





原标题:如何在python中实现远程导入模块

需求场景
线上部署了RPC服务,项目文件结构如下图:
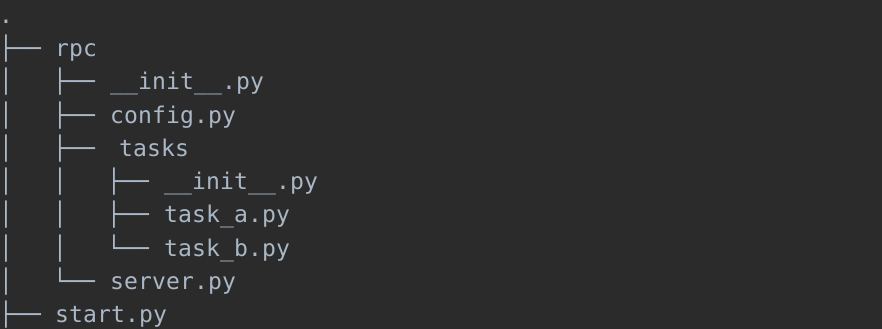
根据调用参数的不同,动态导入不同的模块,server.py中具体处理的伪代码如下:
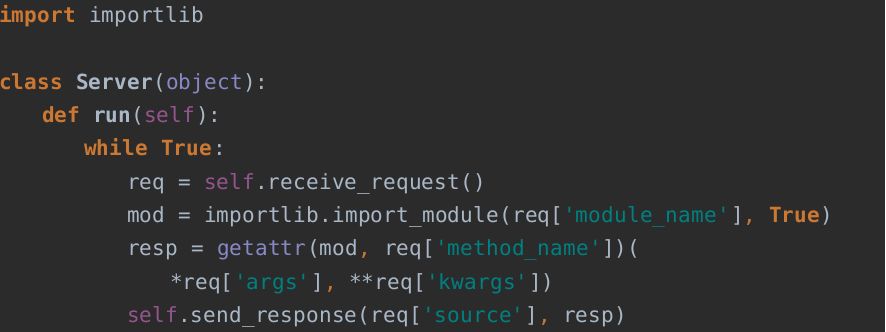
其中tasks包下每个模块分别处理一种任务,同时各模块本身也会相互import其他模块。对于在任务模块中发现中问题,要求不重启RPC服务的情况下修复更新,而项目本身会定期发版。
需求分析
Python中一个模块被导入后,再次遇到import语句导入该模块时,会直接从缓存中取出模块对象,而不是再次重新执行模块的相关语句。除非强制调用reload语句,才会重新导入。
同时,python代码运行时,会先生成pyc文件,从pyc文件进行导入,这就允许我们通过文件读写的方式,修改模块本身,然后重新触发import,导入新的pyc文件,完成模块自我更新。
上边的思路完全说的通,只是直接写文件的方式有点简单粗暴,一点也不优雅,同时reload并不能重新载入所有语句。因此,有必要研究下python的导入机制,最好实现按需导入。
跟这个需求最接近的github项目是pyspider。笔者曾经使用过该框架,其提供web管理页面,爬虫的启动控制全在网页上操作,甚至所有爬虫代码都要在浏览器窗口中编写,点击保存就将爬虫代码存储在数据库中。这个框架除了代码的调试不便之外,最大的问题是无法用版本管理系统(git)来管理爬虫代码,有时一不小心修改了代码并点击了保存,回过头来你却再也无法找到曾经修改了什么。
这个按需导入需求可以进一步细化为混合导入,即按需(动态可调)从文件系统和数据库导入代码来运行,同时还要保留版本管理。
最终,在实现定制import语句之后,修复后的模块代码依旧由git管理,同时还需要通过安全接口,将相关代码存储在数据库中。最后通知RPC更新某个模块,刷新缓存系统。再次动态导入时,避开从文件系统导入问题模块,直接从数据库导入。
为了定制import语句,我们首先要了解下python的导入过程。
导入过程
Import包含两个操作:首先搜索指定的模块,然后将查找到的结果绑定到局部作用域的模块名上。
搜索时,首先搜索缓存sys.modules。这里记录了之前已经导入的模块,包括中间模块。假如已经导入了email.mime.text这个模块,那么sys.modules这个字典中会包含以下映射关系:
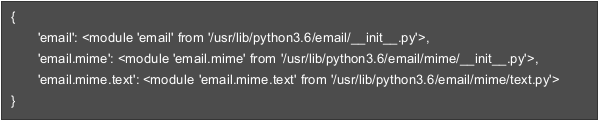
sys.modules中如果已经有了要import的模块,再次遇到import语句时会直接从缓存中取出模块对象,import完成。
如果sys.modules中没有找到所需的模块,将继续调用Python的导入协议来继续搜索。
导入协议主要包含两个概念,查找器(finders)和加载器(loaders),实现这两个概念的对象叫做导入器(importers)。
查找器的需要根据已知的策略来决定是否能够找到所需的模块。Python本身内置了很多导入器,这些导入器保存在sys.meta_path这个列表里:

第一个导入器用来查找内置模块,第二个用来查找冻结模块,第三个通过导入路径(sys.path)来查找外置模块,导入路径是一个位置的列表,这些位置可以是文件系统路径,也可以是任何可定位的资源路径,例如URL。
如果遍历完sys.meta_path中的导入器依然没有找到所需的模块的话,则会触发ImportError异常,导入失败。
因此,有两种思路可以自定义导入。一种是实现自己的元路径导入器,另一种是编写一个钩子,添加到sys.path_hooks里,识别特定的目录命名模式。
在实际需求实现过程中,笔者选择了前一种方式,但其实两者并没有太大差别。下文将详细阐释元路径导入器的实现细节。
需求实现
01
查找器实现
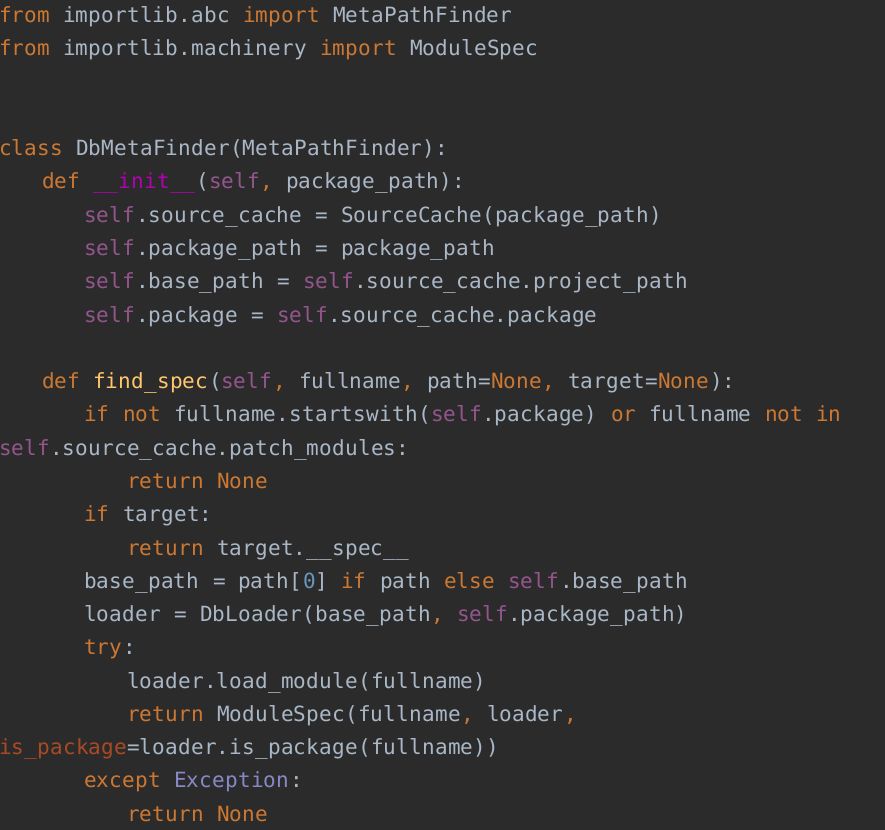
【说明】:
1. SourceCache: 需要实现全局单例缓存(后文介绍);
2. package_path:指定可以自定义导入的顶级包路径;
3. project_path: 项目目录;
4. Package: 顶级包
在python以前的版本中,找到所需模块后,查找器直接返回加载器对象本身,需要实现find_module()方法。而从python3.4开始,查找器需要返回模块说明(module spec),需要实现find_spec()方法,导入协议会根据模块说明找到相关的加载器。目前已经不推荐使用find_module()方法了,但是在没有find_spec()方法时,还会尝试find_module()方法。
find_spec()方法需要两个或者三个参数, 第一个参数fullname为模块的完整名,比如email.mime.text;第二个参数path为模块上级包的路径,对于顶级包来说,为None;第三个参数target为已经存在的模块对象,通常用在重新导入(内置的reload)时。
02
加载器实现
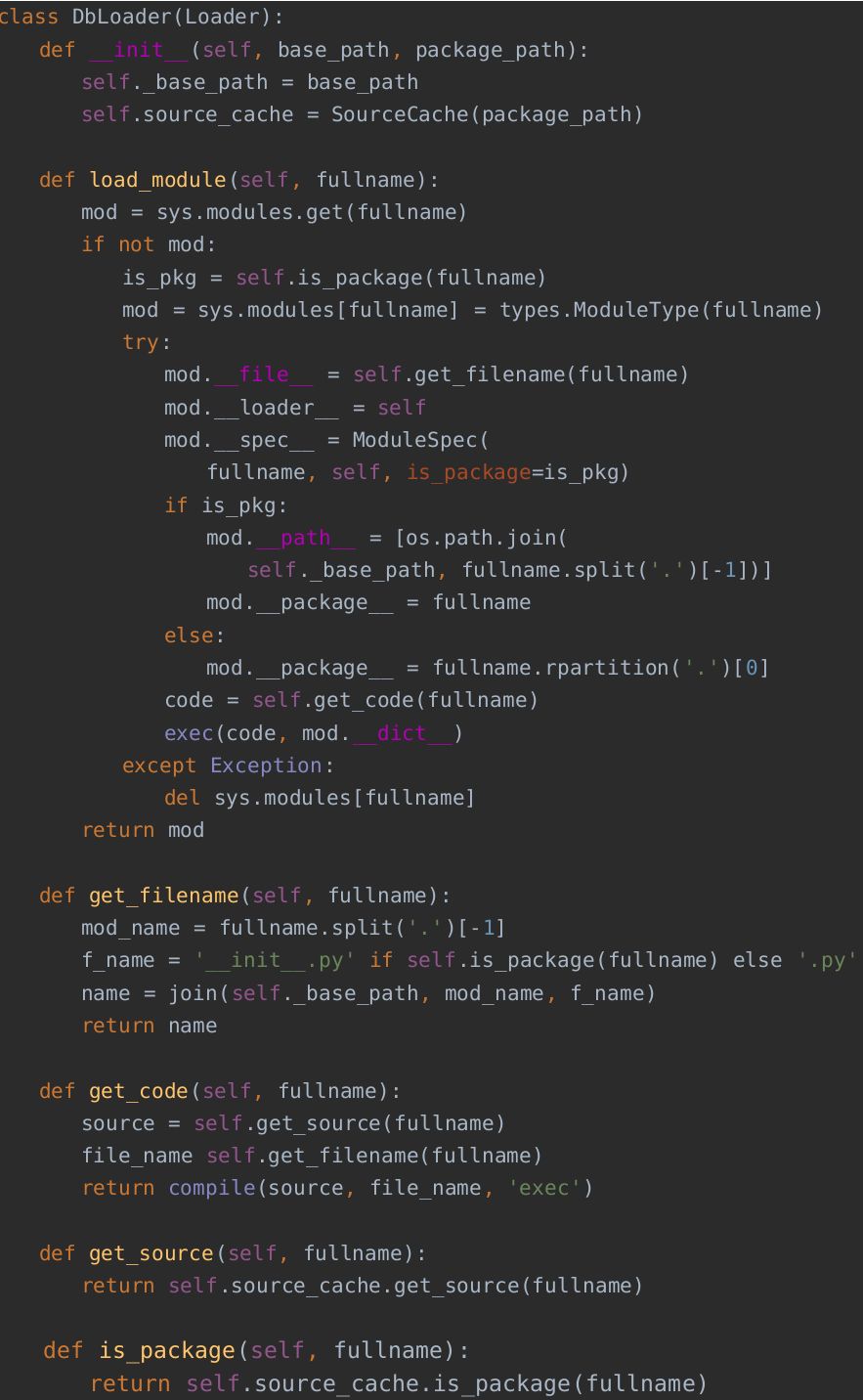
最核心的部分在于load_module()方法,其中导入关联模块属性最为重要,详细说明如下:
1. __file__: 通常为可选,当然可以不设,但是如果要支持混合导入,必须设置且跟文件系统保持一致;
2. __loader__: 通常指向加载器对象本身,模块说明会根据该属性找到具体loader;
3. __spec__: 模块说明;
4. __path__: 该属性用来标记一个模块是否是包;
5. __package__: 上级包;
加载器执行(exec)模块代码前,首先要将模块添加到sys.modules中,因为模块代码可能直接或间接导入它自身,提前添加到sys.modules中在最坏的情况下可以避免无限递归,最好的情况下可以避免多重导入。同时,导入失败时,必须保证将其从sys.modules中移除。
在以前的版本中,使用load_module()方法来加载模块。从python3.4开始,使用exec_module()方法来替代load_module(),模块的具体创建则通过调用create_module()方法来实现,并且会自动处理很多模块属性细节问题。因此,新的加载器实现细节可以删除load_module()方法,增加create_module()和exec_module()方法,源码如下:
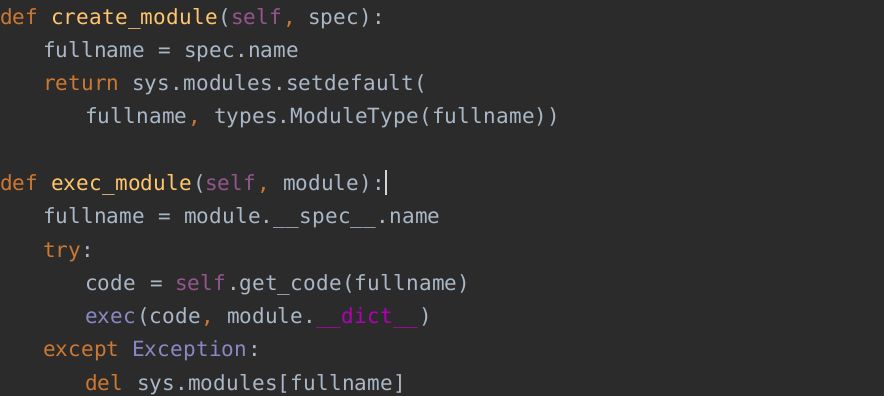
相比之前,无需再考虑很多细节,减少了工作量。
03
注册导入器
前边的导入协议中提到导入器加载分先后,一旦搜索到则返回,因此我们必须把自定义的导入器添加到PathFinder之前,才能实现优先导入数据库代码。通常直接添加到第一顺位,源码如下:

04
源码缓存
数据库中的代码通常需要一次性拉取,并在本地做缓存,避免频繁请求数据库。同时,多个模块使用同一套缓存,因此保证缓存实例为单例很有必要。Python中实现单例模式的代码很容易找到,此处限于篇幅,不做过多介绍。以单例元类Cached为例,缓存对象的相关源码如下:
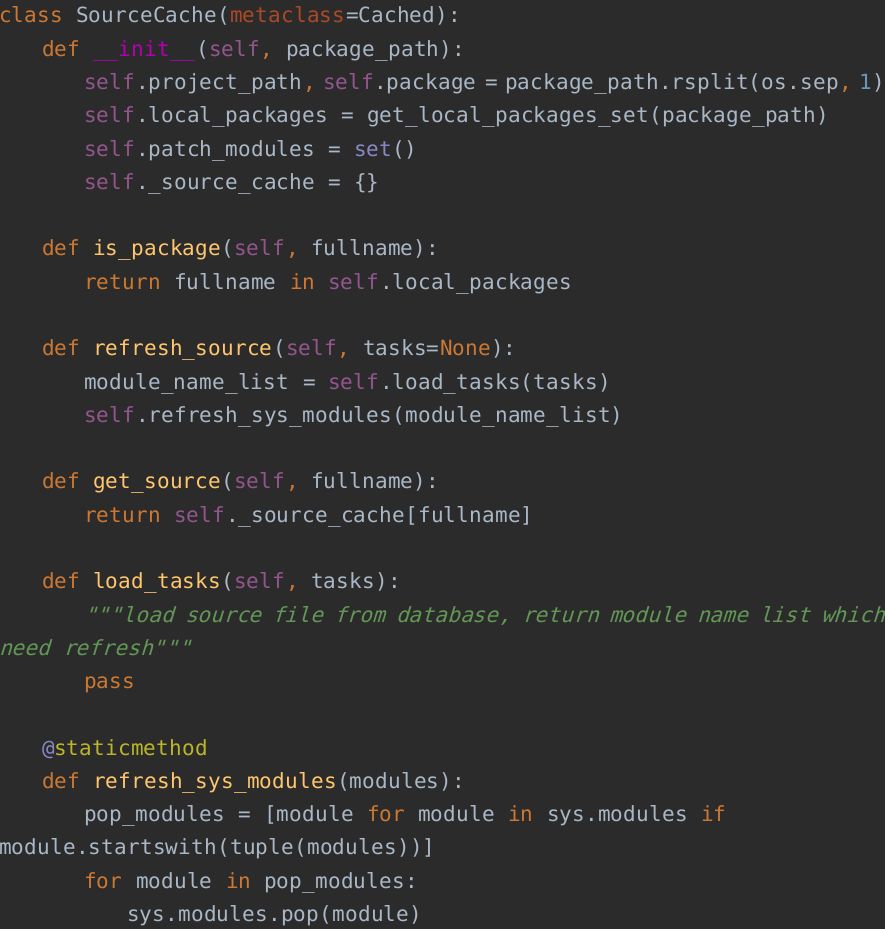
其中get_local_packages_set()方法会遍历目标包路径,记录下所有包名(包括子包)。
refresh_source()方法分成两步,load_tasks()处理从数据库中拉取代码,并更新相关缓存实例属性问题,refresh_sys_modules()处理清理sys.modules中相关模块缓存。
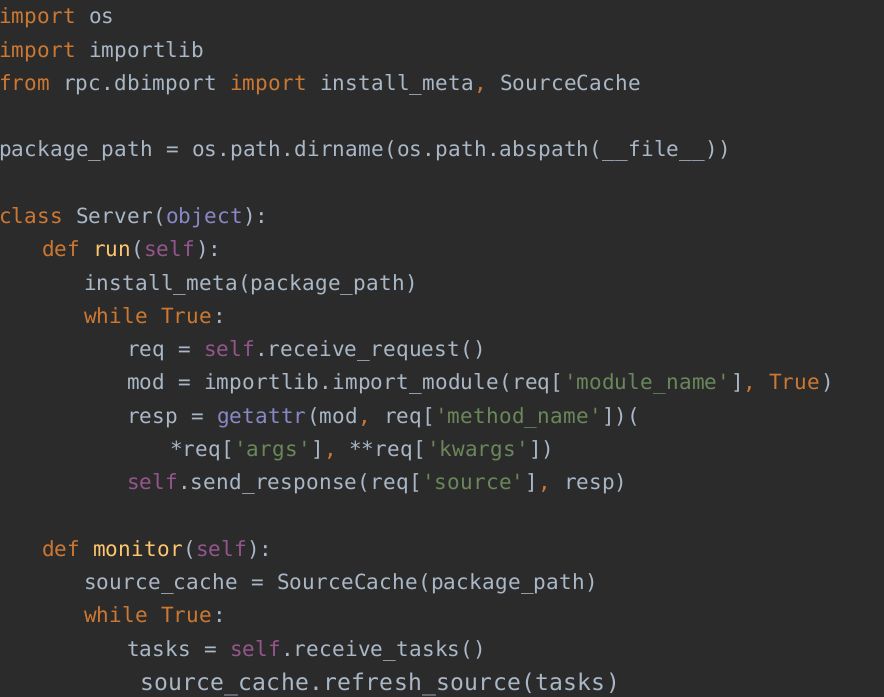
如何使用
server.py中的run()方法中添加注册导入器语句,同时增加处理通知机制的monitor()方法,完整代码如下:
小结
仅仅实现导入器,只是完成了混合导入当中最重要一环。
严格来说,一个线上系统,动态从数据库中加载代码并执行,安全问题格外重要,比如如何防止通过接口上传恶意代码,如何区分本地代码和线上代码的版本,如何处理新版本发布后的补丁问题等。
易用性问题也很重要,毕竟工具是给人使用的,过于复杂,必然难以维护,容易出错。如何自动提交补丁代码,可视化选择可用补丁代码等。
Python的模块,包和导入机制是整个语言中最复杂的部分,即使经验丰富的Python程序员也很少精通它们。真正研究下去,确实特别复杂,而且涉及了大量的细节处理,任何一点没有考虑到,都可能困扰你半天。
本文仓促成稿,为了剥离具体业务代码,又做了大量抽象处理,错误之处,还请包涵(反正你也不能来咬我是吧 ^-^)
责任编辑:















 364
364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









