





Kafka作为高吞吐的消息中间件,在消息大小为100Bytes,吞吐即可达到800kQPS,此外,Kafka的定位为流式处理平台,以下为Kafka官网的解释:
Kafka is generally used for two broad classes of applications:
- Building real-time streaming data pipelines that reliably get data between systems or applications
- Building real-time streaming applications that transform or react to the streams of data
即主要应用于流式处理平台。
Kafka的消息处理流程如下:
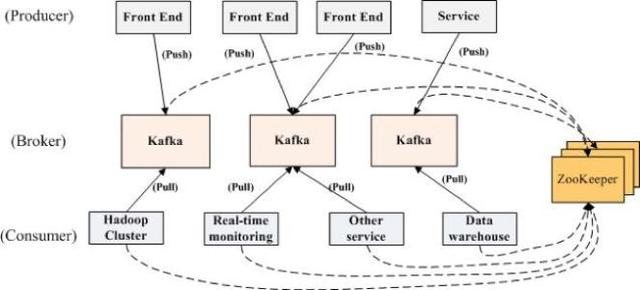
简单理解就是由生产者将消息写入topic,消费从topic拉取消息,即发布-订阅机制。
那么,如果要每天处理上万亿条消息,单节点是不够用的,我们要考虑采用分布式集群,这里讲的是伪集群,即单服务器上开多个节点。
下面开启Kafka的4个节点:9092-9095
配置比较简单,修改Kafka配置文件server.properties就可以。
vim server.properties
broker.id=1
listeners=PLAINTEXT://ip:9095
注:每个节点的broker.id与listeners不应相同,下面通过sed命令实现批量修改。
以9095实例为例:
sed -i "s/broker.id=1/broker.id=5/g" server.properties
sed -i "s/9092/9095/g" server.properties
其它节点,也要进行修改。
修改后,执行以下shell脚本以守护进程启动kafka:
vim start_kafka.sh
#!/bin/bash
for j in $(seq 9092 9095)
do
kafka-server-start.sh -daemon /usr/local/kafka/$j/config/server.properties
j=`expr $j + 1`;
done
这样,通过netstat就可惜监听到9092-9095端口了。















 938
938











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









