data.head()输出结果,与预期一致,此处采用了常用的函数merge,来处理不同表间数据融合的问题。
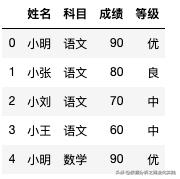
3.存储导出
“to_excel”参数介绍
导出虽然有较多参数,但我们通常已经在数据处理过程中处理成了我们想要的样子,所以此处需要用到的参数通常较少,通常为表名,缺失值填充,是否含index等,其它维持默认即可。
df.to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None,columns=None, header=True, index=True, index_label=None,startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None,inf_rep='inf', verbose=True, freeze_panes=None)参数解释:
df.to_excel(目标路径, sheet_name="工作表名", na_rep="缺失值填充", float_format="数据格式",columns=“哪些列存储”, header=“是否含表头”, index=“是否含index,默认有”, index_label=None,startrow=“起始行”, startcol=“起始列”, engine=None, merge_cells=True, encoding=“编码方式”,inf_rep='inf', verbose=True, freeze_panes=None)导出示例:
data.to_excel('Data.xlsx',sheet_name="汇总",index=False)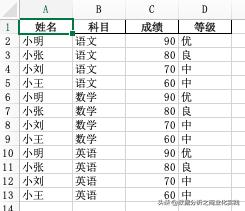
结语
本文侧重讲解了运用pandas对Excel表进行读入和输出的两个常用函数read_excel和to_excel,在这个基础上,将一切Excel问题转化为pandas问题,从而实现Excel的快速批量处理,实现真正意义上的办公自动化。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









