





MySQL 的索引长什么样子?索引到底是怎么加速查询的?
执行 create index 语句的时候之前,MySQL 就已经创建索引了。
了解这其中的原理,先从建表的时候说起。
聚簇索引
先创建一张表

试着插入5条数据

在语句执行插入过程中,MySQL 会默认使用id为主键,id是递增主键,维护起一棵 B+树,我用了旧金山大学做的 BPlusTree Visualization 来模拟这棵树的样子,主键从 先1 开始递增,而后插入五条数据,所以主键是1 到 5:

如果有能力的话,推荐你到这个网站去,从 1 到 5,一个一个插入,你会看到 B+树在插入的过程中是怎么维护它的几个特性的:
你能直观的看到:
- 有序:左边节点比右边小
- 自平衡:左右两边数量趋于相等
- 节点分裂:节点在遇到元素数量超过节点容量时,是如何分裂成两个的,这个也是 MySQL 页分裂的原理
- ……
MySQL中的大多数索引都是B+树。此外,在少数情况下,其它索引会使用 Hash索引、RR-tree等。今天,本文只讨论B+树。
仿真工具只支持插入一个值,因此除了主键之外,你看不到其他数据。然而这个B+树的叶子节点包含了该行的所有数据,所以我自己画了一幅完整的图:
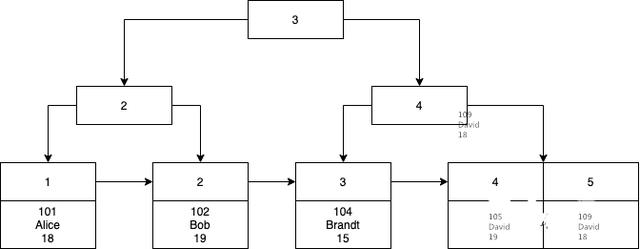
如果没有B+树,则需要根据主键进行查询,如
select * from student where id = 5;
你只能全表扫描,犹如海底捞针,如果数据量是海量效率慢到能把你整崩溃。
有朋友会说设置的主键不是递增的吗,那就直接用二分法来查找?不是的,主键虽然是递增的,但是如果你往磁盘写入数据时,没法去维护有序数组这样一个数据结构(比如你删掉了 4,怎么把 5 往前面放),数据在磁盘里仍然是无序的,查找时只能随缘查找,而如果你维护了有序数组这样的数据结构,其实也是建了索引,只是建了不一样的数据结构的索引罢了。
至于为什么 MySQL 选择了 B+树,而不用上面说的有序数组、hash索引等这个就涉及到很多的专业知识了。
现在有了这棵 B+树,数据存储起来是有规律的,查找 id=5,也不再海底捞针,而是变得很有章法:
- 从上到下,先找到 3,5 比它大,找右节点
- 接着找到 4,发现 5 还是比它大,继续找右节点
- 这次到达叶子节点了,叶子节点是一个递增的数组,那就用二分法,找到 id=5 的数据
要访问磁盘的次数由树中的层数决定。为了便于说明,本文给出的示例中的数据量并不是太大,因此在没有索引的情况下,性能提升的效果并不明显,但你可以自己试着提升数据量。
如果不指定主键怎么办?没关系,mysql会给你建一个rowid字段,用它来组织这棵 B+树。
无论如何,MySQL的目的只有一个,数据要按规律存储。数据是否被规律的管理起来,是数据库和文件系统区分开来的重要因素。
这个 MySQL 无论如何都会建起来,并且存储有完整行数据的索引,就叫聚簇索引(clustered index)
二级索引(secondary index)
聚簇索引只能帮助您加速主键查询,但是如果您想按名字查询呢?
对不起,看看上面这颗树,你就会知道数据不是按名字组织的,所以你只能扫描整个表。
不想扫描整张表该怎么办?只需要在“名字”字段中添加索引,以便让数据按照姓名有规律的进行组织。
create index idx_name on student(name);
这时候 MySQL 又会建一棵新的 B+树:
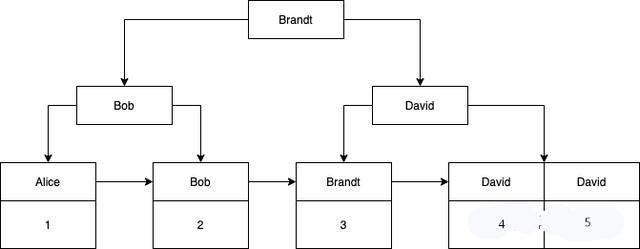
不知道你注意到这棵树的叶子节点的情况没有,它只有姓名和主键ID两个字段,而没有行的完整数据,这时候你执行:
select * from student where name = "David";
MySQL查询刚刚创建的B+树,它很快找到两个名为“David”的记录,并得到它们的主键分别是4和5,但是你要的是select *呀,怎么办?
别忘了MySQL在一开始就为您构建了一个B+树。将这两棵树放在一起,获取从这棵树中找到的两个主键id,然后转到聚簇索引里查找。问题不就解决了吗?
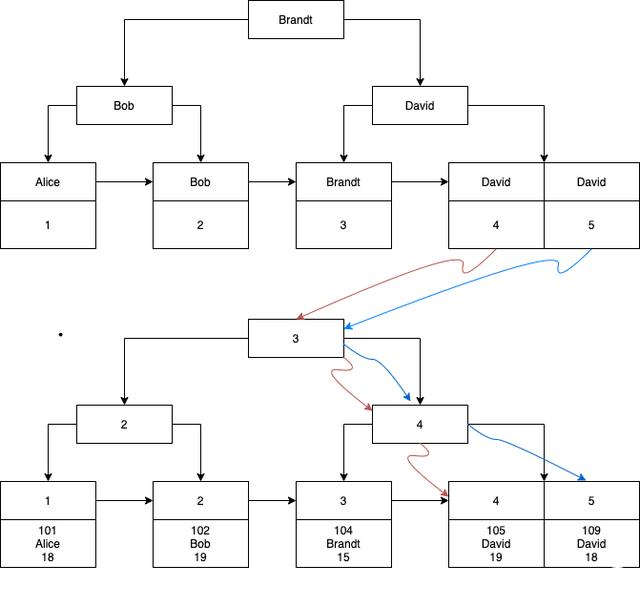
二级索引就是这个不带行数据完整信息的索引,也叫辅助索引。
复合索引
此时,如果我还想同时按姓名和年龄查找呢?
select * from student where name = "David" and age = 18;
此时,MySQL将构建一个B+树。在B+树的节点中,不仅有名称,还有年龄。
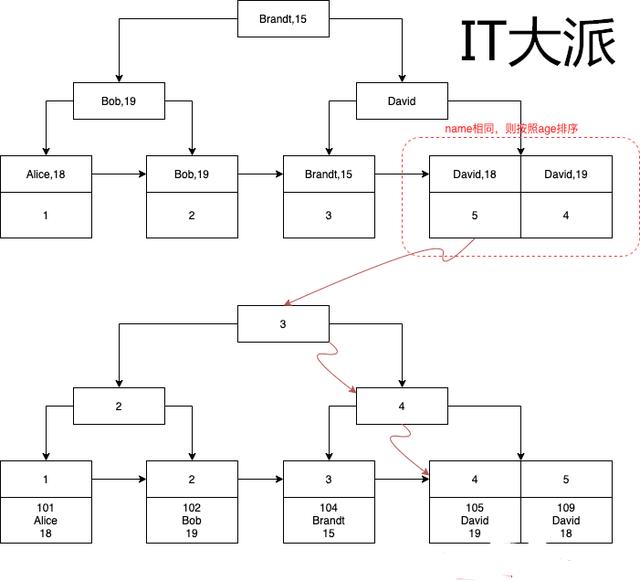
注意我使用红色虚线框的两个节点。这是这棵树和上面那棵只给 name 建索引的树的唯一区别,这两个元素换了个位置,因为在排序时,首先使用name来比较大小。如果名字相同再用age来比较。
本例子数据量实在是很小,你可以想象下有一万个叫“David”的学生,年龄被随机分布在 10 到 30 之间,如果age没有进行有规律的存储,还是一样得扫描一万行数据。
照着上面这几张图,你几乎可以推导出一切,什么样的 sql 能走索引,什么样的 sql 不能。
甚至,这么精妙的数据结构设计,难道就只能用来加快查询吗?














 1672
1672











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









